2020年1月6日

memsetのベンチマーク(AArch64, Cortex-A53編)
目次: ベンチマーク
(参考)コード一式はGitHubに置きました(GitHubへのリンク)
AArch64その2です。Cortex-A53でmemsetをやってみました。環境はRK3328 Cotex-A53 1.4GHzです。メモリはおそらくLPDDR3-1600です。
Cortex-A72と似ている点としては、
- musl memset関数が非常に優秀
- ベクトル化は性能向上に効くが、他も有効な要素がありそう
違う点としては、
- アセンブラ実装とmusl memset関数の差が開く
- O3の最適化がかなり効く(※)
- glibc memset関数の不安定さが減る
こんなところでしょうか。A72のglibc memset関数はグラフが上がったり下がったりグチャグチャしていましたが、A53だと割と素直になっています。
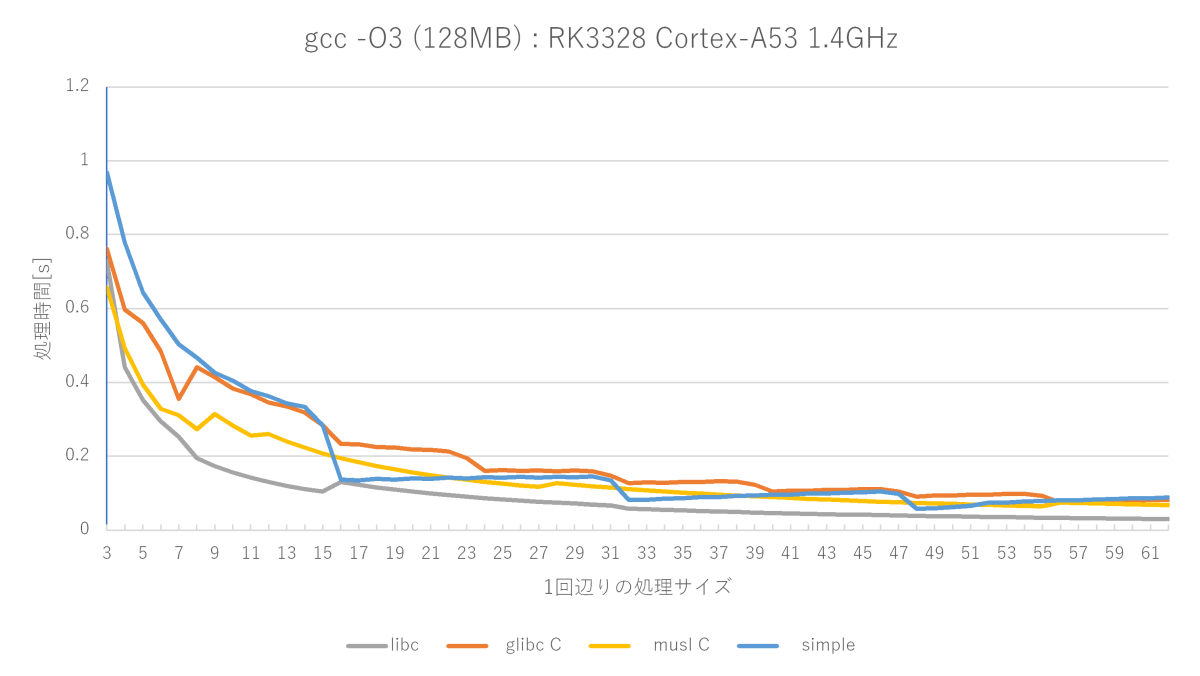
gcc -O3 -fno-builtinの測定結果(Cortex-A53編)
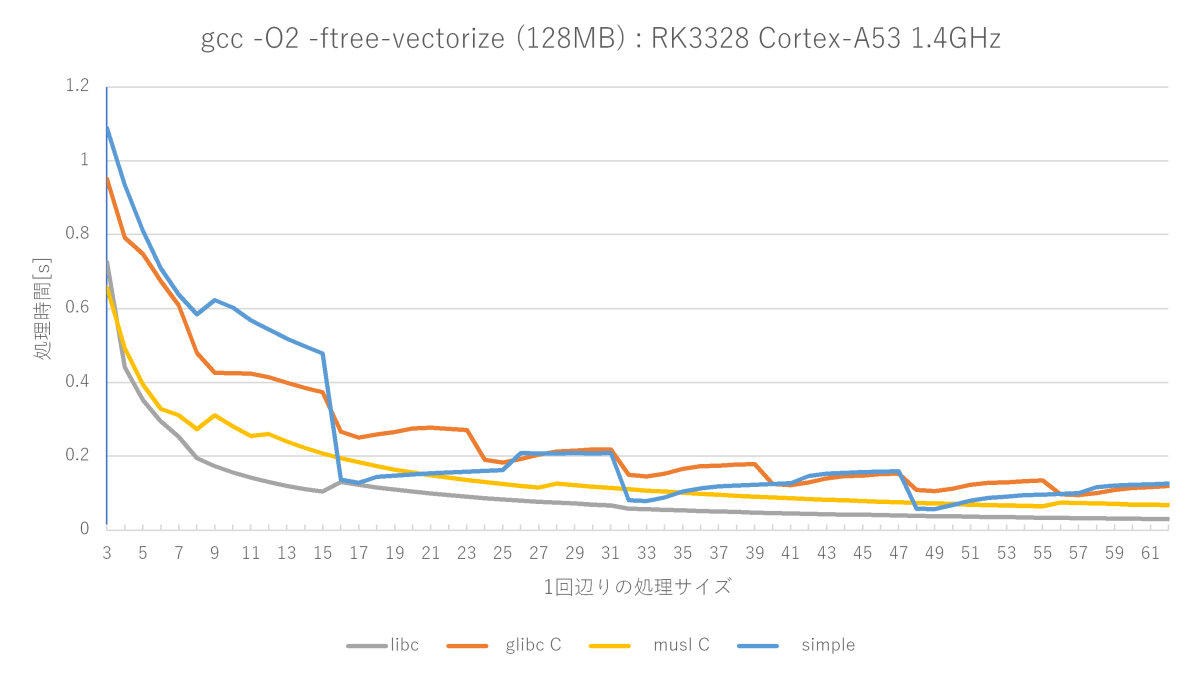
gcc -O2 -ftree-vectorize -fno-builtinの測定結果(Cortex-A53編)
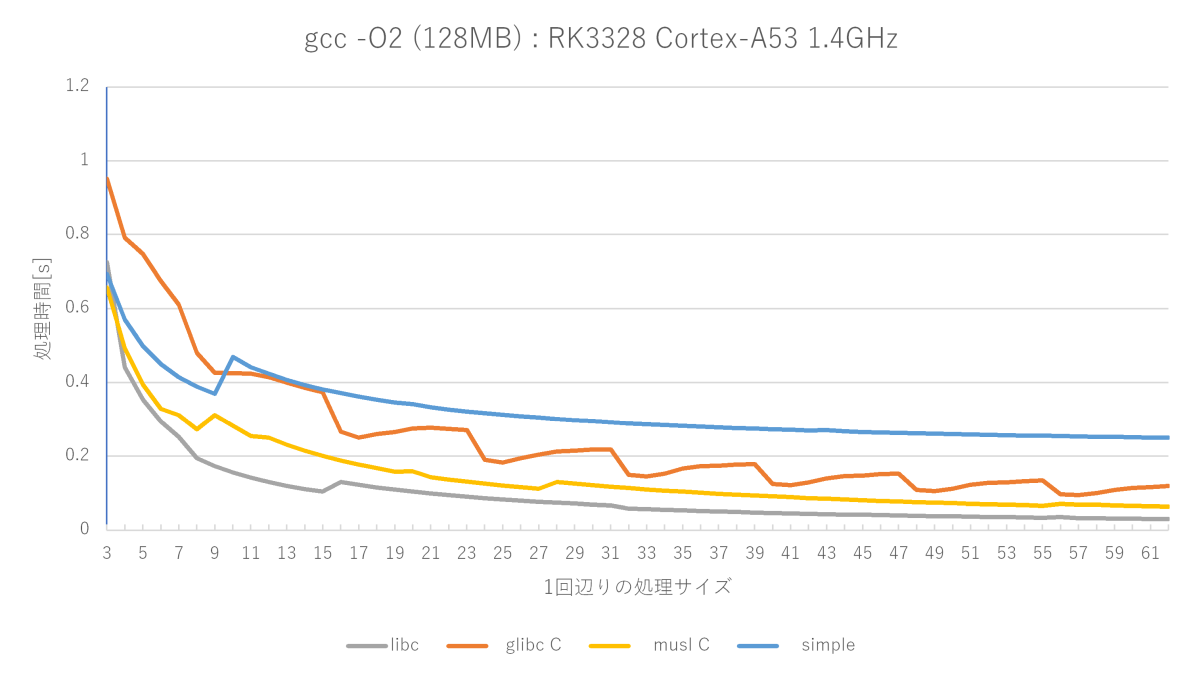
gcc -O2 -fno-builtinの測定結果(Cortex-A53編)
(※)A72では単純なmemset関数はmusl memset関数にほぼ勝てない(16〜22バイトのみ勝つ)が、A53では割と良い勝負(16〜22、32〜38、48〜52バイトで勝つ)をしている。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2020年1月11日
