2017年11月5日

Androidのメディア再生処理
目次: Android
たまにはAndroidの話でも。Androidのメディア再生のデコード完了から出画までを見てみました。
Media | Android Open Source Project 辺りにあるように、Androidはlibstagefrightにメディアの処理を任せています。
図からはちょっと読み取りづらいですが、libstagefrightは動画、音声のデコードにOpenMAXというAPIを用います。図だとOMX Coreと書かれている部分です。
OpenMAXざっくり紹介
OpenMAXの各種デコーダ(※)は「コンポーネント」と呼ばれる部品になっています。
OpenMAXではデータの入力はEmptyThisBufferと呼びます。データの入力は非同期に行うことができます。コンポーネントは入力を処理し終えたら完了通知をコールバック(EmptyBufferDone)する仕組みになっています。
データの出力はFillThisBufferと呼びます。出力も非同期に行うことができます。コンポーネントはデータ出力の完了通知(FillBufferDone)をする仕組みになっています。
libstagefrightはOpenMAXのコンポーネントに対して、下記の処理を行います。他にも設定、フラッシュ、などややこしい処理がありますが、省略。
入力側はこんな感じです。
- 圧縮データが入ったバッファをEmptyThisBufferでコンポーネントに渡す
- (コンポーネント内でバッファのデータが処理される)
- 空になったバッファがEmptyBufferDoneで返ってくる
出力側もほぼ同じです。
- 空のバッファをFillThisBufferでコンポーネントに渡す
- (コンポーネント内でバッファにデコード済みデータが詰め込まれる)
- デコード済みデータが入ったバッファがFillBufferDoneで返ってくる
バッファが2つある場合も基本的には同じです。OpenMAXの特徴はバッファ1とバッファ2がお互いを気にしなくて良いことです。バッファ2が返ってきていようが返ってきていまいが、バッファ1はコンポーネントに渡して構いません。
例えばバッファ2にすごく時間が掛かって、こんな順になっても構いません(コロンの右側はコンポーネントに渡したが返ってきていないバッファの一覧)。
- start: なし
- FillThisBuffer 1: 1
- FillThisBuffer 2: 1, 2
- FillBufferDone 1: 2
- FillThisBuffer 1: 1, 2
- FillBufferDone 1: 2
- FillThisBuffer 1: 1, 2
- FillBufferDone 2: 1
- FillBufferDone 1: なし
特にデコーダの場合は、この例のように渡した順番と返ってくる順番が違う場合がほとんどです。
(※)OpenMAXの規格が定義するコンポーネントの機能は、デコーダだけではありません。しかしAndroidはデコーダコンポーネントしか使いません。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2017年11月6日
Androidメディア処理 - OpenMAXのデコード完了通知
目次: Android
昨日(2017年11月5日の日記参照)の続きです。
OpenMAXの解説をしていると日が暮れるのでやめます。とにかくデコードされた画素データはFillBufferDoneで返ってくることがわかっていれば、コードを追いかけられるはずです。
見ているコードはAndroid 7.1です。タグで言えばandroid-7.1.2_r33辺りです。
デコード完了のお知らせ
FillBufferDoneはコールバックであることは説明しました。OpenMAXの規格では、コンポーネントがコールバックする関数は、コンポーネントを生成する際に指定します。コールバックされる関数を探すには、コンポーネントを生成していそうな個所を探せばわかるはずです。
OpenMAXコンポーネント生成とコールバックの指定
//android/frameworks/av/media/libstagefright/omx/OMX.cpp
status_t OMX::allocateNode(
const char *name, const sp<IOMXObserver> &observer,
sp<IBinder> *nodeBinder, node_id *node) {
...
OMXNodeInstance *instance = new OMXNodeInstance(this, observer, name); //★★1番目の引数がownerなので、thisつまりこのオブジェクトが指定される★★
OMX_COMPONENTTYPE *handle;
OMX_ERRORTYPE err = mMaster->makeComponentInstance(
name, &OMXNodeInstance::kCallbacks,
instance, &handle); //★★2番目の引数kCallbacksがコールバック関数の指定。3番目の引数instanceがFillBufferDoneのpAppDataに渡される★★
//android/frameworks/av/media/libstagefright/omx/OMXNodeInstance.cpp
// static
OMX_CALLBACKTYPE OMXNodeInstance::kCallbacks = {
&OnEvent, &OnEmptyBufferDone, &OnFillBufferDone
};
かなり端折ってますが、FillBufferDoneのコールバック関数にはOMXNodeInstance::OnFillBufferDoneを指定しているようです。従ってデコードが終わると、画素データが入ったバッファがOMXNodeInstance::OnFillBufferDone関数に渡されます。
デコード完了のコールバック処理
//android/frameworks/av/media/libstagefright/omx/OMXNodeInstance.cpp
// static
OMX_ERRORTYPE OMXNodeInstance::OnFillBufferDone(
OMX_IN OMX_HANDLETYPE /* hComponent */,
OMX_IN OMX_PTR pAppData,
OMX_IN OMX_BUFFERHEADERTYPE* pBuffer) {
...
OMXNodeInstance *instance = static_cast<OMXNodeInstance *>(pAppData); //★★makeComponentInstanceの3番目の引数に渡した値★★
if (instance->mDying) {
return OMX_ErrorNone;
}
int fenceFd = instance->retrieveFenceFromMeta_l(pBuffer, kPortIndexOutput);
return instance->owner()->OnFillBufferDone(instance->nodeID(),
instance->findBufferID(pBuffer), pBuffer, fenceFd); //★★ownerはOMX型のオブジェクトなのでOMX::OnFillBufferを見る★★
}
//android/frameworks/av/media/libstagefright/omx/OMX.cpp
OMX_ERRORTYPE OMX::OnFillBufferDone(
node_id node, buffer_id buffer, OMX_IN OMX_BUFFERHEADERTYPE *pBuffer, int fenceFd) {
ALOGV("OnFillBufferDone buffer=%p", pBuffer);
omx_message msg;
msg.type = omx_message::FILL_BUFFER_DONE;
msg.node = node;
msg.fenceFd = fenceFd;
msg.u.extended_buffer_data.buffer = buffer;
msg.u.extended_buffer_data.range_offset = pBuffer->nOffset;
msg.u.extended_buffer_data.range_length = pBuffer->nFilledLen;
msg.u.extended_buffer_data.flags = pBuffer->nFlags;
msg.u.extended_buffer_data.timestamp = pBuffer->nTimeStamp;
findDispatcher(node)->post(msg); //★★post() とは何だろうか??★★
return OMX_ErrorNone;
}
sp<OMX::CallbackDispatcher> OMX::findDispatcher(node_id node) {
Mutex::Autolock autoLock(mLock);
ssize_t index = mDispatchers.indexOfKey(node);
return index < 0 ? NULL : mDispatchers.valueAt(index); //★★mDispatchersとは?★★
}
謎の関数CallbackDispatcher::post() が出てきました。名前からするとメッセージパッシングを行うための関数ではないかと予想されます。この場所に限らずstagefrightではあらゆる場所でメッセージパッシングが使用されており、とても読みづらいです……。
メッセージfrom OpenMAX
CallbackDispatcherというクラスが出てきましたので、見てみます。
メッセージの生成
//android/frameworks/av/media/libstagefright/include/OMX.h
class OMX : public BnOMX,
public IBinder::DeathRecipient {
...
