2023年2月1日

RISC-V 64bit Linuxとシステムコールと32bitの引数 その1 - libcの実装
目次: RISC-V
タイトルに反して実はRISC-Vはあまり関係ないですが……。GNU libcとmusl libcの実装を見ていたら、64bit環境でrebootシステムコールの引数magicに、
- 0x00000000_fee1deadを渡す派(musl libc)
- 0xffffffff_fee1deadを渡す派(GNU libc)
がいることに気づきました。
musl libcとGNU libcの実装
Cライブラリのrebootの関数宣言はint reboot(int cmd) となっています。musl libcの場合0xfee1deadをキャストせずlong型の引数に渡します。符号拡張は行われず0x00000000_fee1deadがシステムコールの引数に渡されます。
musl libcのreboot() の実装
// musl/src/linux/reboot.c
int reboot(int type)
{
return syscall(SYS_reboot, 0xfee1dead, 672274793, type);
}
// musl/arch/riscv64/syscall_arch.h
static inline long __syscall3(long n, long a, long b, long c)
{
register long a7 __asm__("a7") = n;
register long a0 __asm__("a0") = a;
register long a1 __asm__("a1") = b;
register long a2 __asm__("a2") = c;
__asm_syscall("r"(a7), "0"(a0), "r"(a1), "r"(a2))
}
一方のGNU libcの場合は、0xfee1deadをintにキャストしてからシステムコールに渡します。この値は負の数なので符号拡張が行われて0xffffffff_fee1deadがシステムコールの引数に渡されます。
GNU libcのreboot() の実装
// glibc/sysdeps/unix/sysv/linux/reboot.c
/* Call kernel with additional two arguments the syscall requires. */
int
reboot (int howto)
{
return INLINE_SYSCALL (reboot, 3, (int) 0xfee1dead, 672274793, howto);
}
// glibc/sysdeps/unix/sysv/linux/riscv/sysdep.h
# define internal_syscall3(number, arg0, arg1, arg2) \
({ \
long int _sys_result; \
long int _arg0 = (long int) (arg0); \
long int _arg1 = (long int) (arg1); \
long int _arg2 = (long int) (arg2); \
\
{ \
register long int __a7 asm ("a7") = number; \
register long int __a0 asm ("a0") = _arg0; \
register long int __a1 asm ("a1") = _arg1; \
register long int __a2 asm ("a2") = _arg2; \
__asm__ volatile ( \
"scall\n\t" \
: "+r" (__a0) \
: "r" (__a7), "r" (__a1), "r" (__a2) \
: __SYSCALL_CLOBBERS); \
_sys_result = __a0; \
} \
_sys_result; \
})
最初に気づいたときはどちらかがバグっている……?と勘違いしましたが、当たり前ですがどちらも正常に動きます。すなわちLinux側で何か対応しているはずです。続きはまた今度。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2023年2月2日
RISC-V 64bit Linuxとシステムコールと32bitの引数 その2 - Linuxの動作
目次: RISC-V
昨日の続きです。64bit Linux環境のreboot() はmagicの符号拡張をしてもしなくても正常に動くという話をしました。
この話はrebootには限らないので、もっと一般化すると「64bit環境においてシステムコールの引数がレジスタ長(= 64bit)以下だった場合(例えばintが典型例)、どう扱うか?」となります。
動作を確認するにはデバッガで追えば早いでしょう。RISC-V 64bit向けに、
- musl libcを使うツールチェーン(後述)
- GNU libcを使うツールチェーン(後述)
- linux
- busybox
- QEMU
を用意して起動します。符号拡張を行わないmusl libc版のツールチェーンでbusyboxをビルドしてQEMU起動、GDBでアタッチします。
QEMUの起動、GDBからのアタッチ
$ qemu-system-riscv64 \ -machine virt \ -net none \ -nographic \ -chardev stdio,id=con,mux=on \ -serial chardev:con -mon chardev=con,mode=readline \ -kernel linux/arch/riscv/boot/Image \ -initrd busybox/initramfs.cpio \ -s $ riscv64-unknown-linux-gnu-gdb linux/vmlinux (gdb) target remote :1234 ...
Linuxのシステムコールの実装は下記のようになります。SYSCALL_DEFINE() とはなんぞや?というところが気になると思いますが、今はひとまずシステムコール名の頭に __do_sys_ を付けた関数が定義されると理解しておけば大丈夫です。
Linuxのrebootシステムコールの実装
//linux/kernel/reboot.c
SYSCALL_DEFINE4(reboot, int, magic1, int, magic2, unsigned int, cmd,
void __user *, arg)
{
...
ブレークポイントを __do_sys_rebootに仕掛けてQEMU側のコンソールでbusybox poweroffコマンドを実行します。
__do_sys_reboot() のmagic1引数の値(符号拡張されている)
(gdb) b __do_sys_reboot
Breakpoint 1 at 0xffffffff8002d860: file kernel/reboot.c, line 702.
(gdb) c
Continuing.
Breakpoint 1, __do_sys_reboot (magic1=-18751827, magic2=672274793,
cmd=1126301404, arg=0x4321fedc) at kernel/reboot.c:702
702 {
(gdb) p/x $a0
$1 = 0xfffffffffee1dead
システムコールの引数は負の数(つまり0xffffffff_fee1dead)となっています。この関数に辿り着く前に符号拡張されるようです。
バックトレース表示
(gdb) bt
#0 __do_sys_reboot (magic1=-18751827, magic2=672274793, cmd=1126301404,
arg=0x4321fedc) at kernel/reboot.c:702
#1 0xffffffff8002dab2 in __se_sys_reboot (magic1=<optimized out>,
magic2=<optimized out>, cmd=<optimized out>, arg=<optimized out>)
at kernel/reboot.c:700
#2 0xffffffff80002fe2 in handle_exception () at arch/riscv/kernel/entry.S:231
Backtrace stopped: frame did not save the PC
バックトレースを見ると__se_sys_reboot() という関数も呼ばれています。この関数を調べるためにブレークを掛けて再度実行します。
__se_sys_reboot() のmagic1引数の値(符号拡張なし)
(gdb) b __se_sys_reboot
Breakpoint 1 at 0xffffffff8002daa0: file kernel/reboot.c, line 700.
(gdb) c
Continuing.