memsetに一番効く最適化
目次: ベンチマーク
Cortex-A72でのmemsetはO2に-ftree-vectorizeと -fpeel-loopsを足すと、O3の性能とほぼイコールになることがわかりました。

gcc -O2 -ftree-vectorize -fpeel-loops -fno-builtinの測定結果(Cortex-A72)
元の処理が非常に単純なループ処理のためか、ループ系の最適化がメチャクチャ効くっぽいです。
何が効くのか?
GCCのGIMPLEを出力させ(-fdump-tree-all)眺めてみると、
- オリジナル
- 1バイトごとにデータ処理するループが生成される。
- ベクタライズ(161t.vect)
- 16バイトごとにデータ処理するループと、1バイトごとに残りデータを処理するループに分割される。
- アンローリング(164t.cunroll, 169t.loopdone)
- 残りデータを処理するループが展開される。
こんな感じに見えます。正直言って、ループアンローリングなんて大したことないと思っていましたが、これほど効くとは思いませんでした。
メモ: 技術系の話はFacebookから転記しておくことにした。大幅に追記。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年1月12日
ぼくの考えた最強のmemset
目次: ベンチマーク
NEON intrinsicを使って自分でmemsetを実装してみました。ざっくりした設計方針としては、
- NEON store (128bit) x 2で32バイトずつ書く
- 端数25〜バイトはNEON store x 2
- 端数16〜バイトはNEON store + uint64 store
