2014年5月1日

Javaのイテレータ
目次: Java
Javaを始めたときにコケたので思い出深いのですが、C++とJavaってイテレータの概念が全然違いますね。
C++のイテレータはコレクションの要素そのものを指しています。N個要素を持つ配列aのイテレータitであれば、a.begin() はa[0] を指し、itはa[0] からa[N - 1] の間まで有効な要素を指し続けます。a.end() は存在しないa[N] を指します。
C++のイテレータ
begin() end()
| |
a[0] a[1] a[2] ... a[N - 2] a[N - 1] a[N]
| コレクションの有効範囲 |
C++方式の利点は、イテレータが何を指すのか直感的に理解しやすく、イテレータ経由での要素の書き換えや削除のイメージが沸きやすいことです。
欠点はbegin() は参照して良いのに、end() は参照してはいけない、という非対称な仕様になってしまうことです。例えば、逆転イテレータ(reverse_iterator)を実装するとbegin() をend(), ++ を -- として扱うだけでは作れずに、悲しい思いをします。
Javaのイテレータは要素と要素の「間」を指しています。Javaにbegin(), end() はありませんが、対比のため無理やり書くと下記のようなイメージです。
Javaのイテレータ
begin() = iterator() end() = hasNext() がfalse
| |
a[0] a[1] a[2] ... a[N - 2] a[N - 1]
| コレクションの有効範囲 |
Java方式の利点はbeginとendが対称的になることです。もうbeginとendで悲しい思いをすることはありません。
欠点は書き換えや削除の対象がわかりづらいことです。特に双方向イテレータ(ListIterator)が顕著なので、もう少し詳しくご紹介しましょうか。
Javaコレクションの仕様ではイテレータが「最後に返した要素」が書き換え(set)や削除(remove)の対象、となります。ListIteratorは進む/戻るのどちらもできますから、イテレータの現在位置の「直前」あるいは「直後」どちらかの要素が対象となります。下記に図示します。
JavaのListIteratorのset()/remove() の対象
最後の操作がnext() だった場合
------------------------------
set()/remove() の対象
| 現在位置
| |
a[0] a[1] a[2] ...
最後の操作がprevious() だった場合
----------------------------------
現在位置
| set()/remove() の対象
| |
a[0] a[1] a[2] ...
現在位置が全く同じでもset()/remove() の対象が変わる、この動きは正直ややこしいです。
利点の両立は難しいでしょうから、あとは皆さんの好みでしょうか。私は対称性を取ってJava方式に一票かなあ…。
コメント一覧
- IKeJIさん(2014/05/02 13:04)
常に内部イテレータを使うべき(極論) - すずきさん(2014/05/06 00:51)
>IKeJIさん
内部イテレータって foreach ですか?
コレクションの要素が多すぎて単純な全列挙→フィルタで処理できないときや、イテレータを飛ばしたり戻したりするのが難しそうです。 - IKeJIさん(2014/05/11 04:11)
foreachに限らず、eachとかmapとかfoldとかそういうのも含めて考えてました。
> コレクションの要素が多すぎて単純な全列挙→フィルタで処理できないときや、イテレータを飛ばしたり戻したりするのが難しそうです。
どういう処理でしょう?何か例がありますか?
俺みたいな低能力プログラマには外部イテレータは難しすぎる気がします。
もし、for文を書かないといけない時は、椅子に座りなおして、コーラを取ってきてから、気合を入れてかきます。 - すずきさん(2014/05/11 17:53)
>IKeJI さん
>どういう処理でしょう?何か例がありますか?