Breakpoint 1, __se_sys_reboot (magic1=4276215469, magic2=672274793,
cmd=1126301404, arg=1126301404) at kernel/reboot.c:700
700 SYSCALL_DEFINE4(reboot, int, magic1, int, magic2, unsigned int, cmd,
(gdb) p/x $a0
$1 = 0xfee1dead
システムコール例外ハンドラに渡ってきた引数magicはレジスタa0に入っていて、値は0xfee1deadです。__do_sys_reboot() や __se_sys_reboot() 関数を定義するSYSCALL_DEFINE() はマクロのため、デバッガから見てもソースコードが表示されません。
不思議なSYSCALL_DEFINE() マクロの仕組みは後日調べるとして、とりあえず今は逆アセンブルします。
__se_sys_reboot() の逆アセンブル
(gdb) disas Dump of assembler code for function __se_sys_reboot: => 0xffffffff8002daa0 <+0>: addi sp,sp,-16 0xffffffff8002daa2 <+2>: sd s0,0(sp) 0xffffffff8002daa4 <+4>: sd ra,8(sp) 0xffffffff8002daa6 <+6>: addi s0,sp,16 0xffffffff8002daa8 <+8>: sext.w a2,a2 ★ 0xffffffff8002daaa <+10>: sext.w a1,a1 ★ 0xffffffff8002daac <+12>: sext.w a0,a0 ★ 0xffffffff8002daae <+14>: jal ra,0xffffffff8002d860 <__do_sys_reboot> 0xffffffff8002dab2 <+18>: ld ra,8(sp) 0xffffffff8002dab4 <+20>: ld s0,0(sp) 0xffffffff8002dab6 <+22>: addi sp,sp,16 0xffffffff8002dab8 <+24>: ret
RISC-Vのアセンブラを見たことない方のために補足すると、sext.wという命令はRISC-Vの符号拡張命令です。また引数はa0, a1, a2, a3, a4, a5レジスタを経由して渡されます。すなわち __se_sys_reboot() 関数はa0, a1, a2レジスタ(引数magic1, magic2, cmdに相当)を符号拡張して __do_sys_reboot() 関数に渡しています。
ここで当初の疑問が解消しますね。疑問の内容は下記の通りで、
- magic1に0xffffffff_fee1deadを渡す派(GNU libc)→ 符号拡張するが値は変わらず
- magic1に0x00000000_fee1deadを渡す派(musl libc)→ 符号拡張して0xffffffff_fee1deadにする
答えは途中で符号拡張しているのでどちらでも問題なかった、というわけです。なるほどね。
補足: ツールチェーンの準備
ツールチェーンのビルドはcrosstool-NGなどでもできますし、面倒な場合はGitHubにUbuntu 20.04用の *.debファイルを置いたのでお使いください。
GNU libcの場合は、
- riscv64-linux-glibc-binutils.deb
- riscv64-linux-glibc-headers.deb
- riscv64-linux-glibc.deb
- riscv64-linux-glibc-gcc.deb
またmusl libcの場合は、
- riscv64-linux-musl-binutils.deb
- riscv64-linux-musl-headers.deb
- riscv64-linux-musl.deb
- riscv64-linux-musl-gcc.deb
をお使いください。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年2月3日
RISC-V 64bit Linuxとシステムコールと32bitの引数 その3 - SYSCALL_DEFINEマクロ
目次: RISC-V
昨日の続きです。「64bit環境においてシステムコールの引数がレジスタ長(= 64bit)以下だった場合(例えばintが典型例)、どう扱うか?」コードの解説編です。
どうして符号拡張されるのか?逆アセンブルで説明したつもりになってはいけない、逃げてはダメだ!という熱心なあなたのために、マクロを展開しながら説明します。今回の解説はSYSCALL_DEFINE4() たった1行です。
rebootシステムコールの実装
// linux/kernel/reboot.c
SYSCALL_DEFINE4(reboot, int, magic1, int, magic2, unsigned int, cmd,
void __user *, arg)
{
...
// linux/include/linux/syscalls.h
#define SYSCALL_DEFINE4(name, ...) SYSCALL_DEFINEx(4, _##name, __VA_ARGS__)
#define SYSCALL_DEFINEx(x, sname, ...) \
SYSCALL_METADATA(sname, x, __VA_ARGS__) \
__SYSCALL_DEFINEx(x, sname, __VA_ARGS__)
下記のように展開されます。
SYSCALL_DEFINE4() の展開結果
SYSCALL_METADATA(_reboot, 4, int, magic1, int, magic2, unsigned int, cmd, void __user *, arg)
__SYSCALL_DEFINEx(4, _reboot, int, magic1, int, magic2, unsigned int, cmd, void __user *, arg)
SYSCALL_METADATA() の方は関数の実体と無関係なので今回は無視して、__SYSCALL_DEFINEx() を見ます。
__SYSCALL_DEFINEx() マクロの実装
// linux/include/linux/syscalls.h
/*
* The asmlinkage stub is aliased to a function named __se_sys_*() which
* sign-extends 32-bit ints to longs whenever needed. The actual work is
* done within __do_sys_*().
*/
#ifndef __SYSCALL_DEFINEx
#define __SYSCALL_DEFINEx(x, name, ...) \
__diag_push(); \
__diag_ignore(GCC, 8, "-Wattribute-alias", \
"Type aliasing is used to sanitize syscall arguments");\
asmlinkage long sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)) \
__attribute__((alias(__stringify(__se_sys##name)))); \
ALLOW_ERROR_INJECTION(sys##name, ERRNO); \
static inline long __do_sys##name(__MAP(x,__SC_DECL,__VA_ARGS__));\
asmlinkage long __se_sys##name(__MAP(x,__SC_LONG,__VA_ARGS__)); \
asmlinkage long __se_sys##name(__MAP(x,__SC_LONG,__VA_ARGS__)) \
{ \
long ret = __do_sys##name(__MAP(x,__SC_CAST,__VA_ARGS__));\
__MAP(x,__SC_TEST,__VA_ARGS__); \
__PROTECT(x, ret,__MAP(x,__SC_ARGS,__VA_ARGS__)); \
return ret; \
} \
__diag_pop(); \
static inline long __do_sys##name(__MAP(x,__SC_DECL,__VA_ARGS__))
#endif /* __SYSCALL_DEFINEx */
長いマクロですね。rebootシステムコールの宣言部分 __SYSCALL_DEFINE4(reboot, ...) は下記のように展開されます。
SYSCALL_DEFINE4() の展開結果
SYSCALL_DEFINE4(reboot, int, magic1, int, magic2, unsigned int, cmd,
void __user *, arg)
↓
__diag_push();
__diag_ignore(GCC, 8, "-Wattribute-alias", "Type aliasing is used to sanitize syscall arguments");
asmlinkage long sys_reboot(__MAP(4,__SC_DECL,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg)) __attribute__((alias(__stringify(__se_sys_reboot))));
ALLOW_ERROR_INJECTION(sys_reboot, ERRNO);
static inline long __do_sys_reboot(__MAP(4,__SC_DECL,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg));
asmlinkage long __se_sys_reboot(__MAP(4,__SC_LONG,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg));
asmlinkage long __se_sys_reboot(__MAP(4,__SC_LONG,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg))
{
long ret = __do_sys_reboot(__MAP(4,__SC_CAST,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg));
__MAP(4,__SC_TEST,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg);
__PROTECT(4, ret,__MAP(4,__SC_ARGS,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg));
return ret;
}
__diag_pop();
static inline long __do_sys_reboot(__MAP(4,__SC_DECL,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg));
色々興味深い部分(__diag_push, __diag_ignore, などなど)はありますが、関数と関係ないので無視して、符号拡張を行う __se_sys_reboot() の実装部分を見ます。
SYSCALL_DEFINE4() の関数実装部分の抜粋
asmlinkage long __se_sys_reboot(__MAP(4,__SC_LONG,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg))
{
long ret = __do_sys_reboot(__MAP(4,__SC_CAST,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg));
__MAP(4,__SC_TEST,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg);
__PROTECT(4, ret,__MAP(4,__SC_ARGS,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg));
return ret;
}
この関数本体の部分がどう展開されるかを見ます。続きはまた今度。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年2月4日
RISC-V 64bit Linuxとシステムコールと32bitの引数 その4 - __MAP(), __SC_X() マクロの実装
目次: RISC-V
昨日の続きです。「64bit環境においてシステムコールの引数がレジスタ長(= 64bit)以下だった場合(例えばintが典型例)、どう扱うか?」コードの解説編です。
どうして符号拡張されるのか?逆アセンブルで説明したつもりになってはいけない、逃げてはダメだ!という熱心なあなたのために、マクロを展開しながら説明します。今回の解説は __MAP(), __SC_LONG(), __SC_CAST() マクロの意味や実装です。
任意の引数に変換を掛ける __MAP() マクロ
鍵となるのは __MAP(4, ...) の展開後に出てくる __MAP4(m, t, a, ...) というマクロです。
__MAP() マクロの実装
// linux/include/linux/syscalls.h
/*
* __MAP - apply a macro to syscall arguments
* __MAP(n, m, t1, a1, t2, a2, ..., tn, an) will expand to
* m(t1, a1), m(t2, a2), ..., m(tn, an)
* The first argument must be equal to the amount of type/name
* pairs given. Note that this list of pairs (i.e. the arguments
* of __MAP starting at the third one) is in the same format as
* for SYSCALL_DEFINE<n>/COMPAT_SYSCALL_DEFINE<n>
*/
#define __MAP0(m,...)