相手は汎用実装ですし、Cortex-A72に特化した実装なら楽勝だろう、などと考えて始めましたが、甘かった。glibcのフルアセンブラ版はかなり手ごわいです。
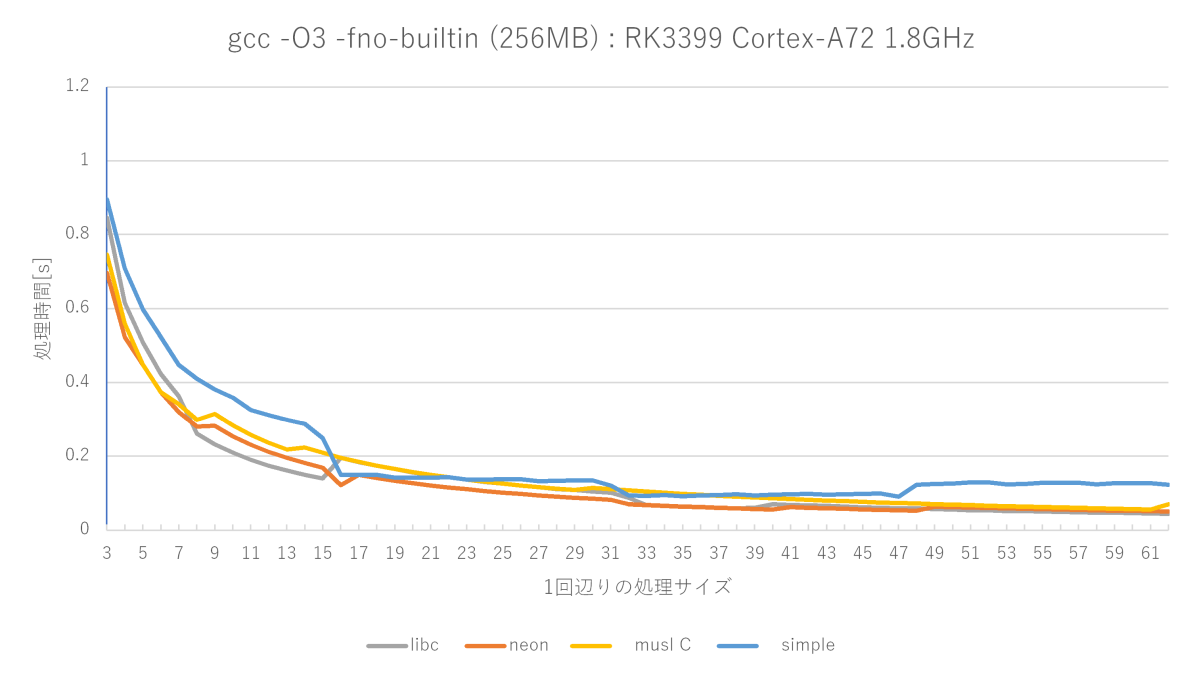
グラフの赤い線が、自作したmemsetの性能です。
最適化レベルO3のsimple memsetにはほぼ全域で勝てますが、サイズが小さいときのmuslは強い(サイズが小さい場合から判定しているから?)です。glibcのフルアセンブラもかなり強いです。測定によって勝ったり負けたりな程度です。
全然最強じゃなかった……
設計が甘すぎたことがわかったので、下記のように見直しました。
- 少ないバイト数の条件から判定
- NEON store (128bit) x 2で32バイトずつ書く
- 端数バイトはNEON store(分岐を減らした)
序盤でmusl memsetに負けていたのは、バイト数の条件判定の順序が良くなかった(大きいサイズから判定していた)ためなので、1番目で対策しています。2番目と3番目の方針は良いとも悪いとも一概に言えませんが、RK3399だとこれが一番性能が出ました。
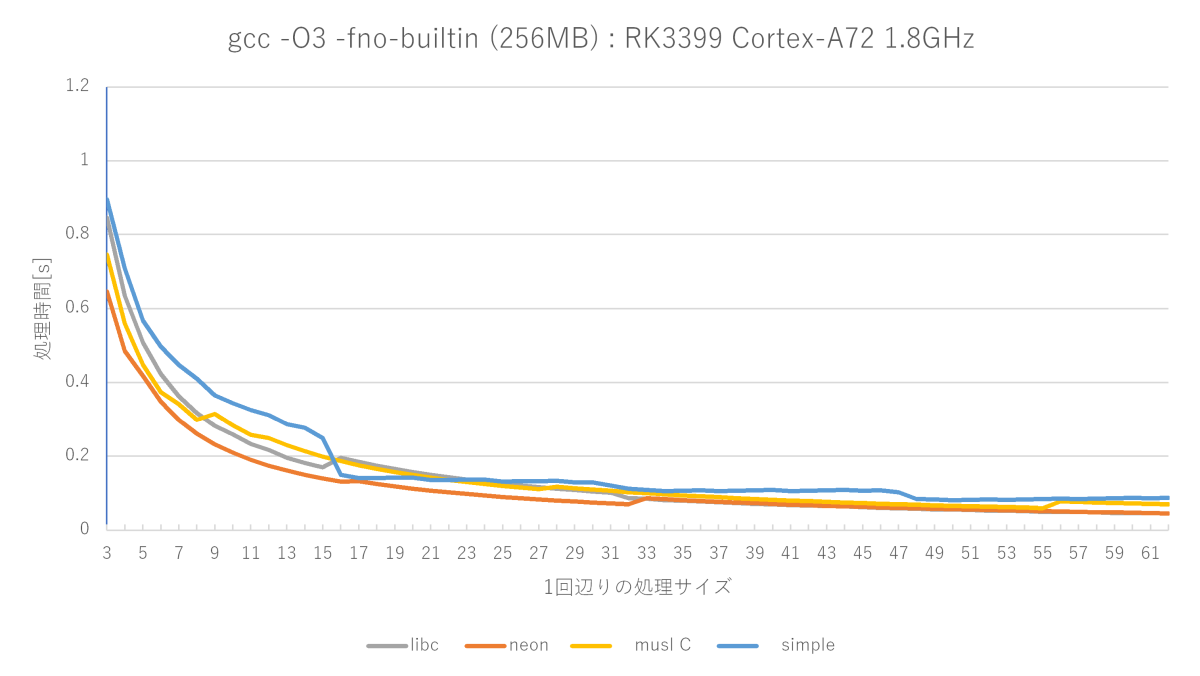
設計意図通りにmuslの序盤(特に高速な1〜8バイト付近)と、glibcフルアセンブラの序盤(1〜32バイト)には勝てたものの、glibcフルアセンブラ版は中盤以降が強く、33バイト以降は全く勝てません。
私の作ったmemsetは32バイトまでは専用処理で、33バイトからループで処理するようになるので、33バイトから性能がかなり落ちます。
おそらくglibcフルアセンブラ版も同様に16バイトから性能が落ちるので、ループ処理していると思うんですが、それ以降の巻き返しが凄くて、33バイト以降はまったく勝てないですね……。どうやってんだろうね、これ?