特殊すぎる処理で申し訳ないですが、現に困ってるのは、
「最初の 4バイトがタイプで、最初の 4バイトがサイズ、そのあとサイズ分だけのデータが続く」
というバイナリを見るとき、もし A, B, C と並んでいれば頭から順に解析できますが、A, C, B と並んでいる場合は頭から順に解析することができない、という構造です。
さらに C は数 GB あったりして、とにかく全部メモリに置くという作戦もとれません。
今は外部イテレータにして、わからない部分は飛ばして、位置だけ「仮 C」として覚えておき、後で読む、としていますが、それを foreach や map や fold でどうやって書くのか思いつきませんでした。
特に Scala の場合、map や fold を List に対してぶちかますと、List の全要素に対して述語の評価を行うので、List の要素が数 GB 以上になると map や fold が現実的な時間で帰ってきません。
>俺みたいな低能力プログラマには外部イテレータは難しすぎる気がします。
>もし、for文を書かないといけない時は、椅子に座りなおして、コーラを取ってきてから、気合を入れてかきます。
たしかに for + 外部イテレータは面倒くさいです。
外部イテレータ以外の方法があれば使ってみたいんですけど…。
 この記事にコメントする
この記事にコメントする
2014年5月2日
判断ミス
今の偉い人が現役だった1990年くらいから、現在2010年で見たら、ハード規模の増加率と、ソフト規模の増加率はどっちが上なんでしょう(組み込み系で)。
開発人員の割り振りを見る限り、日本の老舗メーカーはどうもハード規模の増加率が上だと判断し、海外のメーカーはその逆だと判断した、ように見えるのです。
どちらの判断が正解か私にはわかりませんが、今の日本メーカーの傾きっぷりを見るに、海外勢が正解だったように思えて仕方ありません。
ハード復権の時代は来るでしょうか…。
メモ: 技術系の話はFacebookから転記しておくことにした。
コメント一覧
- コメントはありません。
この記事にコメントする
2014年5月3日
無責任
ソ連型システム崩壊から何を汲み取るか──コルナイの理論からを読んで。
役所の税金無駄遣い、失敗だらけの第三セクター、銀行の公的資金注入、赤字企業の経営陣…、などを見る度に感じるイライラは何だろうと思っていたのですが、この記事が見事に説明してくれました。
上記いずれも、決断者はリスクを伴う決断をしますが、生じたリスクは他人に押し付けるという構造になっている、という指摘です。
要するに全員「偉そうに指示したくせに、しくじったらトンズラする無責任野郎」なのです。
見ていて腹が立つわそりゃ。非常にスッキリしました。
メモ: 技術系の話はFacebookから転記しておくことにした。
コメント一覧
- コメントはありません。
この記事にコメントする
2014年5月6日
日記検索システム
現在、トップページの入力フォームから、日本語を指定して日記の検索を行うと文字化けする不具合が起きています。
原因は、日記サイトの文字コードをUTF-8に変更した際に、検索システム(Namazu)側の文字コードeuc-jpと食い違ってしまったことです。kakasiは2.3.5にてiconvに対応したらしくUTF-8の文書でも問題なく分かち書きできるようですが、どうもnamazu.cgiがUTF-8の入力に対応していないようです…。
困ったなー。修正できないかどうか、しばし探してみます。
コメント一覧
- コメントはありません。
この記事にコメントする
2014年5月11日
2048の最高得点(その1)
2048の最高得点について考えてみます。
仮定: 新しい数字が常に理想的に出現した場合、4x4のフィールドは、横1列の16マスと同等とみなせる、とします。
この仮定が正しいかどうかがイマイチ分かりませんが…考えるのは後回しにします。この仮定が正しいとして、
- 必ず左端に新しい数字が出現
- 常に右に移動
という動きを考えます。
2だけ出てくる場合
新しい数字としては2か4が出ますが、まずは単純にするため2が出続けた場合を考えます。2が出続けた場合の手詰まりの形は、
2, 4, 8, 16, ..., 65536
つまり、
2, 4, ..., 2^(N-1), 2^N
です。
手詰まりになるまで4がいくつ必要か(=4が何回生成されるか、と同意)を考えますと、
マス数: 手詰まり形: 各マスの数字を作るのに必要な4の数
2マス: 2, 4 → 0, 1
3マス: 2, 4, 8 → 0, 1, 2
4マス: 2, 4, 8, 16 → 0, 1, 2, 4
となります。
Nマスにおいて、手詰まりまでに生成された4の数S(N, 4) は、初項1、公比2、項数N-1の等比数列の和と等しいですから、
S(N, 4) = 2^(N-1) - 1
よって得られる点数は、
4 * S(N, 4)
です。
次に8が何回生成されるか?を考えますと、
マス数: 手詰まり形: 各マスの数字を作るのに必要な8の数
4マス: 2, 4, 8, 16 → 0, 0, 1, 2
となります。
生成される新しい数字が倍になり(つまり4が出てくると考える)、マスは1つ減った、と考えるとわかりやすいですかね?