#define __MAP1(m,t,a,...) m(t,a)
#define __MAP2(m,t,a,...) m(t,a), __MAP1(m,__VA_ARGS__)
#define __MAP3(m,t,a,...) m(t,a), __MAP2(m,__VA_ARGS__)
#define __MAP4(m,t,a,...) m(t,a), __MAP3(m,__VA_ARGS__)
#define __MAP5(m,t,a,...) m(t,a), __MAP4(m,__VA_ARGS__)
#define __MAP6(m,t,a,...) m(t,a), __MAP5(m,__VA_ARGS__)
#define __MAP(n,...) __MAP##n(__VA_ARGS__)
マクロに渡された型tと引数aリストのペアを1つずつm(t, a) のようにmで変換を掛けるマクロですが、イメージしづらいと思うので展開結果を載せます。
__MAP() マクロの展開結果の例
__MAP(4,__SC_LONG,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg)
↓
__MAP4(__SC_LONG,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg)
↓
__SC_LONG(int, magic1),
__SC_LONG(int, magic2),
__SC_LONG(unsigned int, cmd),
__SC_LONG(void __user *, arg)
実装はぱっと見では良くわかりませんが、展開結果はわかりやすいですね。
キャストの要、__SC_LONG(), __SC_CAST() マクロ
先頭の展開結果 __SC_LONG(int, magic1) に着目します。
__SC_LONG() マクロの実装
// linux/include/linux/syscalls.h
#define __SC_LONG(t, a) __typeof(__builtin_choose_expr(__TYPE_IS_LL(t), 0LL, 0L)) a
#define __TYPE_AS(t, v) __same_type((__force t)0, v)
#define __TYPE_IS_LL(t) (__TYPE_AS(t, 0LL) || __TYPE_AS(t, 0ULL))
// linux/include/linux/compiler_types.h
#define __same_type(a, b) __builtin_types_compatible_p(typeof(a), typeof(b))
# define __force
ここまでの実装を踏まえて展開すると下記のようになります。
__SC_LONG() マクロの展開結果の例
__SC_LONG(int, magic1),
↓ __TYPE_IS_LL() を展開
__typeof(
__builtin_choose_expr(
(__same_type((int)0, 0LL) ||
__same_type((int)0, 0ULL)), 0LL, 0L))
magic1,
↓ __same_typeを展開
__typeof(
__builtin_choose_expr(
(__builtin_types_compatible_p(typeof((int)0), typeof(0LL)) ||
__builtin_types_compatible_p(typeof((int)0), typeof(0ULL))), 0LL, 0L))
magic1,
最内側の__same_type() は引数に渡した値の型を比較するマクロです。マクロで使用する __builtin_types_compatible_p() は1つ目と2つ目の型が同じかどうか?をintで返す組み込み関数、typeof() は引数の型を返すキーワードです(関数ではないので値は返しません)。
- その他の組み込み関数のマニュアル(__builtin_types_compatible_p() も載っている)
- typeofのマニュアル
従って__same_type((int)0, 0LL) はintと0LLの型、int型とlong long int型が等しいか比較しています。当然、等しくありません。ちなみにintは __SC_LONG(int, magic1) の最初の引数intから来たことを思い出していただけると嬉しいです。例えば __SC_LONG(long long, magic1) であれば比較結果は等しいと判断されるでしょう。
最内側の条件式 __same_type((int)0, 0LL) || __same_type((int)0, 0ULL)) の部分は型がlong longもしくはunsigned long longかどうか?を調べています。
判断結果を受け取る__builtin_choose_expr(const_exp, exp1, exp2) は、const_expが真なら、exp1を返し、偽ならexp2を返す組み込み関数です。もしconst_expがコンパイル時に判定できなければ、コンパイルエラーです。
以上をまとめると __SC_LONG(AAA, BBB) は、
- AAAがlong longもしくはunsigned long longならlong long BBB
- AAAがそれ以外の型ならばlong BBB
という働きをします。また __SC_CAST() はその名の通りキャストを生成します。
__SC_CAST() マクロの実装
// linux/include/linux/syscalls.h
#define __SC_CAST(t, a) (__force t) a
です。長いですね。続きはまた今度。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年2月5日
RISC-V 64bit Linuxとシステムコールと32bitの引数 その5 - __MAP(), __SC_X() マクロの展開
目次: RISC-V
昨日の続きです。「64bit環境においてシステムコールの引数がレジスタ長(= 64bit)以下だった場合(例えばintが典型例)、どう扱うか?」コードの解説編です。
どうして符号拡張されるのか?逆アセンブルで説明したつもりになってはいけない、逃げてはダメだ!という熱心なあなたのために、マクロを展開しながら説明します。今回の解説は __MAP(), __SC_LONG(), __SC_CAST() マクロの展開結果です。
__MAP(), __SC_LONG(), __SC_CAST() マクロの合わせ技
今まで説明してきた __MAP(), __SC_LONG(), __SC_CAST() マクロを総動員して全部展開すると、
__MAP4(), __SC_LONG(), __SC_CAST() マクロの展開結果の例
__MAP(4,__SC_LONG,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg)
↓
__SC_LONG(int, magic1),
__SC_LONG(int, magic2),
__SC_LONG(unsigned int, cmd),
__SC_LONG(void __user *, arg)
↓
long magic1,
long magic2,
long cmd,
long arg
__MAP(4,__SC_CAST,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg)
↓
__SC_CAST(int, magic1),
__SC_CAST(int, magic2),
__SC_CAST(unsigned int, cmd),
__SC_CAST(void __user *, arg)
↓
(int)magic1,
(int)magic2,
(unsigned int)cmd,
(void __user *)arg
になります。他のマクロ __SC_TEST() と __SC_ARGS() と __PROTECT() は本筋ではないので詳細は省きますが、下記のような実装です。
__SC_TEST(), __SC_ARGS(), __PROTECT() マクロの実装
// linux/include/linux/syscalls.h
#define __SC_TEST(t, a) (void)BUILD_BUG_ON_ZERO(!__TYPE_IS_LL(t) && sizeof(t) > sizeof(long))
#define __SC_ARGS(t, a) a
#define __PROTECT(...) asmlinkage_protect(__VA_ARGS__)
// linux/include/linux/build_bug.h
/*
* Force a compilation error if condition is true, but also produce a
* result (of value 0 and type int), so the expression can be used
* e.g. in a structure initializer (or where-ever else comma expressions
* aren't permitted).
*/
#define BUILD_BUG_ON_ZERO(e) ((int)(sizeof(struct { int:(-!!(e)); })))