コンパイラが変なandとかsubを出力しているのを見つけたので、アセンブラでも実装してみましたが、性能はほぼ変わりませんでした。設計の根底が違うんでしょうね。
Cortex-A53だと全く勝ち目無し
RK3328(Cortex-A53)で測ってみると、muslには勝てますが、glibcフルアセンブラ版には勝ち目無しで、ほぼ全域に渡ってボコボコにされます。
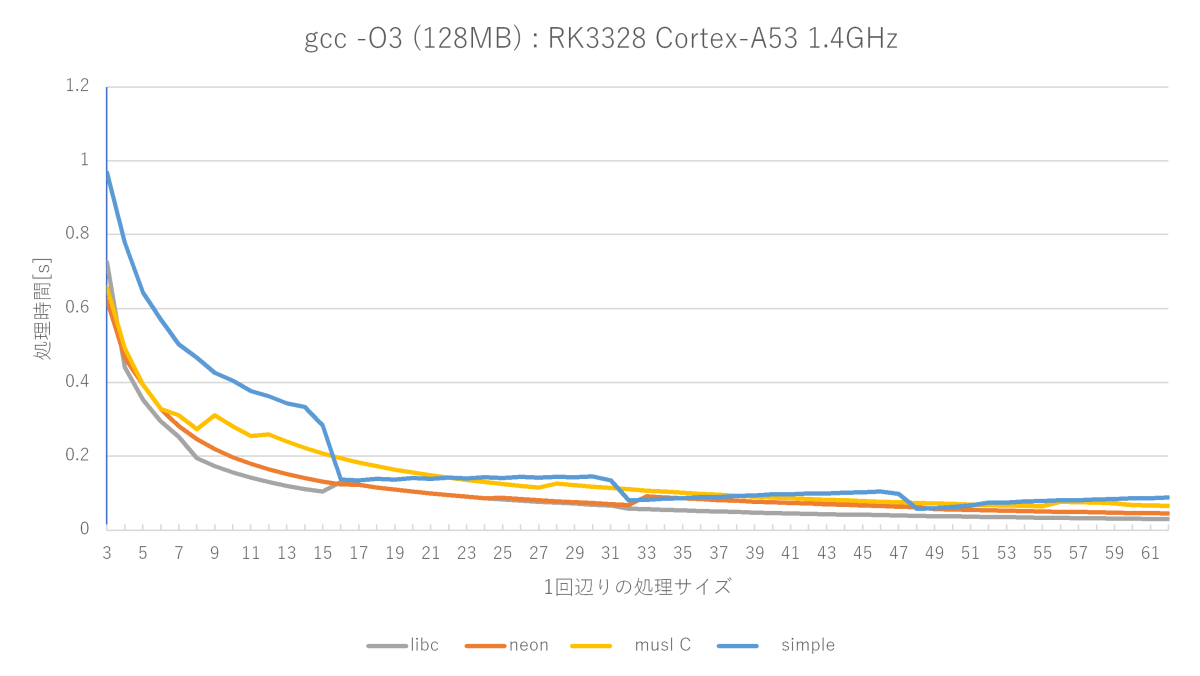
基本設計が「余計なwriteをしてでも、とにかく速く終われ」なので、writeを正直に実行してしまうようなヘボいプロセッサになればなるほど勝ち目が薄いです。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年1月19日
バイトをコピーするSIMD命令
目次: ベンチマーク
最近、見かけるSIMD命令セット(AVXもNEONも)には、レジスタ下位 [7:0] の1バイトを、レジスタ上位 ... [31:24] [23:16] [15:8] の各バイトに配る命令が用意されています。
- AVX: vpbroadcastb
- NEON: dup
この命令はどういう需要があるんだろうか……?memsetの実装では超役に立ちましたが、他の使い道が良くわかりません。
Facebookで上記の話をしていたところ、
- 8bit行列演算: 8bit行列演算ってそんな頻出かな、って思ったら、画像使えば8bitなので十分有り得そう。
- バイト暗号: ブロック毎に空間変換する時とか雑に言えばスカラとベクトルの演算。
と教えてもらいました。なるほど、スカラベクトル積のスカラ側を配るときに便利ですね。
SIMD命令のない世界
ちなみにSIMDのない処理系はどうしているのか見てみると、
int a = (何かの数字);
としたときに、
a &= 0xff;
a *= 0x01010101;
のようにand, mov, mulを使っていました。もちろん、
a &= 0xff;
a |= a << 8;
a |= a << 16;
のようにand, shift, or, shift, orでもできますが、今日日のプロセッサだと整数乗算の方が速そうですね。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年1月20日
glibcのmemsetのクセ
目次: ベンチマーク
先日memsetを書いていたとき(2020年1月12日の日記参照)に気づいたのですが、glibcのフルアセンブラ版memsetの性能が2通り(遅い、速い)あることに気づきました。だいたい1割くらい性能が変わります。
遅いときと比較すると、自作のmemsetの方が速いですが、速いときと比較するとボロ負けします。割と性能が迫っているためか、影響が大きいです。
何が違うんでしょうね?コードは当然同じですから、違いはmemset関数のロードされるアドレスくらいです。まさかなと思って、スタティックリンクしたら安定して速くなりました。
ダイナミックリンクだと、アプリ側は0xaaaac4fba560で、glibcだけ0xffffbf2dce00のような遠いアドレスに飛ばされます。ベンチマーク中は、アプリのコード ←→ glibcのコードを頻繁に行き来することになるので、TLBミスヒットの影響が出ているんですかね……??