KeyedVector<node_id, sp<CallbackDispatcher> > mDispatchers; //★★mDispatchersの定義★★
//android/frameworks/av/media/libstagefright/omx/OMX.cpp
struct OMX::CallbackDispatcher : public RefBase {
CallbackDispatcher(OMXNodeInstance *owner);
// Posts |msg| to the listener's queue. If |realTime| is true, the listener thread is notified
// that a new message is available on the queue. Otherwise, the message stays on the queue, but
// the listener is not notified of it. It will process this message when a subsequent message
// is posted with |realTime| set to true.
void post(const omx_message &msg, bool realTime = true);
...
private:
...
std::list<omx_message> mQueue;
void OMX::CallbackDispatcher::post(const omx_message &msg, bool realTime) {
Mutex::Autolock autoLock(mLock);
mQueue.push_back(msg); //★★メッセージをキューに追加★★
if (realTime) {
mQueueChanged.signal();
}
}
引数のnode_id nodeから、適切なCallbackDispatcherを探して、内部キューmQueueにメッセージを追加しています。mQueueを手掛かりにメッセージを処理する側を探すと、どうやらCallbackDispatcherThreadが処理しているようです。
メッセージの消費
//android/frameworks/av/media/libstagefright/omx/OMX.cpp
bool OMX::CallbackDispatcherThread::threadLoop() {
return mDispatcher->loop();
}
bool OMX::CallbackDispatcher::loop() {
for (;;) {
std::list<omx_message> messages;
{
Mutex::Autolock autoLock(mLock);
while (!mDone && mQueue.empty()) {
mQueueChanged.wait(mLock);
}
if (mDone) {
break;
}
messages.swap(mQueue); //★★mQueueのロック時間を短くするため、別のリストに全てのメッセージを移動させる★★
}
dispatch(messages); //★★メッセージ処理★★
}
return false;
}
void OMX::CallbackDispatcher::dispatch(std::list<omx_message> &messages) {
if (mOwner == NULL) {
ALOGV("Would have dispatched a message to a node that's already gone.");
return;
}
mOwner->onMessages(messages); //★★メッセージ送信先のmOwnerとは?★★
}
OMX::CallbackDispatcher::CallbackDispatcher(OMXNodeInstance *owner)
: mOwner(owner), //★★CallbackDispatcherの生成時に渡された引数で初期化されている★★
mDone(false) {
mThread = new CallbackDispatcherThread(this);
mThread->run("OMXCallbackDisp", ANDROID_PRIORITY_FOREGROUND);
}
ここまででわかったことは、
- コンポーネントがOMXNodeInstance::OnFillBufferDoneをコールバックする
- OMX::OnFillBufferDoneがメッセージを送信する
- メッセージの行き先はOMX::mDispatchersに登録されているCallbackDispatcherをnewするときに渡した引数(mOwner)
困ったことに、肝心のメッセージがどこに行くか?がいまだに不明です。mOwnerとはどこで指定されているのでしょう?
メッセージはどこへ行く
OMX::mDispatchersを操作している箇所を探すと、1箇所見つかります。先程も出てきたOMX::allocateNode() です。
メッセージは誰に届くのか
//android/frameworks/av/media/libstagefright/omx/OMX.cpp
status_t OMX::allocateNode(
const char *name, const sp<IOMXObserver> &observer,
sp<IBinder> *nodeBinder, node_id *node) {
...
OMXNodeInstance *instance = new OMXNodeInstance(this, observer, name);
OMX_COMPONENTTYPE *handle;
OMX_ERRORTYPE err = mMaster->makeComponentInstance(
name, &OMXNodeInstance::kCallbacks,
instance, &handle); //★★3番目の引数、つまりinstanceがFillBufferDoneのpAppDataに渡される★★
if (err != OMX_ErrorNone) {
ALOGE("FAILED to allocate omx component '%s' err=%s(%#x)", name, asString(err), err);
instance->onGetHandleFailed();
return StatusFromOMXError(err);
}
*node = makeNodeID_l(instance);
mDispatchers.add(*node, new CallbackDispatcher(instance)); //★★メッセージの送信先を登録する★★
どうやらOMXNodeInstanceにメッセージを送っているようです。従ってmOwner->onMessages(messages) はここに辿り着きます。
メッセージが届きました?
void OMXNodeInstance::onMessages(std::list<omx_message> &messages) {
for (std::list<omx_message>::iterator it = messages.begin(); it != messages.end(); ) {
if (handleMessage(*it)) {
messages.erase(it++); //★★デコードに付随する情報をメッセージに載せる★★
} else {
++it;
}
}
if (!messages.empty()) {
mObserver->onMessages(messages); //★★mObserverとは?★★
}
}
ここで終わりかと思いきや、まだです。mObserverとは何者でしょうか?メッセージの冒険は続きます。
コメント一覧
- コメントはありません。
この記事にコメントする
2017年11月7日
Androidメディア処理 - mObserverの中身
目次: Android
昨日(2017年11月6日の日記参照)の続きです。
メッセージの宛先
メッセージがOMXNodeInstance::onMessages() 関数にたどり着き、次にOMXNodeInstance::mObserverに渡されていることはわかりましたが、これは一体何者でしょうか?
observerとは?
//android/frameworks/av/media/libstagefright/include/OMXNodeInstance.h
struct OMXNodeInstance {
...
private:
...
sp<IOMXObserver> mObserver;
//android/frameworks/av/media/libstagefright/omx/OMXNodeInstance.cpp
OMXNodeInstance::OMXNodeInstance(
OMX *owner, const sp<IOMXObserver> &observer, const char *name)
: mOwner(owner),
mNodeID(0),
mHandle(NULL),
mObserver(observer), //★★コンストラクタの2番目の引数observerで初期化している★★
mDying(false),
mSailed(false),
mQueriedProhibitedExtensions(false),
mBufferIDCount(0)
{
//android/frameworks/av/media/libstagefright/omx/OMX.cpp
status_t OMX::allocateNode(
const char *name, const sp<IOMXObserver> &observer,
sp<IBinder> *nodeBinder, node_id *node) {
...
OMXNodeInstance *instance = new OMXNodeInstance(this, observer, name); //★★allocateNodeの2番目の引数observerを渡している★★
残念ながらallocateNode() の引数がわからないため、observerに何が指定されているかわかりません。
allocateNodeのobserverにたどり着くのは大変
//android/frameworks/av/media/libstagefright/ACodec.cpp
bool ACodec::UninitializedState::onAllocateComponent(const sp<AMessage> &msg) {
...