// linux/include/linux/linkage.h
#ifndef __ASSEMBLY__
#ifndef asmlinkage_protect
# define asmlinkage_protect(n, ret, args...) do { } while (0)
#endif
#endif
展開するとこうなります。
__SC_TEST(), __SC_ARGS(), __PROTECT() マクロの展開の例
__SC_TEST(AAA, BBB)
// AAAがlong longでもunsigned long longでもない型で、
// long型より大きい型(構造体とかが該当する)の場合に、
// コンパイルエラーにする。
__SC_ARG(AAA, BBB)
↓
BBB
__PROTECT(n, ret, args...)
↓
// m68kアーキテクチャでは引数をスタックに置かないようにする役目のコードになるらしい。
// 他のアーキテクチャでは下記のようになって何も意味はない。
do { } while (0)
これで不明な要素は全てなくなったはずです。続きはまた今度。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年2月6日
RISC-V 64bit Linuxとシステムコールと32bitの引数 その6 - SYSCALL_DEFINE() を全部展開
目次: RISC-V
昨日の続きです。「64bit環境においてシステムコールの引数がレジスタ長(= 64bit)以下だった場合(例えばintが典型例)、どう扱うか?」コードの解説編です。
どうして符号拡張されるのか?逆アセンブルで説明したつもりになってはいけない、逃げてはダメだ!という熱心なあなたのために、マクロを展開しながら説明します。今回の解説は __MAP(), __SC_LONG(), __SC_CAST() マクロの意味や実装です。
SYSCALL_DEFINE() の展開
今までのSYSCALL_DEFINE(), __MAP(), __SC_LONG(), __SC_CAST() マクロを全部合体させて展開して、組み込み関数などを外すとこうなるはずです。
rebootシステムコールの実装部分、最終形
asmlinkage long __se_sys_reboot(__MAP(4,__SC_LONG,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg))
{
long ret = __do_sys_reboot(__MAP(4,__SC_CAST,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg));
__MAP(4,__SC_TEST,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg);
__PROTECT(4, ret,__MAP(4,__SC_ARGS,int, magic1, int, magic2, unsigned int, cmd, void __user *, arg));
return ret;
}
↓こうなる
asmlinkage long __se_sys_reboot(long magic1, long magic2, long cmd, long arg)
{
long ret = __do_sys_reboot((int)magic1, (int)magic2, (unsigned int)cmd, (void __user *)arg));
//__SC_TEST() による型のチェック、チェックに引っかかったらコンパイルエラー
//__PROTECT(magic1, magic2, cmd, arg) に展開されるがRISC-V 64bitでは何も意味はない
return ret;
}
つまり __se_sys_reboot() ではシステムコールからの引数はlong long, unsigned long longを除いて常にlong型の引数として扱い(__SC_LONGマクロの働き)、システムコールの本体 __do_sys_reboot() にはシステムコールが定義する本来の型にキャストして渡します(__SC_CASTマクロの働き)。
例えばmusl libcのreboot() のmagic1にあたるレジスタa0には0x00000000_fee1deadが渡されます。longの値として解釈すると正の数4276215469ですが、__do_sys_reboot() の呼び出し時にintにキャストして渡すため0xfee1dead = -18751827であると解釈されます(たぶん、大抵は)。
キャストされた負のint型の値を __do_sys_reboot() はlong型の引数で受け取ります。このときlong型で -18751827と解釈される値(= 0xfee1deadを64bitに符号拡張した0xffffffff_fee1dead)をレジスタa0に格納して、関数呼び出しを行います。
__do_sys_reboot() のmagic1引数の値(再掲)
(gdb) b __do_sys_reboot
Breakpoint 1 at 0xffffffff8002d860: file kernel/reboot.c, line 702.
(gdb) c
Continuing.
Breakpoint 1, __do_sys_reboot (magic1=-18751827, magic2=672274793,
cmd=1126301404, arg=0x4321fedc) at kernel/reboot.c:702
702 {
(gdb) p/x $a0
$1 = 0xfffffffffee1dead
なので __do_sys_reboot() でブレークしてレジスタa0の内容を表示すると、0xffffffff_fee1deadになっていたわけです。
いやー長かった。マクロの魔術ですね。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年2月7日
C言語でlongをintにキャストしたらどうなるの?
目次: C言語とlibc
最近RISC-V 64bit向けのLinuxシステムコールの実装を調べていました(2023年2月1日の日記など)。そのなかでlong型をintにキャストし、負の値として解釈している部分がありました。
C言語に詳しい方は「あれ?」と思ったかもしれません。一見して問題なさそうな操作ですが、C言語の仕様によれば結果は実装依存(implementation-defined)です。アーキテクチャやコンパイラ次第で結果が変わるということです。
条件はlongよりintの方が大きい(sizeof(long) > sizeof(int) になる)ときです。現代では64bit環境が該当するでしょう。32bit環境は大抵longとintが同じ値域なので問題は発生しません。
概要をお伝えしたところで、言語仕様を見てみましょう。
N1570 (C11 committee draft) 6.3.1.3の定義とざっくり和訳
6.3.1.3 Signed and unsigned integers When a value with integer type is converted to another integer type other than _Bool, if the value can be represented by the new type, it is unchanged. Otherwise, if the new type is unsigned, the value is converted by repeatedly adding or subtracting one more than the maximum value that can be represented in the new type until the value is in the range of the new type. Otherwise, the new type is signed and the value cannot be represented in it; either the result is implementation-defined or an implementation-defined signal is raised. (ざっくり和訳) 整数型の値が _Bool以外の整数型に変換される場合、もし値が新しい型で表現できるなら 値は変化しません。 新しい型が符号なしで表現できないならば、新しい型の範囲に入るまで、新しい型が表現できる 最大値より1多い値を繰り返し加算または減算して値を変換します。 (訳注) パディング等も認められているのでややこしい言い方になっている。 元の型が32bit整数で0x2_3456、新しい型が16bit整数で最大値0xffffだとする。 このとき新しい型の最大値 + 1 = 0x1_0000である。 元の型の値0x2_3456は新しい型の範囲より大きいので、最大値 + 1を減算し続ける。 ・0x2_3456 - 0x1_0000 = 0x1_3456 → 新しい型の範囲に入っていない ・0x1_3456 - 0x1_0000 = 0x0_3456 → 新しい型の範囲に入った よって新しい型の値は0x3456となる。 この処理は新しい型から溢れた上位ビット(つまりこの例でいえば16bit以上の上位ビット)を 全て0クリアする処理に相当する。 (訳注、終わり) 新しい型が符号付きで値を表現できないならば、結果は実装定義になるか、もしくは実装定義の シグナルが生成されます。
Linuxは対象とするアーキテクチャとコンパイラが限定(GCCかClang)されており、実装依存の動きを把握した上で使っていると思われます。承知の上というやつですね。
どの実装で使われるかわからないコードを書くなら、longからintへのキャストは常に結果が同じとは限らないので、キャストの結果で何が起きるか理解して使う必要があります。
気にしすぎても仕方がない
建前は上記の通りですが「全てのCコンパイラで動作するコード」を書く機会って、ほぼないと思います。基本的には細かい仕様を気にしすぎて何も進まなくなるより、時代で受け入れられる常識的な制約を付けて進めて、後で困ったら直せば良いんじゃない?と思います。
一方で2038年問題のように、プログラムが書かれた時代は常識的な制約だったしみんな使っていたけど、何十年も経ってから大問題になるケースもあります。「常識的な制約 = ずっと無罪放免」かどうかは誰にもわかりません。
今の64bitアーキテクチャに由来する時間や容量の制約は十分余裕があると思われますが、100年後の世界なんてわかりません。「誰が64bit決め打ちの実装にした!?100年前の奴らだと……??」って泣きながら直している人がいても不思議じゃないですよね。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年2月10日
卵が割れる階数は?問題
Twitterで見かけて面白かった問題、解法をメモしておきます。