真因はわかりませんが、アドレスが関係している可能性は高いです。今後、似たようなことをやるときは、スタティックリンクで測った方が良さそうです。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年1月21日
glibcのmemsetは強かった
目次: ベンチマーク
先日(2020年1月12日の日記参照)の続きです。
あまりにもglibcフルアセンブラ版memsetの実装が速くて勝てないので、観念して実装を見たのですが、序盤(1バイト〜32バイト)が弱い理由と、以降(33バイト〜)で勝てない理由がわかりました。
他の実装と違ってglibcはサイズの大きい方から条件を見ています。どうしても条件分岐命令を通る回数が増えるため、序盤に弱いです。
中盤は96バイトまではNEON store x 4と分岐で捌いていて、ループを使いません。分岐もcmpしてbranchではなく、ビットセットされていたら分岐する命令(tbz, tbnz)を使っています(※)。
つまり私が書いたmemsetはループで処理している時点で、ほぼ勝ち目がなかったということです。
グラフでは63バイトまでしか測っていなかったから気づかなかったのですが、ループの2週目に入る65バイトから、さらにボロ負けです。いやはや、これは勝てないですね……。
(※)cmp, branchの2命令をtbz 1命令にする辺り、AArch64アセンブラならではの実装に見えますが、実はCでもif (a & 0x10) とか書くとコンパイラがtbz命令を使います。コンパイラ侮りがたし。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年1月26日
C言語の未定義動作と最適化
目次: C言語とlibc
くそ長いですが、C言語の未定義動作怖いね、printfでタイミング以外も動き変えられるよ、という話です。
環境ですがx86_64向けDebian GNU/Linux 9.2で実行しています。またGCCのバージョンはgcc (Debian 9.2.1-22) 9.2.1 20200104です。
未定義動作のため、コンパイラの種類や、GCCのバージョンにより結果が変わると思われます。お家のマシンで試すならご留意ください。
1番目の実験
この日記の最後に貼ったプログラム(このプログラムをコンパイルすると、激しい警告が出ます)をgcc -Wall -O2 a.c && ./a.outのように実行すると、
1番目の実験: あれ?バッファオーバーランは…?
0: 0 0 0 1: 0 1 0 2: 0 2 0 3: 0 3 0 4: 0 4 0 ... 47: 0 47 0 48: 0 48 0 49: 0 49 0 1770: 1770
こうなります。0〜59の和は1770です。あってます。良かったですね。
なに?そういう問題じゃない?「なぜarray終端を超えてguard2にバッファオーバーランしない?」と考えた方、するどいです。しかし世の中そう単純ではありません。
2番目の実験
10行目のprintfのコメントを外してローカル変数のアドレスを表示させると、
2番目の実験: 10行目のprintfを有効、突然のバッファオーバーラン
0x7ffd9b348a10 0x7ffd9b348ae0 0x7ffd9b348bb0 0: 0 0 52 1: 0 1 53 2: 0 2 54 3: 0 3 55 4: 0 4 56 ... 45: 0 45 0 46: 0 46 0 47: 0 47 0 48: 0 48 0 49: 0 49 0 1770: 1770
こうなります。突然オーバーランするようになりました。printfが何かしたんでしょうか、不思議ですね?
3番目の実験
どうしてforループを無意味に2分割したのか?くっつけてみたらわかります。Segmentation Fault します。
3番目の実験: ループを1つにするとクラッシュ
0: 0 0 0 1: 0 1 0 2: 0 2 0 3: 0 3 0 4: 0 4 0 ... 45: 0 45 0 46: 0 46 0 47: 0 47 0 48: 0 48 0 49: 0 49 0 Segmentation fault
もう意味不明ですよね。何が起こっているんでしょう?
タネ明かし
この60回のforループは「配列の終端を超えたアクセス」がC言語仕様上の未定義動作なので、何が起きても正しい、つまりどの結果も正しいです。
これだけだと、何言ってんのか意味不明だと思うので「printf有効/無効」「forループ1つ/2つ」に着目して説明します。
- 1番目の実験(printf無効、forループ2つ)
-
プログラムを見るとguard1, guard2に対してmemset 0した後、参照のみで代入しません。コンパイラはguard1, guard2をスタックに配置せず、配列への参照(guard1[i], guard2[i])は全て「定数の0」に置換します。
(GIMPLEを見たら033t.fre1で0に置換されるようです)
このときarrayのバッファオーバーランはスタックに退避されているレジスタ値などを書きつぶしますが、ギリギリ続行できています。 - 2番目の実験(printf有効、forループ2つ)
-
1番目と変わりないと思いきや、printfがguard1, guard2のアドレス参照をするため、定数の0に置換すると返せるアドレスがなくなり結果が変わってしまいます。このため、guard1, guard2はスタックに配置されます。
このときarrayのバッファーオーバーランは隣に配置されたguard2を書きつぶします。 - 3番目の実験(printf無効、forループ1つ)
- いわゆる偶然の結果です。1番目と同様にguard1, guard2はスタックに配置されず、arrayのバッファオーバーランによりスタックに退避したレジスタ値などが壊れます。forループが1つ減ったことでスタックに退避されるレジスタが1つ減って(8バイト分余裕がなくなる)、1番目の実験でギリギリリターンアドレスを壊されずに耐えていたものが、耐えられなくなります。
3番目の実験の裏打ちとして、試しにループ回数を80回くらいにするとforループが1つだろうが2つだろうが、リターンアドレスがぶっ壊れてSegmentation Fault します。10行目のprintfを有効にするとguard1, guard2がスタックに配置されて、受け止めてくれるので、80回でも耐えます。
難解なC言語仕様、曖昧な利用者の理解、過激なコンパイラの最適化、が招く結末
バッファオーバーランを期待していた向きには残念(?)かもしれませんが、guard1, guard2はメモリ上に置いても置かなくても、C言語仕様に矛盾しないなら、どっちでも良いです。もっというとC言語仕様に矛盾しないなら、コンパイラの最適化は何をやってもOK です。
この「C言語仕様に矛盾しないなら」はおそらくコンパイラ開発者には常識なのでしょうけども、C言語の仕様は人間に優しくないのと、大多数のC言語プログラマは言語仕様(特に未定義動作)を理解しておらず、何となく使っています。
難解な仕様、曖昧な理解、過激な最適化の相乗効果により、今日も世界のどこかで
「最適化で動きが変になっちゃったよ……。どうして…どうして……?」
とコンパイラとすれ違ったプログラマが泣いているでしょう。。。
参考
大したものではありませんが、ソースコードを載せておきます。
実験用ソースコード
#include <stdio.h>
#include <string.h>
int undefined()
{
int guard1[50];
int array[50];
int guard2[50];
int sum = 0, i;
memset(guard1, 0, sizeof(guard1));
memset(guard2, 0, sizeof(guard2));
//printf("%p %p %p\n", &guard1[0], &array[0], &guard2[0]);
for (i = 0; i < 60; i++) {