OMXClient client; //★★binderのクライアント★★
if (client.connect() != OK) { //★★デコーダは別プロセスで実行されているので、接続する★★
mCodec->signalError(OMX_ErrorUndefined, NO_INIT);
return false;
}
...
sp<IOMX> omx = client.interface(); //★★binderを使って通信するためのインタフェース★★
//android/frameworks/av/media/libstagefright/OMXClient.cpp
class OMXClient {
public:
OMXClient();
status_t connect();
void disconnect();
sp<IOMX> interface() {
return mOMX; //★★インタフェースはこれ★★
}
//android/frameworks/av/media/libstagefright/OMXClient.cpp
status_t OMXClient::connect() {
sp<IServiceManager> sm = defaultServiceManager();
sp<IBinder> playerbinder = sm->getService(String16("media.player"));
sp<IMediaPlayerService> mediaservice = interface_cast<IMediaPlayerService>(playerbinder);
...
sp<IOMX> mediaServerOMX = mediaservice->getOMX();
...
sp<IBinder> codecbinder = sm->getService(String16("media.codec"));
sp<IMediaCodecService> codecservice = interface_cast<IMediaCodecService>(codecbinder);
...
sp<IOMX> mediaCodecOMX = codecservice->getOMX();
...
mOMX = new MuxOMX(mediaServerOMX, mediaCodecOMX); //★★インタフェースはここで設定している★★
return OK;
}
なかなか複雑ですね。このインタフェースとやらの実体はMuxOMXだと思われます。
allocateNodeのobserver
//android/frameworks/av/media/libstagefright/ACodec.cpp
bool ACodec::UninitializedState::onAllocateComponent(const sp<AMessage> &msg) {
...
sp<IOMX> omx = client.interface(); //★★MuxOMXのオブジェクトのはず★★
...
sp<CodecObserver> observer = new CodecObserver; //★★たぶんこれがobserver★★
IOMX::node_id node = 0;
status_t err = NAME_NOT_FOUND;
for (size_t matchIndex = 0; matchIndex < matchingCodecs.size();
++matchIndex) {
componentName = matchingCodecs[matchIndex];
quirks = MediaCodecList::getQuirksFor(componentName.c_str());
pid_t tid = gettid();
int prevPriority = androidGetThreadPriority(tid);
androidSetThreadPriority(tid, ANDROID_PRIORITY_FOREGROUND);
err = omx->allocateNode(componentName.c_str(), observer, &mCodec->mNodeBinder, &node); //★★ここでobserverをMuxOMX::allocateNodeに渡す★★
//android/frameworks/av/media/libstagefright/OMXClient.cpp
status_t MuxOMX::allocateNode(
const char *name, const sp<IOMXObserver> &observer,
sp<IBinder> *nodeBinder,
node_id *node) {
...
sp<IOMX> omx;
node_location loc = getPreferredCodecLocation(name);
if (loc == CODECPROCESS) {
omx = mMediaCodecOMX;
} else if (loc == MEDIAPROCESS) {
omx = mMediaServerOMX;
} else {
if (mLocalOMX == NULL) {
mLocalOMX = new OMX;
}
omx = mLocalOMX;
}
status_t err = omx->allocateNode(name, observer, nodeBinder, node); //★★OMX::allocateNode() などに渡す★★
ALOGV("allocated node_id %x on %s OMX", *node, omx == mMediaCodecOMX ? "codecprocess" :
omx == mMediaServerOMX ? "mediaserver" : "local");
突然、ここで三択(mMediaCodecOMXとmMediaServerOMXとmLocalOMX)になりますが、いずれの選択肢を選んでも、渡すobserverは変わらずCodecObserverのはずです。それさえわかれば、とりあえずOKです。
コメント一覧
- コメントはありません。
この記事にコメントする
2017年11月8日
Androidメディア処理 - mObserverからmNotifyへ
目次: Android
昨日(2017年11月7日の日記参照)の続きです。
どうもAndroidのメッセージシステムのたらい回しが激しすぎて、話が一向に進みません。本来見たかった道をざっくりまとめておくと、
- デコード終わり
- コールバックOMXNodeInstance::OnFillBufferDone()
- instance->owner()->OnFillBufferDone() → OMX::OnFillBufferDone()
- OMX::CallbackDispatcher::post()
これが2017年11月6日の日記の前半部分です。post()によってメッセージがキューに追加されます。
- OMX::CallbackDispatcher::loop()
- OMX::CallbackDispatcher::dispatch()
- mOwner->onMessages() → OMXNodeInstance::onMessages()
- mObserver->onMessages() → ?
これが2017年11月6日の日記の後半部分です。キューに追加されたメッセージは別スレッドで処理され、mObserverなるものに渡されていました。
- mObserver->onMessages() → CodecObserver::onMessages()
そして2017年11月7日の日記を丸々使い、OMXNodeInstance::mObserverの正体がCodecObserverだと思われるところまで来ました。
やっと来たobserver
//android/frameworks/av/media/libstagefright/ACodec.cpp
struct CodecObserver : public BnOMXObserver {
...
// from IOMXObserver
virtual void onMessages(const std::list<omx_message> &messages) {
...
sp<AMessage> notify = mNotify->dup();
bool first = true;
sp<MessageList> msgList = new MessageList();
for (std::list<omx_message>::const_iterator it = messages.cbegin();
it != messages.cend(); ++it) {
const omx_message &omx_msg = *it;
if (first) {
notify->setInt32("node", omx_msg.node);
first = false;
}
sp<AMessage> msg = new AMessage;
//★★omx_msg.typeはOMX::OnFillBufferDone() にてFILL_BUFFER_DONEに設定★★
msg->setInt32("type", omx_msg.type);
switch (omx_msg.type) {
...
case omx_message::FILL_BUFFER_DONE:
{
//★★omx_messageからAMessageに変換している★★
msg->setInt32(
"buffer", omx_msg.u.extended_buffer_data.buffer);
msg->setInt32(
"range_offset",
omx_msg.u.extended_buffer_data.range_offset);
msg->setInt32(
"range_length",
omx_msg.u.extended_buffer_data.range_length);
msg->setInt32(
"flags",
omx_msg.u.extended_buffer_data.flags);
msg->setInt64(
"timestamp",
omx_msg.u.extended_buffer_data.timestamp);
msg->setInt32(
"fence_fd", omx_msg.fenceFd);
break;
}
...