100階建てのビルから卵を落とします。卵はある階よりも低ければ割れませんが、ある階よりも高いと割れます。卵を2つ持っているとき、卵が何階で割れるか調べる方法を提示してください。そのとき卵を落とす最大の回数をできる限り小さくしてください。
という問題です。
基本的な考え方
1階から順に落とせば確実にわかりますが、最大の投擲回数が100回(卵が割れる階数が100Fのとき)になり、最適な方法ではありません。
卵が2個あることを利用し、1個目は複数階を一気に飛ばして(例10F, 20F, 30F, ...)投擲します。例えば10F飛ばしで試すとすると10F, 20F, 30Fで割れず40Fで割れたら、2個目は「最後に割れなかった階の1つ上の階」すなわち31Fから投擲します。このように試すともっと早く卵が割れる階数がわかります。
卵の投擲回数の最大値を計算すると、例えば10F飛ばしであれば1個目が最大10回(10F, 20F, 30F, ..., 90F, 100F)、2個目が最大で9回(x1F〜x9F)なので、19回(卵が割れる階数が99Fのとき)です。100回と比べるとだいぶ少なくなりましたが、まだ無駄が残っています。
答え
固定階数を飛ばす方法だと1個目と2個目の最大の投擲回数の和を見たとき、上の階になるほど悪化します。例えば、
- 卵が割れる階数が39F: 10F〜30Fまでで3回、31F〜39Fで最大9回 = 12回
- 卵が割れる階数が99F: 10F〜90Fまでで9回、91F〜99Fで最大9回 = 18回
1個目の投擲方法を変えて最初は10F飛ばし、次は9F飛ばし、その次は8F飛ばし、のようにすると投擲回数の最大値が悪化しないことに気づくと思います。
こんな表で示すとわかりやすいでしょうか。
| 1個目を投擲する階数 | 次に何階飛ばすか | 1個目の投擲回数 | 2個目の投擲開始階 | 2個目の最大の投擲回数 | 最大の投擲回数 |
|---|---|---|---|---|---|
| 100 | 12 | 98 | 2 | 14 | |
| 97 | 3 | 11 | 94 | 3 | 14 |
| 93 | 4 | 10 | 89 | 4 | 14 |
| 88 | 5 | 9 | 83 | 5 | 14 |
| 82 | 6 | 8 | 76 | 6 | 14 |
| 75 | 7 | 7 | 68 | 7 | 14 |
| 67 | 8 | 6 | 59 | 8 | 14 |
| 58 | 9 | 5 | 49 | 9 | 14 |
| 48 | 10 | 4 | 38 | 10 | 14 |
| 37 | 11 | 3 | 26 | 11 | 14 |
| 25 | 12 | 2 | 13 | 12 | 14 |
| 12 | 13 | 1 | 1 | 11 | 12 |
1個目は12F, 25F, 37F, 48F, 58F, 67F, 75F, 82F, 88F, 93F, 97F, 100Fの順に投擲します。最大で12回です。割れたら最後に成功した階の1つ上の階から投擲すると、最大14回で卵が割れる階数がわかります。
最大の回数になるケースは12通りですが、一例として卵が割れる階数が99Fの場合を示します。12, 25, ..., 100(1個目が割れる), 98, 99(2個目が割れる)の14回になります。
他には1個目を投げる階数を下記のようにしても良いです。
- 9F, 22F, 34F, 45F, 55F, 64F, 72F, 79F, 85F, 90F, 94F, 97F, 99F, 100F
- 10F, 23F, 35F, 48F, 56F, 65F, 73F, 80F, 86F, 91F, 95F, 98F, 100F
いずれも投擲回数は最大14回となります。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年2月13日
CoreMarkのコンパイルオプションをチューンする
目次: RISC-V
以前(2022年12月22日の日記参照)の日記でCoreMarkのスコアを測って表にしました。実はCoreMarkはOfastのみでは最速にはならず、コンパイルオプションをガチガチにチューンすると結構差が出ます。実際にNSITEXE NS31Aの測定結果でお見せしたいと思います。
どうしてNS31Aかというと、非常にシンプルなCPU&自分の会社で作っているので素性が明確であるためです。複雑なCPU、中身の分からないCPUになればなるほど、総当たりでオプションの組み合わせを試す不毛な作業になりがちです。今回はそういう組み合わせ問題を解きたいわけじゃないんで、簡単な奴で行きます。
まずはベースとなるOfastの結果です。実はO3でも結果は同じです。
CoreMark on NS31A(チューン前)
2K performance run parameters for coremark.
CoreMark Size : 666
Total ticks : 18912
Total time (secs): 18.912000
Iterations/Sec : 58.164129
Iterations : 1100
Compiler version : GCC12.2.0
Compiler flags : -Ofast -gdwarf-4 -march=rv32im -mabi=ilp32 -mcmodel=medany
Memory location : Please put data memory location here
(e.g. code in flash, data on heap etc)
seedcrc : 0xe9f5
[0]crclist : 0xe714
[0]crcmatrix : 0x1fd7
[0]crcstate : 0x8e3a
[0]crcfinal : 0x33ff
Correct operation validated. See README.md for run and reporting rules.
CoreMark 1.0 : 58.164129 / GCC12.2.0 -Ofast -gdwarf-4 -march=rv32im -mabi=ilp32 -mcmodel=medany / Heap
動作周波数は25MHzですので、58.164129 / 25 = 2.326 CM/MHz です。
コンパイルオプションを足そう
最適化の基本となる、ループアンローリング、インライン化(-funroll-all-loops, -finline-functions)を足します。
キャッシュラインが32バイトなので、関数の先頭を32バイト境界に配置します(-falign-functions=32)。関数先頭で命令キャッシュミスヒットが発生したときに、同じキャッシュラインに後続の命令(1ラインに32 / 4 = 8命令)が載ります。後続の命令フェッチがキャッシュヒットすれば、最初のミスヒットを挽回できるだろうという目的です。
ジャンプやループの際に実行しない命令が中途半端にキャッシュに取り込まれないよう(= 利用効率の向上)、ジャンプやループの位置は8バイト境界に配置します(-falign-jumps=8 -falign-loops=8)。これも32バイト境界にすべきかと思いましたが、コード領域が散逸しすぎるためか逆に遅いです。
基本的に関数はインライン化した方がcall, retを省略、レジスタ共用など全体的に最適化できて速いです。しかしNS31Aは命令キャッシュが小さめ(FPGA向けコンフィグでは16KB)なので、無差別に関数をインライン化すると命令キャッシュがあふれてキャッシュミスヒットが発生してしまい、逆に遅くなります。
従ってあまりにも大きな関数はインライン化しないように設定します(-finline-limit=300)。デフォルト値600の1/2にしています(※)。
CoreMark on NS31A(チューン後)
2K performance run parameters for coremark.
CoreMark Size : 666
Total ticks : 15819
Total time (secs): 15.819000
Iterations/Sec : 69.536633
Iterations : 1100
Compiler version : GCC12.2.0
Compiler flags : -Ofast -gdwarf-4 -march=rv32im -mabi=ilp32 -mcmodel=medany -funroll-all-loops -finline-functions -finline-limit=300 -falign-functions=32 -falign-jumps=8 -falign-loops=8
Memory location : Please put data memory location here
(e.g. code in flash, data on heap etc)
seedcrc : 0xe9f5
[0]crclist : 0xe714
[0]crcmatrix : 0x1fd7
[0]crcstate : 0x8e3a
[0]crcfinal : 0x33ff
Correct operation validated. See README.md for run and reporting rules.
CoreMark 1.0 : 69.536633 / GCC12.2.0 -Ofast -gdwarf-4 -march=rv32im -mabi=ilp32 -mcmodel=medany -funroll-all-loops -finline-functions -finline-limit=300 -falign-functions=32 -falign-jumps=8 -falign-loops=8 / Heap
動作周波数は25MHzですので、69.536633 / 25 = 2.781 CM/MHzです。ハードウェアは何も変えていませんが、性能1.2倍です。コンパイルオプションの威力恐るべし。
(※)この数値はGCC内部で使う仮想命令のライン数らしく、300が本当に適切か示すのは不可能です。マニュアルを見ると1/2や1/4に調整することが多いようなので、それに倣っています(参考: GCCのマニュアル)。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年2月25日
東京の道の名前
東京の道はようわからん通称(明治通り、みたいなやつ)が付いています。東京育ちの人にはなじみ深い名前だと思うんですが、都外出身者からすると、東京の道の通称と国道何号線、都道何号線の区分が全く合っていないので、知らない場所の道の通称を言われると結構困ります。
なぜかというと国道何号線、都道何号線という表記は地図で省かれることはない一方で、東京の道の通称は高速道路や地下鉄と重なったときに省かれてしまうことがあるためです。地図を見ても「〇〇通り?何それ?どこ??」と困惑します。
通称とは一体?
東京の道の通称は東京都が決めています(東京都通称道路名〜道路のわかりやすく親しみやすい名称〜 - 東京都建設局)。道案内の青看板に載るような名前と思ってもらえばわかりやすいでしょう。
東京都がまとめてくれているのはありがたいんですが「東京都が公式に定めた通称」というのは不思議な響きで、それは公称ではなかろうか?通称とは一体……??