array[i] = i;
}
for (i = 0; i < 60; i++) {
sum += array[i];
}
for (i = 0; i < 50; i++) {
printf("%2d: %d %d %d\n", i, guard1[i], array[i], guard2[i]);
}
return sum;
}
int main(int argc, char *argv[])
{
int sum1 = 0, sum2 = 0, i;
sum1 = undefined();
for (i = 0; i < 60; i++) {
sum2 += i;
}
printf("%d: %d\n", sum1, sum2);
return 0;
}
コメント一覧
- コメントはありません。
この記事にコメントする
2020年1月27日
クロスビルド用ツールチェーン - GCC 10.0にしたらハマった
目次: GCC
新し目のAArch64のクロスコンパイル用ツールチェーンを作ろうとして、かなりハマったのでメモしておきます。
基本的には前回(2019年4月29日の日記参照)ご紹介した手順でビルドします。GCCとglibcのコードを変えなくて良い組み合わせは下記の通りです。特に新しいバージョンを使う理由がなければ、この組み合わせが無難です。
- gcc: 8.3.0 (tag: releases/gcc-8.3.0)
- glibc: 2.28 (tag: glibc-2.28)
私は新しいGCCが使いたかったので、HEADにしました(バージョン的には10.0相当)。どうやらGCCのエラーチェックが厳しくなるらしく、glibcのビルドが通らなくなります。たくさんエラーが出ますが、一例を挙げると、下記のようなエラーです。
GCC HEAD (GCC 10.0相当) でglibc 2.28をビルドするとコンパイルエラー
./../include/libc-symbols.h:534:26: error: '__EI___errno_location' specifies less restrictive attributes than its target '__errno_location': 'const', 'nothrow' [-Werror=missing-attributes]
534 | extern __typeof (name) __EI_##name \
| ^~~~~
エラーはglibcを新しくすると解決されるかと思いきや、よりおかしなことになります。例えばGCC 8.3のままglibc 2.30(おそらく2.29でも同じ症状が出る)にすると、下記のような変なエラーが出ます。
GCC 8.3でglibc 2.30をビルドするとリンクエラー
crosstool-builder-new-aarch64/buildroot/lib/gcc/aarch64-unknown-linux-gnu/8.3.0/../../../../aarch64-unknown-linux-gnu/bin/ld: crosstool-builder-new-aarch64/build/glibc/support/links-dso-program.o: Relocations in generic ELF (EM: 62) crosstool-builder-new-aarch64/buildroot/lib/gcc/aarch64-unknown-linux-gnu/8.3.0/../../../../aarch64-unknown-linux-gnu/bin/ld: crosstool-builder-new-aarch64/build/glibc/support/links-dso-program.o: Relocations in generic ELF (EM: 62) ...
エラーの原因となっているオブジェクトlinks-dso-program.oを調べると、AArch64向けにビルドしているにも関わらず、なぜかx86_64用のオブジェクトが生成されています。
glibc/support下に生成されたオブジェクト
build/glibc/support$ file *.o echo-container.o: ELF 64-bit LSB relocatable, ARM aarch64, version 1 (SYSV), with debug_info, not stripped links-dso-program.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), with debug_info, not stripped ★★★★これ★★★★ shell-container.o: ELF 64-bit LSB relocatable, ARM aarch64, version 1 (SYSV), with debug_info, not stripped stamp.o: empty test-container.o: ELF 64-bit LSB relocatable, ARM aarch64, version 1 (SYSV), with debug_info, not stripped true-container.o: ELF 64-bit LSB relocatable, ARM aarch64, version 1 (SYSV), with debug_info, not stripped
いったい何ですかね、これ。バグなのか、仕様なのかわかりません……。
GCC 10.0とglibc 2.30の組み合わせでビルドする方法
GCCとglibcをお互い最新にした組み合わせ、すなわち下記の組み合わせにしたとき、
- gcc: 10.0 (HEAD)
- glibc: 2.30 (tag: glibc-2.30)
先ほど説明した、両方のエラーに遭遇してビルドできませんので、glibcにパッチを当ててビルドエラーを回避します。
まずはコンパイルエラーを無視するパッチです。本来はエラーを無視するのではなく、エラーが指摘している事項を直すべきですけど、今回の主眼ではないのと、いずれglibc本家が直るだろうことを期待しておきます。
glibcのビルドエラーをあえて無視するパッチ
diff --git a/Makeconfig b/Makeconfig
index fd36c58c04..106688e210 100644
--- a/Makeconfig
+++ b/Makeconfig
@@ -916,7 +916,8 @@ ifeq "$(strip $(+cflags))" ""
endif # $(+cflags) == ""
+cflags += $(cflags-cpu) $(+gccwarn) $(+merge-constants) $(+math-flags) \
- $(+stack-protector)
+ $(+stack-protector) \
+ -Wno-zero-length-bounds -Wno-array-bounds -Wno-maybe-uninitialized
+gcc-nowarn := -w
# Each sysdeps directory can contain header files that both will be
次のlinks-dso-programはコミットログを見る限り、テストのサポート用ライブラリなので、とりあえず無くても動くはずです。ビルド自体をやめるパッチをあてます。
glibcのsupport/links-dso-programをビルドさせないパッチ
diff --git a/support/Makefile b/support/Makefile
index ab66913a02..19c3de2043 100644
--- a/support/Makefile
+++ b/support/Makefile
@@ -184,12 +184,12 @@ CFLAGS-support_paths.c = \
-DSBINDIR_PATH=\"$(sbindir)\" \