}
msgList->getList().push_back(msg);
}
notify->setObject("messages", msgList);
notify->post(); //★★notifyとは??★★
}
また変なものが出てきました。notify = mNotify->dup()なので、次にmNotifyが何者かを見ていきます。
今度はnotify
//android/frameworks/av/media/libstagefright/ACodec.cpp
struct CodecObserver : public BnOMXObserver {
...
void setNotificationMessage(const sp<AMessage> &msg) {
mNotify = msg;
}
bool ACodec::UninitializedState::onAllocateComponent(const sp<AMessage> &msg) {
...
sp<CodecObserver> observer = new CodecObserver;
IOMX::node_id node = 0;
...
status_t err = NAME_NOT_FOUND;
for (size_t matchIndex = 0; matchIndex < matchingCodecs.size();
++matchIndex) {
componentName = matchingCodecs[matchIndex];
quirks = MediaCodecList::getQuirksFor(componentName.c_str());
pid_t tid = gettid();
int prevPriority = androidGetThreadPriority(tid);
androidSetThreadPriority(tid, ANDROID_PRIORITY_FOREGROUND);
err = omx->allocateNode(componentName.c_str(), observer, &mCodec->mNodeBinder, &node); //★★11月7日の日記参照★★
...
notify = new AMessage(kWhatOMXMessageList, mCodec);
observer->setNotificationMessage(notify); //★★ここで設定している★★
従ってmNotifyはAMessage(kWhatOMXMessageList, mCodec)です。dup()は複製しているだけでしょうから、notify->post()はAMessage::post()が呼ばれるのでしょう。
今度はAMessage
//android/frameworks/av/media/libstagefright/foundation/AMessage.cpp
status_t AMessage::post(int64_t delayUs) {
sp<ALooper> looper = mLooper.promote();
if (looper == NULL) {
ALOGW("failed to post message as target looper for handler %d is gone.", mTarget);
return -ENOENT;
}
looper->post(this, delayUs); //★★たらい回し再び、mLooperとは?★★
return OK;
}
...
AMessage::AMessage(uint32_t what, const sp<const AHandler> &handler)
: mWhat(what),
mNumItems(0) {
setTarget(handler); //★★mLooperはここから設定★★
}
...
void AMessage::setTarget(const sp<const AHandler> &handler) {
if (handler == NULL) {
mTarget = 0;
mHandler.clear();
mLooper.clear();
} else {
mTarget = handler->id();
mHandler = handler->getHandler();
mLooper = handler->getLooper(); //★★mLooperはAMessageコンストラクタの2番目の引数のgetLooper() が返す値★★
}
}
うーん、また訳の分からないものが出てきましたね…。
コメント一覧
- コメントはありません。
この記事にコメントする
2017年11月9日
Androidメディア処理 - ALooperで行き詰った
目次: Android
昨日(2017年11月8日の日記参照)の続きです。
本来見たかった道をざっくりまとめておくと、
- デコード終わり
- コールバックOMXNodeInstance::OnFillBufferDone()
- instance->owner()->OnFillBufferDone() → OMX::OnFillBufferDone()
- OMX::CallbackDispatcher::post()
これが2017年11月6日の日記の前半で分かった部分。
- OMX::CallbackDispatcher::loop()
- OMX::CallbackDispatcher::dispatch()
- mOwner->onMessages() → OMXNodeInstance::onMessages()
- mObserver->onMessages() → ?
これが2017年11月6日の日記の後半で分かった部分。
- mObserver->onMessages() → CodecObserver::onMessages()
これが2017年11月7日の日記で分かった部分。
- mObserver->onMessages() → CodecObserver::onMessages()
- notify->post() → AMessage::post()
- looper->post() → ?
これが2017年11月8日の日記で分かった部分です。そのあとはlooperとは何ぞや?という点を追いかけていましたが、まだわからない状態です。
- looper->post() → ?
- looper = AMessage::mLooper
- mLooper = handler->getLooper()
- handlerはAMessage() の2番目の引数
- notify = mNotify = AMessage(kWhatOMXMessageList, mCodec) だから、handler = ACodec::BaseState::mCodec
- looper->post() → mCodec->getLooper()->post() のはず
再開
肝心のACodec::BaseState::mCodecに何が入っているのか?についてはUninitializedStateを手掛かりに見ていきます。
mCodec
//android/frameworks/av/media/libstagefright/ACodec.cpp
struct ACodec::BaseState : public AState {
BaseState(ACodec *codec, const sp<AState> &parentState = NULL);
...
ACodec *mCodec; //★★これが知りたい★★
//★★UninitializedStateを手掛かりに見てみる★★
struct ACodec::UninitializedState : public ACodec::BaseState {
...
ACodec::UninitializedState::UninitializedState(ACodec *codec)
: BaseState(codec) { //★★BaseStateに丸投げ★★
}
//★★BaseStateを見てみる★★
struct ACodec::BaseState : public AState {
BaseState(ACodec *codec, const sp<AState> &parentState = NULL);
...
ACodec::BaseState::BaseState(ACodec *codec, const sp<AState> &parentState)
: AState(parentState),
mCodec(codec) { //★★引数をそのまま設定しているだけ★★
}
//★★UninitializedStateの生成個所を探す★★
ACodec::ACodec()
: mQuirks(0),
...
mDescribeHDRStaticInfoIndex((OMX_INDEXTYPE)0) {
mUninitializedState = new UninitializedState(this); //★★thisが指すものはACodec★★
mLoadedState = new LoadedState(this);
つまりACodec::BaseState::mCodecは、UninitializeStateを生成したACodecです。もう一つの謎getLooper()が何を返すのか?も見てみます。
getLooper
//android/frameworks/av/include/media/stagefright/foundation/AHandler.h
struct AHandler : public RefBase {
...
wp<ALooper> getLooper() const {
return mLooper; //★★mLooperを返すだけ★★
}
...
inline void setID(ALooper::handler_id id, wp<ALooper> looper) {
mID = id;
mLooper = looper; //★★mLooperはsetIDの引数そのまま★★
}
//android/frameworks/av/include/media/libstagefright/foundation/ALooperRoster.cpp
ALooper::handler_id ALooperRoster::registerHandler(
const sp<ALooper> looper, const sp<AHandler> &handler) {
Mutex::Autolock autoLock(mLock);
if (handler->id() != 0) {
CHECK(!"A handler must only be registered once.");
return INVALID_OPERATION;
}
HandlerInfo info;
info.mLooper = looper;
info.mHandler = handler;
ALooper::handler_id handlerID = mNextHandlerID++;
mHandlers.add(handlerID, info);
handler->setID(handlerID, looper); //★★setIDを呼んでいる個所はここだけ★★
return handlerID;
}
//media/libstagefright/foundation/ALooper.cpp
ALooperRoster gLooperRoster;
...
ALooper::handler_id ALooper::registerHandler(const sp<AHandler> &handler) {
return gLooperRoster.registerHandler(this, handler);
}
ALooper::registerHandlerはALooperをAHandlerに登録する仕組み、AHandler::getLooper()はAHandlerに登録されたALooperを返す仕組みのようです。取得/設定が一致しないのでややこしいです。設計を失敗したのかなあ?