なぜか存在しない大正通り
東京の道の通称には「年号」+「通り」という名前がいくつかあります。このうちなぜか大正通りだけは存在しません。不思議ですね。
- 江戸通り(No.26: 国道6号など、千代田区大手町二丁目〜台東区花川戸二丁目)
- 明治通り(No.3: 都道416, 306号など、港区南麻布二丁目〜江東区夢の島)
- 昭和通り(No.24: 国道4号など、港区新橋一丁目〜台東区根岸五丁目)
調べてみると割と有名な話らしいです(「明治通り」「昭和通り」はあるのに、なぜか「大正通り」はない東京のちょっとした謎 - アーバン ライフ メトロ)。詳しくは記事を読んでいただくとして、簡単に言えば、
- 東京日日新聞の公募で大正通りと呼ぼうとした(今の靖国通り)が定着せず
- 東京都の公募で靖国通りが選ばれた、東京都建設局のまとめる一覧に大正通りは入ってない
- 東京に「大正通り」はある(武蔵野市吉祥寺)
- 「平成通り」もある(中央区兜町〜築地二丁目)
- 「令和通り」はまだない
ということみたいです。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年2月27日
SIMDを使ったお手軽最適化 - その1
目次: ベンチマーク
お手軽最適化のメモです。行列の掛け算を題材にします。
最初にお断りしておくとGEMMのような汎用処理の場合は、自分で最適化せずにOpenBLASを使ってください(素人が最適化しても勝てません)。しかしOpenBLASのような限界まで最適化されたコードは誰でも簡単には書ける、とは言えません。
スカラー処理だと遅いけれど、お手軽に最適化(数倍程度)がしたいときの参考になれば幸いです。
GEMMってなんですか?
GEMMはGeneral Matrix Multiplyの略で、高校数学辺りでやった(はず)の行列の掛け算のことです。floatの場合はSGEMMと呼ばれ、doubleの場合はDGEMMと呼ばれます。最適化の題材はどちらでも良いんですけど、今回はSGEMMを使います。
忘れている方のために2行3列の行列Aと3行2列Bの掛け算A x B = Cだとこんな感じです。
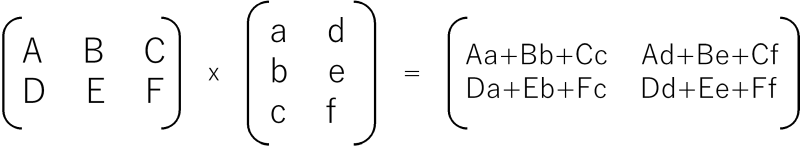
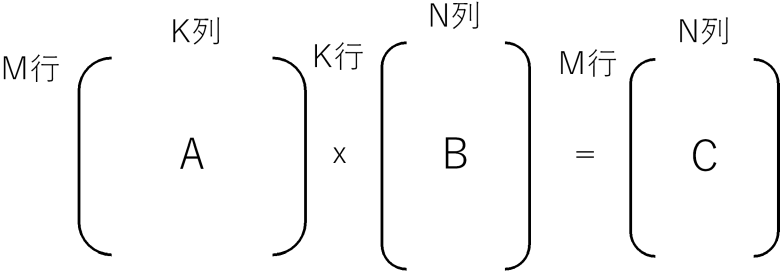
Aの列数とBの行数は一致していなければなりません。行数と列数の関係を表すと、行列A(M行K列)x行列B(K行N列)= 行列C(M行N列)となります。
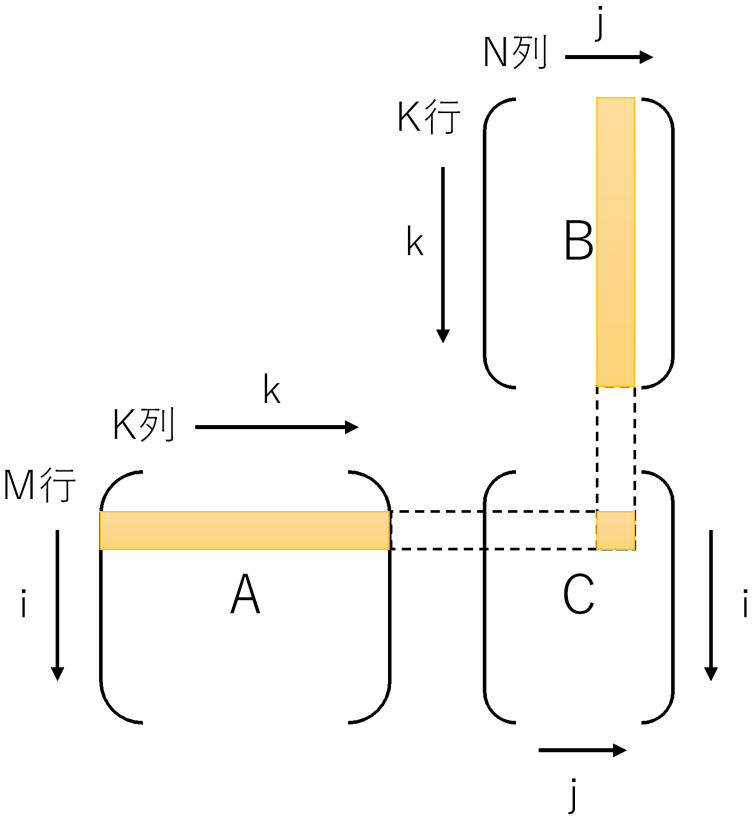
Cの1要素を計算するには、Aの1行とBの1列が必要です。式、および、視覚的に示すと下記のようになります。
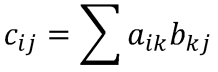
説明はこれくらいにしてコードを見ましょう。
基本コース - 素朴に演算
SGEMMを素直にコードにするとこんな感じです。行方向にデータを格納(Row-major orderといいます)しているので、N列の行列Cのi行j列(以降Ci,jと書く)にアクセスする際はc[i * N + j] とします。
SGEMM素朴版
void sgemm_naive(const float *a, const float *b, float *c, int mm, int nn, int kk)
{
for (int i = 0; i < mm; i++) {
for (int j = 0; j < nn; j++) {
c[i * nn + j] = 0.0f;
for (int k = 0; k < kk; k++) {
c[i * nn + j] += a[i * kk + k] * b[k * nn + j];
}
}
}
}
行列のサイズを適当に設定(M = 1519, N = 1517, K = 1523)して、実行時間を測ります。CPUはRyzen 7 5700Xです。
SGEMM素朴版の実行時間
$ gcc -Wall -g -O2 -static sgemm.c $ ./a.out matrix size: M:1519, N:1517, K:1523 time: 2.277758
実行時間は実行するたびに変わりますが、大体2.27秒くらいでしょうか。OpenBLASのシングルスレッド(環境変数OPENBLAS_NUM_THREADS=1にするとシングルスレッド動作になります)で計算した時間を見ると、
OpenBLASのSGEMMを呼ぶコード
c_ex = malloc(m * n * sizeof(float) * 2);
// C = alpha AB + beta C
float alpha = 1.0f, beta = 0.0f;
int lda = k, ldb = n, ldc = n;
printf("----- use CBLAS\n");
gettimeofday(&st, NULL);
cblas_sgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans,
m, n, k, alpha, a, lda, b, ldb, beta, c_ex, ldc);
gettimeofday(&ed, NULL);
timersub(&ed, &st, &ela);
printf("verify: %d.%06d\n", (int)ela.tv_sec, (int)ela.tv_usec);
OpenBLASのSGEMM実行時間
$ export OPENBLAS_NUM_THREADS=1 $ gcc -Wall -g -O2 -static -L path/to/openblas/ sgemm.c -lopenblas $ ./a.out matrix size: M:1519, N:1517, K:1523 ----- use CBLAS verify: 0.052149
わずか0.05秒、実に43倍という驚異のスピードです。すごいですね……。
行列の掛け算の説明でほぼ終わってしまいました。お手軽最適化はまた次に。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年2月28日
SIMDを使ったお手軽最適化 - その2
目次: ベンチマーク
お手軽最適化のメモ、昨日の続きです。行列の掛け算を題材にします。前回は行列の掛け算と素朴な実装のコードを紹介しました。今回はお手軽最適化を紹介します。
スカラー処理だと遅いけれど、お手軽に最適化(数倍程度)がしたいときの参考になれば幸いです。
お手軽コース - 自動ベクトル化
素朴版のコードですとi, j, kの順でループになっていて、kを最内ループにしていました。ループ内の計算は、
ループ内の計算式
c[i * nn + j] += a[i * kk + k] * b[k * nn + j]
でした。このときメモリアクセスのパターンは、