-DROOTSBINDIR_PATH=\"$(rootsbindir)\"
-ifeq (,$(CXX))
-LINKS_DSO_PROGRAM = links-dso-program-c
-else
-LINKS_DSO_PROGRAM = links-dso-program
-LDLIBS-links-dso-program = -lstdc++ -lgcc -lgcc_s $(libunwind)
-endif
+#ifeq (,$(CXX))
+#LINKS_DSO_PROGRAM = links-dso-program-c
+#else
+#LINKS_DSO_PROGRAM = links-dso-program
+#LDLIBS-links-dso-program = -lstdc++ -lgcc -lgcc_s $(libunwind)
+#endif
ifeq (yes,$(have-selinux))
LDLIBS-$(LINKS_DSO_PROGRAM) += -lselinux
クロスコンパイル環境は、各モジュールのバージョンアップですぐ壊れてしまって辛いです。ARMがこれだけ覇権を握っているにも関わらず、gccもglibcもあまりチェックしてないんですかね……??
後日追記
わざわざMakefileを書き換えなくてもmake LINKS_DSO_PROGRAM= のように、make実行時にLINKS_DSO_PROGRAM変数の値を強制的に空文字列に上書きすれば回避可能でした。理由は昔の日記で書いた通り(2019年9月17日の日記参照)、コマンドラインからの変数指定はMakefile内の代入より強いからです。
Makefile書き換えよりは多少スマートですけども、クロスコンパイルの時だけこんな指定が必要なのは妙ですね。まだ何か見落としているんでしょうかね?
コメント一覧
- superzerosさん(2020/04/15 19:59)
ARM64 target (cortexa53)と x86_64 host (Ryzen7)のクロスコンパイラのビルドで、当方にもご指摘のエラーがありました。で、そのパッチを拝借したところ、見事GLIBCのコンパイルが通りました。
ありがとうございました!
なんと申しましょうか、とても柔軟かつ大胆に繊細な対応をなされますね。
補足:当方の各パッケージのバージョンは latest(2020-04-15)
linux-5.6.4 (headers)
gcc-9.3.0
glibc-2.31
binutils-2.34
configure やBUILD手法は archlinux PKGBUILD と Cross LFS BOOK 等のWEB情報を参考にして適当にやっております(笑 - すずきさん(2020/04/15 23:13)
コメントありがとうございます。お役に立ったようで良かったです。
動作に支障無さそうなところだったので、かなり適当に変えてしまいました。
大胆というか適当というか……。 - superzerosさん(2020/04/16 21:07)
少し気になったのでglibcの履歴を調べてみたら・・・
glibc-2.31/support/links-dso-program-c.c
glibc-2.31/support/links-dso-program.cc
このファイルは、2.29で最初に追加され
\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\
#include <iostream>
using namespace std;
int
main (int argc, char **argv)
/* Complexity to keep gcc from optimizing this away. */
cout << (argc > 1 ? argv[1] : "null");
return 0;
\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\
で、続いて2.30では
\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\
#include <iostream>
/* makedb needs selinux dso's. */
#ifdef HAVE_SELINUX
# include <selinux/selinux.h>
#endif
using namespace std;
/* The purpose of this file is to indicate to the build system which
shared objects need to be copied into the testroot, such as gcc or
selinux support libraries. This program is never executed, only
scanned for dependencies on shared objects, so the code below may
seem weird - it's written to survive gcc optimization and force
such dependencies.
*/
int
main (int argc, char **argv)
/* Complexity to keep gcc from optimizing this away. */
cout << (argc > 1 ? argv[1] : "null");
#ifdef HAVE_SELINUX
/* This exists to force libselinux.so to be required. */
cout << "selinux " << is_selinux_enabled ();
#endif
return 0;
\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\
2.29では、どういう経緯で誰によって導入されたのか、知りませんけど
2.30では、SElinux(国家安全保障局)がどうたらこうたらの追加です
誰のためになるんでしょうか ・・・
自分の所有するハードウエアを自分で使いこなしたいだけのわたしからすれば
バージョンアップに紛れ込んだオープンソースへの破壊活動みたいなもんですよ
貴重な時間を奪われるところでしたが、おかげさまですぐに解決できてよかったです
貴方に感謝いたします
\(^o^)/
- すずきさん(2020/04/18 23:05)
詳細は調べていないので、コード中のコメントからの想像ですが……破壊活動というほどではないかなと思います。
SELinux が有効なときは、SELinux のライブラリがないと動かないのでしょう。このヘルパープログラムは SELinux のライブラリを使っているから、ビルドシステムはテスト用の rootfs に SELinux のライブラリをコピーしてくれ、ということを示すための変更だと思います。
この記事にコメントする
2020年1月31日
Hello! Zephyr OS!! (RISC-V 32bit版)
目次: Zephyr
以前Zephyr OSを実行しました(2019年1月12日の日記参照)が、今回はRISC-V 32bit版で試してみようと思います。
この例ではbuildをビルドディレクトリとします。どこに置いても動くはずですが、私はとりあえずzephyrの下に置いています。
クロスコンパイラの準備
前回同様Zephyr SDKもしくはCrosstool-NGが使えます。参考までにCrosstool-NGのコンフィグを載せておきます。
crosstool-NG RISC-V版のビルド
$ ./ct-ng menuconfig
Target options --->
Target Architecture (riscv) --->
[*] Build a multilib toolchain (READ HELP!!!)