例えばAHandler *hogeとALooper *fugaがあってfuga->registerHandler(hoge)としたならば、hoge->getLooper()は先ほど登録したfugaを返します。
- looper->post() → ?
- looper = AMessage::mLooper
- mLooper = handler->getLooper()
- handlerはAMessage() の2番目の引数
- notify = mNotify = AMessage(kWhatOMXMessageList, mCodec) だから、handler = ACodec::BaseState::mCodec
- looper->post() → mCodec->getLooper()->post() のはず
- ACodec::BaseState::mCodecは、UninitializeStateを生成したACodecだから
- looper->post() → ACodec::getLooper()->post() のはず
ちなみにACodecはAHandlerを継承しているのでgetLooper()関数を持っています。
ここまで分かればALooper::registerHandler()を呼んでいる個所を見て、引数がACodecオブジェクトであろう場所を見つければ、looperが指すのはどのALooperなのか?がやっと判明します。
しかしregisterHandler()の呼び出し箇所は非常に多くて、追いきれません。うーん、別のアプローチが必要でしょうか……?
コメント一覧
- コメントはありません。
この記事にコメントする
2017年11月11日
ポケモンGO
目次: ゲーム
ポケモンGOのアプリはいつまで経ってもバグだらけです。新しく実装された機能(ジムバトル)は当然バグバグで、通信周りが弱くハングしまくります。
- ジムで木の実投げるときにジムから離れると操作不能
- 木の実を投げたときに対象のポケモンが別のプレーヤに倒されると操作不能
- ジムバトルの開始時にハング、勝利時にもハング
- ログイン画面でWiFiから3G/4Gに切り換えるとログイン不能
- ポケモン捕獲時にハングする
- キャラクターが真っ黒になる
- 地図が一面海になる
操作不能になったり、ハングされたりするとアプリを再起動するしかないですが、ハイエンド機じゃないせいか起動も動作も遅くてイライラします。
1日15分もやってないのにこの有様なので、もっと長時間遊んでいる人はイライラで憤死するんじゃなかろうか?
折角面白いのにアプリが残念すぎる……。
コメント一覧
- コメントはありません。
この記事にコメントする
2017年11月12日
Kindle Fireの変なフォントが直っていた
目次: Kindle
いつのまにかKindleがアップデートされており、フォントが変になる問題(2017年10月13日の日記参照)が直っていました。あとストアアプリのメニューがダブって表示される問題(2017年10月12日の日記参照)も直っていました。
直してくれてありがとう。やっぱりおかしいってわかってたんだね……。
コメント一覧
- コメントはありません。
この記事にコメントする
2017年11月13日
テレビの栄枯盛衰
一応、テレビ向けのSoCを作るお仕事をしていますので、たまに電器屋さんにテレビを見に行ってますが、どこに行ってもテレビのコーナーは年々狭くなっています。
土曜日に梅田ヨドバシに行きましたが、一時期は3Fをテレビが支配していたのに、今や1/3位です。ホームシアターを除いて純粋にテレビだけでカウントしたら、もっと狭いかもしれません。テレビを家電の1つと見れば、フロアの1/3を占めているのは破格の待遇と言えますが、つい過去の栄光と比べてしまいます。
同じ階にはオーディオコーナーと、キャンプ用品コーナーがありました。テレビはオーディオコーナーと同じか、やや負けてるくらいの広さでしょうか?この先、テレビの面積が復活することは無いでしょうから、そのうちオーディオと合併して、オーディオ・ビジュアルコーナーになるんでしょう、たぶん。
レコーダーはどこ?
レコーダーは悲惨で棚2つしかありませんでした。BD-RとかDVD-Rみたいなメディアそのものを売っている棚の方が多いように見えますけど、バランスおかしくないです??
番組を録画する文化は日本特有らしく、もともとレコーダーは日本でしか流行っていません。海外でも販売していますが、プレーヤーの方が好まれるようです。頼みの日本がこの状態だと、そのうちレコーダーという製品は無くなるかもしれません。
プレーヤーは細々と続くと思います。とはいえ、黒物家電メーカーは全員ボロボロで、次世代の光ディスク規格を作るほどの元気は無いでしょう。BDを8K規格まで延命して、ネットにバトンタッチして終わりか、下手したら4Kで燃え尽きて終わりかもね……。
コメント一覧
- コメントはありません。
この記事にコメントする
2017年11月22日
アイス履歴
アイス履歴を10個ほど増やしました(リンク)。これで55種類かな。そろそろカウントが面倒になってきました…。
最近はパピコやモナカのような棒アイス以外にも手を出しているので、アイスの袋の増え方が激しくアップロードしきれていません。そのうち載せます。
夏、秋は果実系のさわやかなアイスがおいしい季節でしたが、冬は味濃い系が恋しくなります。個人的にまた発売してほしいなー、と思うアイスは、
- 赤城乳業 ミルクレア スイーツ ラムレーズン
- 明治 ゴールドライン フランボワーズ
- ロッテ カスタードとろけるほろにがカラメルのプリンアイスバー
辺りですね。他のアイスもおいしいです。ぜひ見かけたら食べてみてください、と言いたいところですが、アイスは商品の入れ替わりが激しくて、すぐにお店から消えるんですよねえ……。
その反面、アイスはほぼ毎週と言って良いほど、新商品が出ていてマンネリとは無縁です。メーカーさんの努力は素晴らしいです。
コメント一覧
- コメントはありません。
この記事にコメントする
2017年11月24日
モナコイン
目次: ベンチマーク
仮想通貨の勉強がてら、モナコイン(以外の仮想通貨にも対応してますが)のマイナーcpuminer-multiを見ていました。かなり最適化されていて、迂闊にSSEを使うと逆に遅くなるほどです。面白いです。
モナコインのハッシュアルゴリズムはLyra2REv2という名前の256ビットハッシュ関数で、複数のハッシュ関数の組み合わせでできています。
- blake
- keccak
- cubehash
- LYRA2
- skein
- cubehash(2回目)
- bmw
上から順に実行されます。先頭のblakeへの入力は80バイトで、出力は32バイト。1つ前のハッシュ関数の出力が、2番目以降のハッシュ関数の入力となります。LYRA2だけパラメータが2つ(saltとpassword)必要ですが、どちらも同じ値を指定していました。
Lyra2REv2をCPUで演算する場合CubeHashに一番時間が掛かります。2回実行されることを差し引いて考えても遅いです。見ていると最終ラウンドが160回という設定になっていて、これが異常に遅いみたいです。
実装(=cpuminer-multiの最適化された実装)を見ると、このハッシュ関数は4ワードと別の4ワードをペアにして演算をします。ワーク領域は32ワードありますので、同じ演算が4回実行されます。いかにもSSEに向いていそうな処理ですが、4ワードの組み合わせ方が変わるので、SSEレジスタにうまくパッキングできません。
- (EVENラウンド)
- 加算★
- 左ローテート
- XOR★
- 2ワードずらして加算
- 左ローテート
- 2ワードずらしてXOR
- (ODDラウンド)
- 逆順で加算
- 左ローテート
- 逆順でXOR
- 逆順2ワードずらして加算
- 左ローテート
- 逆順2ワードずらしてXOR
試しに★の部分だけ、単純にSSEを使ったら、余計遅くなりました。切ない。どうもSSEレジスタからのロード/ストアで引っかかって遅くなっているようです。しかしSSEには左ローテート演算がないため、左ローテートの前に必ずストアしなければなりません。
EVEN + ODDのラウンドが8回繰り返されますが、安易にunrollingしても(※)やはり遅くなります。unrollingした後のマシン語を見ると嫌になるくらい長いので、命令キャッシュのヒット率が落ちてるのかな?