- A: 行方向に連続(メモリアクセスパターンは連続 = 自動ベクトル化できる)
- B: 列方向に連続(メモリアクセスパターンは飛び飛びアクセス = 自動ベクトル化できない)
- C: 同一要素を何度もアクセス
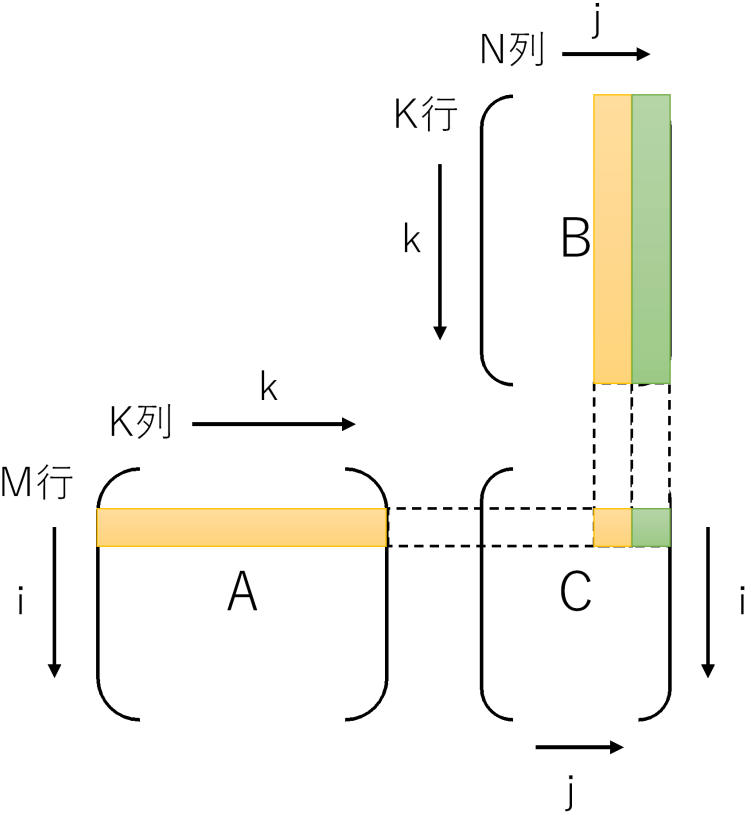
です。GCCの自動ベクトル化ですと、このアクセスパターンをうまく最適化できないようです。対象が最内ループのみなのかもしれません。ループを入れ替えjを最内にして、BとCを行方向に読むようにします。するとメモリアクセスのパターンは、
- A: 同一要素を何度もアクセス
- B: 行方向に連続(メモリアクセスパターンは連続 = 自動ベクトル化できる)
- C: 行方向に連続(メモリアクセスパターンは連続 = 自動ベクトル化できる)
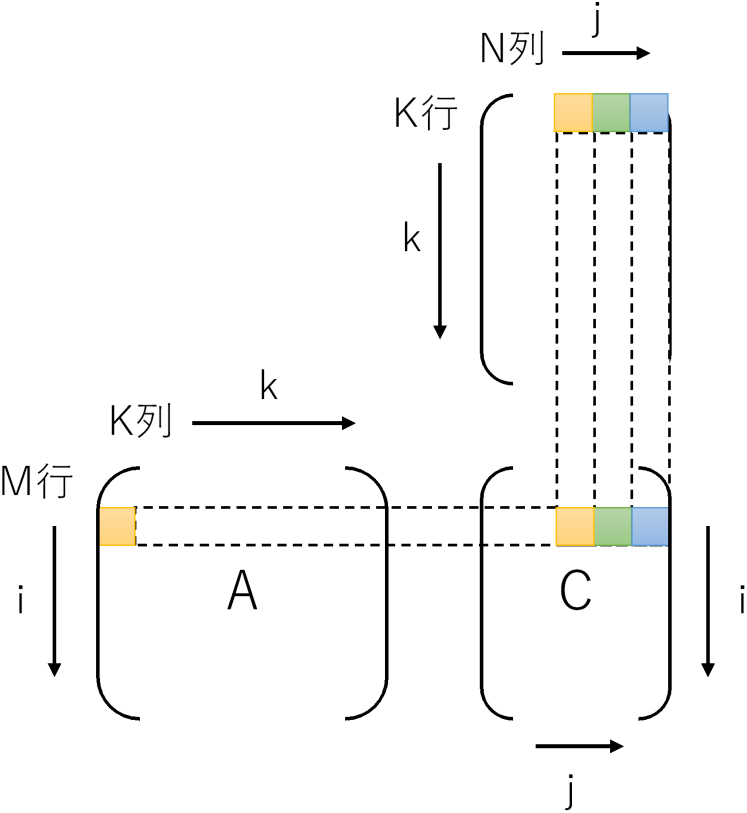
です。ループを入れ替えるとループ内でCの0初期化ができないので、ループの外に追い出して最終的に下記のようなコードになります。
SGEMMループ入れ替え版
void sgemm_inner(const float *a, const float *b, float *c, int mm, int nn, int kk)
{
for (int i = 0; i < mm; i++) {
for (int j = 0; j < nn; j++) {
c[i * nn + j] = 0.0f;
}
}
for (int i = 0; i < mm; i++) {
for (int k = 0; k < kk; k++) {
for (int j = 0; j < nn; j++) { //★★jが最内ループ★★
c[i * nn + j] += a[i * kk + k] * b[k * nn + j];
}
}
}
}
SGEMMループ入れ替え版の実行時間
$ gcc -Wall -g -O2 -fno-tree-vectorize -static -march=znver3 sgemm.c $ ./a.out matrix size: M:1519, N:1517, K:1523 time: 1.528314 (参考: 素朴版の実行時間) time: 2.277758 (参考: OpenBLASシングルスレッドの実行時間) $ export OPENBLAS_NUM_THREADS=1 ----- use CBLAS verify: 0.052149
ループ入れ替えで倍くらい速くなっていますが、この最適化の本領はコンパイラの自動ベクトル化です。GCCならば -ftree-vectorizeオプションを指定すると、行列Bと行列CへのアクセスにSIMD命令を使うようになります。
Ryzen 7 5700Xの場合はAVX2命令を使えます。他のCPUをお使いの場合は -marchを適宜変更してください。
SGEMMループ入れ替え版+自動ベクトル化の実行時間
$ gcc -Wall -g -O2 -ftree-vectorize -static -march=znver3 sgemm.c $ ./a.out matrix size: M:1519, N:1517, K:1523 time: 0.181133 (参考: OpenBLASシングルスレッドの実行時間) $ export OPENBLAS_NUM_THREADS=1 ----- use CBLAS verify: 0.052149
素朴版とOpenBLASでは1/43もの差がありましたが、ループ入れ替えと自動ベクトル化によってOpenBLASの1/3.5程度まで近づきました。GEMMが計算偏重の処理で最適化の効果が出やすい、という点を考慮する必要はあるものの僅かな書き換えで得られる効果にしては割と良いのではないでしょうか。
もう少し頑張るコース - intrinsics
ソースコードを書き換える元気があれば、別の最適化方法もあります。GEMM特有の話に近付いてしまい、汎用的な話から遠ざかりますが、最適化ポイントの例という意味では参考になるはず……です。たぶん。
今回はSIMD命令でjの方向に一気に読むまでは同じですが、jの方向に進めるのではなく、kの方向に進めて、計算結果をCに足していく戦略です。具体的に言えばAi,kとBk,j〜Bk,j+7の8要素を一気に掛け算してCi,j〜Ci,j+7へ一気に足します。なぜ8要素かというとAVX/AVX2のレジスタ長(256bit)を使うと、32bit長のfloatを一度に8要素処理できるためです。

SIMD命令にはAi,kをSIMDレジスタの全要素に配る命令(set1_psから生成されるbroadcast命令)や、掛け算と足し算を一度に行うfmadd命令など、この計算順に最適な命令が揃っています。

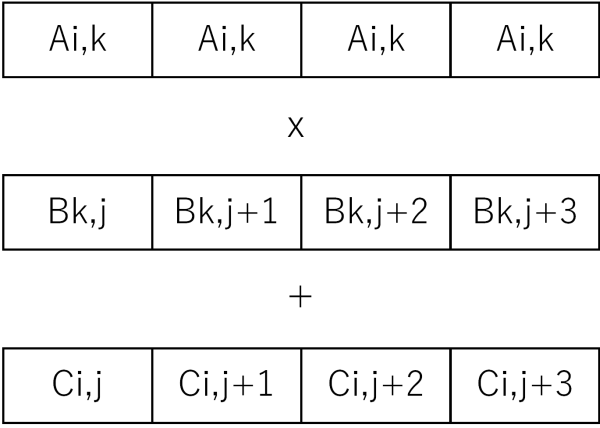
AVX/AVX2のIntrinsicsの詳細についてはIntelのサイトなどを見ていただくとして(Intel Intrinsics Guide)、コードは下記のようになります。
SGEMM Intrinsics版
#include <immintrin.h>
void sgemm_avx(const float *a, const float *b, float *c, int mm, int nn, int kk)
{
for (int j = 0; j < nn;) {
if (nn - j >= 8) {
for (int i = 0; i < mm; i++) {
__m256 vc = _mm256_set1_ps(0.0f);
for (int k = 0; k < kk; k++) {
__m256 va = _mm256_set1_ps(a[i * kk + k]);
__m256 vb = _mm256_loadu_ps(&b[k * nn + j]);
vc = _mm256_fmadd_ps(va, vb, vc);
}
_mm256_storeu_ps(&c[i * nn + j], vc);
}
j += 8;
} else {
for (int i = 0; i < mm; i++) {
c[i * nn + j] = 0.0f;
for (int k = 0; k < kk; k++) {
c[i * nn + j] += a[i * kk + k] * b[k * nn + j];
}
}
j++;
}
}
}
SGEMM Intrinsics版の実行時間
$ gcc -Wall -g -O2 -static -march=znver3 sgemm.c $ ./a.out matrix size: M:1519, N:1517, K:1523 time: 0.384861 (参考: 素朴版の実行時間) time: 2.277758 (参考: ループ入れ替え版+自動ベクトル化の実行時間) time: 0.181133 (参考: OpenBLASシングルスレッドの実行時間) $ export OPENBLAS_NUM_THREADS=1 ----- use CBLAS verify: 0.052149