Bitness: (64-bit) --->
(rv32ima) Architecture level
(ilp32) Generate code for the specific ABI
Toolchain options --->
(zephyr) Tuple's vendor string
Debug facilities --->
[*] gdb --->
[*] Build a static cross gdb
一見すると32bit CPUのコードをビルドする予定なのに、Bitness: 64bitにしており、不思議なコンフィグに見えるかもしれませんが、Zephyr OSのビルドはクセがあって、この設定が必要です。
Architecture level, Generate code for the specific ABIはGCCが生成するバイナリの命令セットを指定しており、それぞれ -march=rv32ima, -mabi=ilp32に対応します。特に何も指定しないとrv32gc, ilp32fになるようです。
ZephyrのCMakeスクリプト
zephyr/cmake/toolchain/xtools/target.cmake
set(CROSS_COMPILE_TARGET_riscv riscv64-zephyr-elf)
set(CROSS_COMPILE_TARGET ${CROSS_COMPILE_TARGET_${ARCH}})
ZephyrのCMakefileを見るとわかるんですが、riscv64もriscv32も区別せず同じコンパイラでビルドし、しかもコンパイラ名は常にriscv64-zephyr-elf-gccだと思っています。したがって64bit版をビルドする必要があり、multilibを有効にしています。
(余談)riscv向けの -mabi, -marchオプションの値を決めているのはzephyr/cmake/compiler/gcc/target.cmakeで、rv32ima固定になっています。
- list(APPEND TOOLCHAIN_C_FLAGS -mabi=ilp32 -march=rv32ima)
+ list(APPEND TOOLCHAIN_C_FLAGS -mabi=ilp32f -march=rv32gc)
上記のように変えると、Crosstool-NGでArchitecture level, Generate code for the specific ABIの設定をしなくても良くなりますが、動くかどうかは試していません。
ビルドの方法
実ボードを持っていないのでQEMUで試します。SiFive HiFive1をエミュレートしているそうです。
環境変数のセットアップとcmakeの実行
$ cat ~/.zephyrrc export ZEPHYR_TOOLCHAIN_VARIANT=xtools export XTOOLS_TOOLCHAIN_PATH=/home/katsuhiro/x-tools $ cd zephyr $ source zephyr-env.sh $ mkdir build $ cd build $ cmake -G Ninja -DBOARD=qemu_riscv32 ../samples/hello_world/ -- Zephyr version: 2.1.99 -- Found PythonInterp: /usr/bin/python3 (found suitable version "3.7.6", minimum required is "3.6") -- Selected BOARD qemu_riscv32 -- Loading /home/katsuhiro/share/projects/oss/zephyr/boards/riscv/qemu_riscv32/qemu_riscv32.dts as base Devicetree configuration written to /home/katsuhiro/share/projects/oss/zephyr/build/zephyr/include/generated/devicetree.conf Parsing /home/katsuhiro/share/projects/oss/zephyr/Kconfig Loaded configuration '/home/katsuhiro/share/projects/oss/zephyr/boards/riscv/qemu_riscv32/qemu_riscv32_defconfig' Merged configuration '/home/katsuhiro/share/projects/oss/zephyr/samples/hello_world/prj.conf' Configuration saved to '/home/katsuhiro/share/projects/oss/zephyr/build/zephyr/.config' -- The C compiler identification is GNU 8.3.0 -- The CXX compiler identification is GNU 8.3.0 -- The ASM compiler identification is GNU -- Found assembler: /home/katsuhiro/x-tools/riscv64-zephyr-elf/bin/riscv64-zephyr-elf-gcc -- Cache files will be written to: /home/katsuhiro/.cache/zephyr -- Configuring done -- Generating done -- Build files have been written to: /home/katsuhiro/share/projects/oss/zephyr/build
実行するときはninja runで良いんですが、前回同様にninjaが何を起動しているか調べてみます。
Zephyr OS実行
$ /usr/bin/qemu-system-riscv32 -nographic -machine sifive_e -net none -chardev stdio,id=con,mux=on -serial chardev:con -mon chardev=con,mode=readline -kernel /home/katsuhiro/share/projects/oss/zephyr/build/zephyr/zephyr.elf -s -S (gdbからcontinueをすると、下記が出力される) *** Booting Zephyr OS build zephyr-v2.1.0-1471-g7e7a4426d835 *** Hello World! qemu_riscv32
オプション -sはGDBの接続をlocalhost:1234で受け付けます、という意味です。オプション -SはエミュレータをHalted状態で起動します。もしGDBをつなぐ必要がなければ -sや -Sを削って起動してください。
GDB接続
$ riscv64-zephyr-elf-gdb GNU gdb (crosstool-NG 1.24.0.60-a152d61) 8.3.1 Copyright (C) 2019 Free Software Foundation, Inc. ... (gdb) set arch riscv:rv32 The target architecture is assumed to be riscv:rv32 (gdb) target remote localhost:1234 Remote debugging using localhost:1234 warning: No executable has been specified and target does not support determining executable automatically. Try using the "file" command. 0x00001000 in ?? () (gdb) continue Continuing.
実行できました。おなじみのHello World! です。
コメント一覧
- コメントはありません。
この記事にコメントする
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報