うーん、難しいです……。
(※)私が何かしたわけではなくcpuminer-multiにはunrollingするコンパイルオプションが用意されていて、それを使ってみただけです。CubeHash以外のハッシュ関数もunrollingするかしないかを選べます。素敵な作りです。
CubeHash
そもそもCubeHashって何なのか全く知らないので調べてみました。Wikipediaの解説(リンク)がとても親切です。CubeHashはNISTのハッシュ関数コンペに応募されたものなのだとか。次のSHAなんちゃらに採用されるかもしれないですね。
CubeHashにはパラメータがあり、パラメータが違うと全く違うハッシュ関数になります。Lyra2REv2で使用しているのはどれ、という情報が見当たらなかったのですが、cpuminer-multiの実装(初期ラウンドは不明ですが、1周16ラウンド、ブロックサイズ32ビット、最終160ラウンド、ハッシュ長256ビット)から推測するにCubeHash160+16/32+160-256じゃないか?と思われます。長い名前だなあ……。
キューブは4個あって、i, jの2次元で指定されます。i, jは0か1の値しかとりません。
キューブは8個のブロックから構成されk, l, mの3次元で指定されます。k, l, mも0か1の値しか取りません。
ブロックは32ビットです…、というよりLyra2REv2のCubeHashの場合は32ビット、と言った方が正しいですね。
従って、全体で4 * 8 = 32個のブロックが存在します。Wikipediaの図ではi, j, k, l, mという5次元のアドレスで表現していますが、計算の際はi, j, k, l, mをくっつけて2進数だと思って数値に変換します。
例えば、右下のキューブ(i = 1, j = 0)、右上の手前側ブロック(k = 1, l = 1, m = 0)だったら、ijklm = 10110 = 22になりま…、はい?わかりづらい?
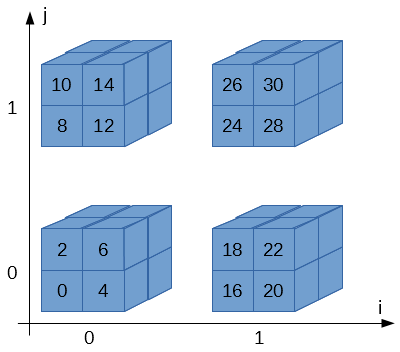
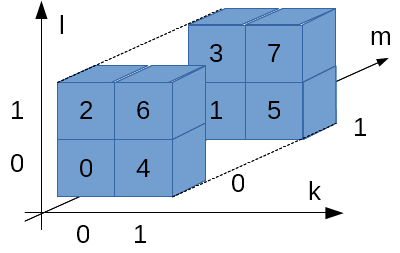
これでわかりやすい?
CubeHashの素朴な実装
Wikipediaに載っている実装をそのまま実装すれば良いです。と言われてやる人は居ませんから、自分でやってみます。
アルゴリズムだけ実装しても、結果を確かめる術がないのでcpuminer-multiに組み込める形で実装します。sha3/sph_cubehash.cにSIXTEEN_ROUNDSというマクロがあって、CubeHashの1周(16ラウンド)に相当しています。このマクロを改造して自作の実装を差し込みます。
CubeHashの素朴な実装、準備編
#if 1 //今から作る実装を無理やり有効にする
#define SIXTEEN_ROUNDS do { \
int j; \
for (j = 0; j < 16; j ++) { \
ROUND_ONE; \
} \
} while (0)
#elif SPH_CUBEHASH_UNROLL == 2 //#ifを #elifに変えてしまう(SPH_CUBEHASH_UNROLLオプションを無視)
#define SIXTEEN_ROUNDS do { \
int j; \
for (j = 0; j < 8; j ++) { \
ROUND_EVEN; \
ROUND_ODD; \
} \
} while (0)
次にラウンドの処理を書きます。Wikipediaを見ながら10個の手順をそのまま書きます。
CubeHashの素朴な実装
void sw(uint32_t *a, uint32_t *b)
{
uint32_t tmp = *b;
*b = *a;
*a = tmp;
}
#define ROUND_ONE do { \
int i; \
uint32_t *b = (sc)->state; \
/* STEP 1, 2 */ \
for (i = 0; i < 16; i++) { \
b[i + 16] += b[i]; \
b[i] = ROTL32(b[i], 7); \
} \
/* STEP 3 */ \
for (i = 0; i < 8; i++) { \
sw(&b[i], &b[i + 8]); \
} \
/* STEP 4 */ \
for (i = 0; i < 16; i++) \
b[i] ^= b[i + 16]; \
/* STEP 5 */ \
for (i = 0; i < 4; i++) { \
sw(&b[16 + i * 4], &b[18 + i * 4]); \
sw(&b[17 + i * 4], &b[19 + i * 4]); \
} \
/* STEP 6, 7 */ \
for (i = 0; i < 16; i++) { \
b[i + 16] += b[i]; \
b[i] = ROTL32(b[i], 11); \
} \
/* STEP 8 */ \
for (i = 0; i < 4; i++) { \
sw(&b[0 + i], &b[4 + i]); \
sw(&b[8 + i], &b[12 + i]); \
} \
/* STEP 9 */ \
for (i = 0; i < 16; i++) \
b[i] ^= b[i + 16]; \
/* STEP 10 */ \
for (i = 0; i < 4; i++) { \
sw(&b[16 + i * 4], &b[17 + i * 4]); \
sw(&b[18 + i * 4], &b[19 + i * 4]); \
} \
} while (0)
コンパイルして動けばOKです。
実行例