素朴版と比べると6倍速いですが、ループ入れ替え+自動ベクトル化には負けています。
もう少し頑張るコース - ループアンローリング
先程のコードはSIMDレジスタを3個しか同時に使っていませんでした。AVX/AVX2のYMMレジスタは16個もあるのに3個しか使わないのはもったいですから、iのループを8要素ずつアンローリングしてSIMDレジスタを同時にたくさん使いましょう。レジスタをうまく使いまわせば12要素のアンローリング(Bの保持に1個、Cの保持に12個、Aの保持に1個、計14個)まではできそうです。たぶん。
SGEMM Intrinsics+ループアンローリング版
#include <immintrin.h>
void sgemm_avx_unroll8(const float *a, const float *b, float *c, int mm, int nn, int kk)
{
for (int j = 0; j < nn;) {
if (nn - j >= 8) {
int i = 0;
for (; i < (mm & ~7); i += 8) {
__m256 vc0 = _mm256_set1_ps(0.0f);
__m256 vc1 = _mm256_set1_ps(0.0f);
__m256 vc2 = _mm256_set1_ps(0.0f);
__m256 vc3 = _mm256_set1_ps(0.0f);
__m256 vc4 = _mm256_set1_ps(0.0f);
__m256 vc5 = _mm256_set1_ps(0.0f);
__m256 vc6 = _mm256_set1_ps(0.0f);
__m256 vc7 = _mm256_set1_ps(0.0f);
for (int k = 0; k < kk; k++) {
__m256 vb = _mm256_loadu_ps(&b[k * nn + j]);
__m256 va0 = _mm256_set1_ps(a[(i+0) * kk + k]);
__m256 va1 = _mm256_set1_ps(a[(i+1) * kk + k]);
__m256 va2 = _mm256_set1_ps(a[(i+2) * kk + k]);
__m256 va3 = _mm256_set1_ps(a[(i+3) * kk + k]);
__m256 va4 = _mm256_set1_ps(a[(i+4) * kk + k]);
__m256 va5 = _mm256_set1_ps(a[(i+5) * kk + k]);
__m256 va6 = _mm256_set1_ps(a[(i+6) * kk + k]);
__m256 va7 = _mm256_set1_ps(a[(i+7) * kk + k]);
vc0 = _mm256_fmadd_ps(va0, vb, vc0);
vc1 = _mm256_fmadd_ps(va1, vb, vc1);
vc2 = _mm256_fmadd_ps(va2, vb, vc2);
vc3 = _mm256_fmadd_ps(va3, vb, vc3);
vc4 = _mm256_fmadd_ps(va4, vb, vc4);
vc5 = _mm256_fmadd_ps(va5, vb, vc5);
vc6 = _mm256_fmadd_ps(va6, vb, vc6);
vc7 = _mm256_fmadd_ps(va7, vb, vc7);
}
_mm256_storeu_ps(&c[(i+0) * nn + j], vc0);
_mm256_storeu_ps(&c[(i+1) * nn + j], vc1);
_mm256_storeu_ps(&c[(i+2) * nn + j], vc2);
_mm256_storeu_ps(&c[(i+3) * nn + j], vc3);
_mm256_storeu_ps(&c[(i+4) * nn + j], vc4);
_mm256_storeu_ps(&c[(i+5) * nn + j], vc5);
_mm256_storeu_ps(&c[(i+6) * nn + j], vc6);
_mm256_storeu_ps(&c[(i+7) * nn + j], vc7);
}
for (; i < mm; i++) {
__m256 vc = _mm256_set1_ps(0.0f);
for (int k = 0; k < kk; k++) {
__m256 vb = _mm256_loadu_ps(&b[k * nn + j]);
__m256 va = _mm256_broadcast_ss(&a[(i+0) * kk + k]);
vc = _mm256_fmadd_ps(va, vb, vc);
}
_mm256_storeu_ps(&c[i * nn + j], vc);
}
j += 8;
} else {
for (int i = 0; i < mm; i++) {
c[i * nn + j] = 0.0f;
for (int k = 0; k < kk; k++) {
c[i * nn + j] += a[i * kk + k] * b[k * nn + j];
}
}
j++;
}
}
}
SGEMM Intrinsics+ループアンローリング版の実行時間
$ ./a.out matrix size: M:1519, N:1517, K:1523 time: 0.108420 (参考: ループ入れ替え版+自動ベクトル化の実行時間) time: 0.181133 (参考: OpenBLASシングルスレッドの実行時間) $ export OPENBLAS_NUM_THREADS=1 ----- use CBLAS verify: 0.052149
もはや最適化前のコードの原型がありませんが、ループ入れ替え版+自動ベクトル化の1.7倍くらいの速度になりました。OpenBLASの1/2程度まで迫っています。この最適化手法が汎用的か?と聞かれると何とも言えないですが、SIMDレジスタを同時にたくさん使う、最内ループ以外もアンローリング(最内ループはコンパイラがやってくれる)辺りは割と汎用的なアイデアです。
あと前回言った通り、GEMMは最適化の題材として取り上げただけなので、実際にGEMMを計算する場合はこのコードや自分で書いたコードを使うのではなく、信頼と実績のOpenBLASを使ってくださいませ。
コメント一覧
- コメントはありません。
この記事にコメントする
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報