$ ./cpuminer -a lyra2rev2 -t 1 --benchmark ** cpuminer-multi 1.3.3 by tpruvot@github ** BTC donation address: 1FhDPLPpw18X4srecguG3MxJYe4a1JsZnd (tpruvot) [2017-11-24 20:25:06] 1 miner threads started, using 'lyra2rev2' algorithm. [2017-11-24 20:25:07] CPU #0: 68.54 kH/s [2017-11-24 20:25:07] Total: 68.54 kH/s [2017-11-24 20:25:11] Total: 80.77 kH/s [2017-11-24 20:25:16] CPU #0: 80.76 kH/s [2017-11-24 20:25:16] Total: 80.76 kH/s
もし高速化に挑むのであれば、ハッシュ関数の出力する結果が合っているかどうかも見た方が良いです。基本的には、変更前の結果と比べて同じかどうかをチェックします。まあ、マイニングプールに繋いでみてacceptが返ることでも確かめられますけど、マイニングプールに迷惑なのでほどほどにね……。
コンパイラの本気を見よ
この素朴な実装はとても遅いです。我が家のマシン(AMD A10-7800/3.5GHz)では、最適化レベルが -O2でも33kH/s程度しか出ません。cpuminer-multiの元々の実装(unrolling = 2)は80〜81kH/sくらいなので、天と地ほどの差があります。
元のcpuminer-multiの実装が速い理由は、ラウンドのswap処理を手動で解決し、2ラウンド分をunrollingしているからだと思われます。swapを手動展開するところで、記号の意味が訳わからなくなってしまうため、読むのはだいぶキツいものがあります。
ところがそこまでしなくても、実は -Ofast -march=nativeで最適化を掛けると79〜80kH/s程度と、かなり近い速度が出せてしまいます。出力されたコードはSSEによるベクタ化や命令並べ替えの多発で、人間には理解不能な感じになっちゃってますが、まーとにかく速いです。コンパイラの本気を見た気がしますね。
コメント一覧
- すずきさん(2017/11/26 17:09)
SHA-3 はもう決定していて、keccak が採用されたそうです。
Wikipedia をちゃんと読んだら 「CubeHash は 2回戦までは行ったが、最終選考の 5つに残れなかった」と書いてありました。
この記事にコメントする
2017年11月26日
仮想通貨とマイニング
目次: ベンチマーク
マイニングは仮想通貨の決済システムを支える大事な計算のようです。仮想通貨のシステム維持に協力してくれてありがとう、という意味を込めてマイニングした人にはボーナスが与えられているんですね。
私も最初マイニングという単語から、仮想通貨が地面から沸いてくるようなイメージを持っていましたが、決してそんなことはなくて、マイニングには高いコスト、つまり、計算するハードの初期投資と維持する電気代が掛かっています。
日本は電気代が高くて、維持費と得られる仮想通貨の量(を日本円換算した額)が、割に合わないです。
もしモナコインを使ってみたいだけなら、日本円と仮想通貨を交換してくれるところから得るのが一番楽だと思います。仮想通貨を手に入れる手段として、マイニングはあまり効率が良いとは思いません。無駄に時間と金が掛かるだけです。もちろんマイニング自体に興味がある人は別ですよ。
先日私が調べていたCPUマイニング(2017年11月24日の日記参照)ではかなり「ハッシュ数/電力」の効率が悪く、マイニングの手法としては、ほぼ意味がありません。
現在Lyra2REv2はGPUマイニングが主流のようです。私もccminerというCUDAを使ったマイナーを試しています。ローエンドGeForce GT 1030 1枚ですら6MH/sで、CPUの100倍くらいの速度です。すごいね、GPUって。
それでもマイニングするには貧弱な計算力なので、GPU数枚程度ならマイニングプールを使うことになると思います。
メモ: 技術系の話はFacebookから転記しておくことにした。
コメント一覧
- コメントはありません。
この記事にコメントする
2017年11月30日
モナコインとCubeHash
目次: ベンチマーク
先日(2017年11月24日の日記参照)CPUによるモナコインのマイニングcpuminer-multiについて調べました。先日の成果としては、
- CubeHashというハッシュ関数がとびきり時間が掛かっている
- cpuminer-multiは既に手動で最適化されている
- CubeHashを素朴に実装したら遅い
- 素朴な実装でもコンパイラの最適化でcpuminer-multiの実装と同等の速度が出る
CubeHashを適当にSSE化して遊んでいたところ、基本的には非常に遅く(改変前80kH/s、改変後30〜60kH/s)なりますが、突然100kH/sに速くなるポイントがありました。なお、我が家のマシンはAMD A10-7800/3.5GHzです。
コンパイラの本気
急激に速くなった理由はおそらくコンパイラです。
途中までしかSSE化していないはずなのに、逆アセンブラで見ると1ラウンドが全てベクタ演算命令で記述されていること、また、コンパイラの最適化レベルを変えずに(Ofast)、ベクタ最適化だけ無効にすると、速度が67kH/sに落ちることから、
- 私が中途半端にSSEを使った
- 変数間の依存性か何かが途切れた
- コンパイラが残りの部分を全部ベクタ化できると判断
- 1ラウンド全てSSE or AVX化された
このようなメカニズムだろうと思っています。
平たく言えばコンパイラが本気出していなかっただけですね。1ラウンドを全てベクタ演算化すると、なんと120kH/s も速度が出ました。
元のコードの1.5倍の速度を拝めるとは思ってもいませんでした。何でもやってみるものですね!
Intel Intrinsics
SSE化にはIntel Intrinsics(マニュアル)を使いました、というより、Intrinsicが無かったらSSE化をしようと思わないです。
Intrinsicはかなり強引ですけど、一応Cの関数として定義されており、人間が考えると面倒なこと(SSEレジスタ割り当て、退避など)は全てコンパイラがやってくれるため、大変便利です。
インラインアセンブラの一種とも言えますが、gccのインラインアセンブラほど苦痛はありません。SSE/AVXを使いたいだけならIntrinsicがおススメです。
手で頑張ってみよう
最初CubeHashのSTEP5(キューブの上面と下面の入れ替え操作)をシフトとORで計算していたのですが、コンパイラが出す命令を見ていたらshuffleという素敵な命令を使っていたので、そっちで書き直してみました。
コンパイラ任せでも良いのですが、せっかく途中まで書いたので、全部SSE化しました。BeforeとAfterはこんな感じです。
SSE2を使ったCubeHashの素朴な実装
#define SSE_ROTL(x, n) do { \
__m128i mw0, mw1; \
mw0 = _mm_slli_epi32((x), (n)); \
mw1 = _mm_srli_epi32((x), 32 - (n)); \
x = _mm_or_si128(mw0, mw1); \
} while (0);
#define SSE_SWP(a, b) do { \
__m128i mw; \
mw = b; \
b = a; \
a = mw; \
} while (0);
#define ROUND_ONE do { \
__m128i mx0, mx4, mx8, mxc; \
__m128i mxg, mxk, mxo, mxs; \
mx0 = _mm_load_si128((void *)&x0); \
mx4 = _mm_load_si128((void *)&x4); \
mx8 = _mm_load_si128((void *)&x8); \
mxc = _mm_load_si128((void *)&xc); \
mxg = _mm_load_si128((void *)&xg); \
mxk = _mm_load_si128((void *)&xk); \
mxo = _mm_load_si128((void *)&xo); \
mxs = _mm_load_si128((void *)&xs); \
/* STEP1 */ \
mxg = _mm_add_epi32(mx0, mxg); \
mxk = _mm_add_epi32(mx4, mxk); \
mxo = _mm_add_epi32(mx8, mxo); \
mxs = _mm_add_epi32(mxc, mxs); \
/* STEP2 */ \
SSE_ROTL(mx0, 7); \
SSE_ROTL(mx4, 7); \
SSE_ROTL(mx8, 7); \
SSE_ROTL(mxc, 7); \
/* STEP3 */ \
SSE_SWP(mx0, mx8); \
SSE_SWP(mx4, mxc); \
/* STEP4 */ \
mx0 = _mm_xor_si128(mx0, mxg); \
mx4 = _mm_xor_si128(mx4, mxk); \
mx8 = _mm_xor_si128(mx8, mxo); \
mxc = _mm_xor_si128(mxc, mxs); \
/* STEP5 */ \
mxg = _mm_shuffle_epi32(mxg, 0x4e); \
mxk = _mm_shuffle_epi32(mxk, 0x4e); \
mxo = _mm_shuffle_epi32(mxo, 0x4e); \
mxs = _mm_shuffle_epi32(mxs, 0x4e); \
/* STEP6 */ \
mxg = _mm_add_epi32(mx0, mxg); \
mxk = _mm_add_epi32(mx4, mxk); \
mxo = _mm_add_epi32(mx8, mxo); \
mxs = _mm_add_epi32(mxc, mxs); \
/* STEP7 */ \
SSE_ROTL(mx0, 11); \
SSE_ROTL(mx4, 11); \
SSE_ROTL(mx8, 11); \
SSE_ROTL(mxc, 11); \
/* STEP8 */ \
SSE_SWP(mx0, mx4); \
SSE_SWP(mx8, mxc); \
/* STEP9 */ \
mx0 = _mm_xor_si128(mx0, mxg); \
mx4 = _mm_xor_si128(mx4, mxk); \
mx8 = _mm_xor_si128(mx8, mxo); \
mxc = _mm_xor_si128(mxc, mxs); \
/* STEP10 */ \
mxg = _mm_shuffle_epi32(mxg, 0xb1); \
mxk = _mm_shuffle_epi32(mxk, 0xb1); \
mxo = _mm_shuffle_epi32(mxo, 0xb1); \
mxs = _mm_shuffle_epi32(mxs, 0xb1); \
_mm_store_si128((void *)&x0, mx0); \
_mm_store_si128((void *)&x4, mx4); \
_mm_store_si128((void *)&x8, mx8); \
_mm_store_si128((void *)&xc, mxc); \
_mm_store_si128((void *)&xg, mxg); \
_mm_store_si128((void *)&xk, mxk); \
_mm_store_si128((void *)&xo, mxo); \
_mm_store_si128((void *)&xs, mxs); \
} while (0)
前回と同様にcpuminer-multiのマクロにはめ込めるように実装しています。
実行例
$ ./cpuminer -a lyra2rev2 -t 1 --benchmark ** cpuminer-multi 1.3.3 by tpruvot@github ** BTC donation address: 1FhDPLPpw18X4srecguG3MxJYe4a1JsZnd (tpruvot) [2017-12-01 02:21:05] 1 miner threads started, using 'lyra2rev2' algorithm. [2017-12-01 02:21:06] CPU #0: 140.04 kH/s [2017-12-01 02:21:06] Total: 140.04 kH/s [2017-12-01 02:21:10] Total: 145.47 kH/s [2017-12-01 02:21:15] CPU #0: 145.32 kH/s [2017-12-01 02:21:15] Total: 145.32 kH/s
CubeHashの最終160ラウンドは一番のボトルネックだった個所だけあって、改善効果はかなり大きいですね。
コメント一覧
- AVXならこんな感じ?さん(2018/01/23 09:38)
/* STEP1 */ \
mxg = _mm256_add_epi32(mx0, mxg); \
mxo = _mm256_add_epi32(mx8, mxo); \
/* STEP2 */ \
AVX_ROTL(mx0, 7); \
AVX_ROTL(mx8, 7); \
/* STEP3 */ \
AVX_SWP(mx0, mx8); \
/* STEP4 */ \
mx0 = _mm256_xor_si256(mx0, mxg); \
mx8 = _mm256_xor_si256(mx8, mxo); \
/* STEP5 */ \
mxg = _mm256_permute4x64_epi64(mxg, 0xb1); \
mxo = _mm256_permute4x64_epi64(mxo, 0xb1); \
/* STEP6 */ \
mxg = _mm256_add_epi32(mx0, mxg); \
mxo = _mm256_add_epi32(mx8, mxo); \
/* STEP7 */ \
AVX_ROTL(mx0, 11); \
AVX_ROTL(mx8, 11); \
/* STEP8 */ \
mx0 = _mm256_permute4x64_epi64(mx0, 0x4e); \
mx8 = _mm256_permute4x64_epi64(mx8, 0x4e); \
/* STEP9 */ \
mx0 = _mm256_xor_si256(mx0, mxg); \
mx8 = _mm256_xor_si256(mx8, mxo); \
/* STEP10 */ \
mxg = _mm256_shuffle_epi32(mxg, 0xb1); \
mxo = _mm256_shuffle_epi32(mxo, 0xb1); \ - すずきさん(2018/01/24 14:40)
コメントありがとうございます。そのようになると思います。
私の実装は下記のような感じです。STEP5, 8 が多少違うくらいですね。
mxg = _mm256_add_epi32(mx0, mxg); \
mxo = _mm256_add_epi32(mx8, mxo); \
AVX_ROTL(mx0, 7); \
AVX_ROTL(mx8, 7); \
AVX_SWP(mx0, mx8); \
mx0 = _mm256_xor_si256(mx0, mxg); \
mx8 = _mm256_xor_si256(mx8, mxo); \
mxg = _mm256_shuffle_epi32(mxg, 0x4e); \
mxo = _mm256_shuffle_epi32(mxo, 0x4e); \
mxg = _mm256_add_epi32(mx0, mxg); \
mxo = _mm256_add_epi32(mx8, mxo); \
AVX_ROTL(mx0, 11); \
AVX_ROTL(mx8, 11); \
mx0 = _mm256_permute2x128_si256(mx0, mx0, 0x01); \
mx8 = _mm256_permute2x128_si256(mx8, mx8, 0x01); \
mx0 = _mm256_xor_si256(mx0, mxg); \
mx8 = _mm256_xor_si256(mx8, mxo); \
mxg = _mm256_shuffle_epi32(mxg, 0xb1); \
mxo = _mm256_shuffle_epi32(mxo, 0xb1);
残念ながら AMD A10 は AVX2 に対応していないので、SSE2 との速度が比較できませんが…。
この記事にコメントする
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報