S(N, 8) = S(N - 1, 4)
なので得られる点数は、
8 * S(N - 1, 4)
です。
さらに一般化するとNマスで手詰まりしたとき、それぞれのマスに存在する数は、
2, 4, 8, 16, ..., 2^N
となります。
一般項をAnとおくと、
An = 2^n (ただしn = 1, 2, ..., N)
です。
各数値が何回生成されるかを4を基準に考えると、
S(N + 1, 4), S(N, 4), S(N - 1, 4), ..., S(2, 4)
と表せます。
一般項をSnとおくと、
Sn = S(N + 2 - n, 4) = 2 ^ (N + 2 - n - 1) - 1 = 2 ^ (N - n + 1) - 1
(ただしn = 1, 2, ..., N)
と表せます。
各数値を生成する際に得られる点数は、AnとSnの積を合計した値になります。
0 * S(N + 1, 4), 4 * S(N, 4), 8 * S(N - 1, 8), ..., 2^N * S(2, 4)
しかし2048のルールでは2の生成時に点数は入りませんので、初項A1 * S1を除く必要があります。
記号を使って少しかっこよく書けば、
N
Σ(Ak * Sk) - A1 * S1
k=1
となり、このとき、
Ak * Sk = 2^k * (2^(N - k + 1) - 1) = 2^(N + 1) - 2^k
A1 * S1 = 2^(N + 1) - 2
です、かね。たぶん。
先ほどの最高得点の式、試しにN = 16で計算してみると1835012点、つまり183万点です。経験上2048を1つ作った時点で2万点程度ですので、どれだけ理不尽な数かがわかると思います…。
4だけ出てくる場合
前節では183万点と計算しましたが、新規に生成される数値が4だけだった場合は、手詰まりの形は2だけの時の65536のさらに倍の数字131072まで生成可能です。
つまりNマスで手詰まりしたとき、それぞれのマスに存在する数は、
4, 8, 16, 32, ..., 2^(N + 1)
となります。
一般項をAnとおくと、
An = 2^(n + 1) (ただしn = 1, 2, ..., N)
です。
前節で求めた点数の総和の式に当てはめてN = 16を計算すると3670024点となります。うーん367万点ねー…普通にやっていたらまず無理ですね。
しかし2048では2だけでも4だけでもなく、両方とも新規生成されます。これは4だけが新規生成される場合と比較して、空いているマスさえあれば4を生成することができるため、最高得点はさらに上がある、ということです。
また今度にでも考えます…。
コメント一覧
- りょうさん(2014/06/07 05:42)
はじめまして.
私も同じ仮定で考えていたのですが,最高点は3932100点になるとの結果が得られたので,ご報告致します. - すずきさん(2014/06/07 20:21)
>りょうさん
ご報告ありがとうございます。
393万点は 2 と 4 が適切に出てくる場合の点数でしょうか?
2 か 4 だけ出てくる場合を仮定されていれば、私と違う式を導かれたか、私が計算間違いしてますね…。 - りょうさん(2014/06/08 01:19)
393万点は,うまいこと 2 と 4 が出てくる場合の点数として求めたものです.
どちらかのみで仮定して場合はここに書かれているものと同じ結果になりました. - すずきさん(2014/06/08 03:48)
>りょうさん
なるほど、ありがとうございます。良くポカミスするので、同じ結果が得られて安心しました。
残るは盤面を 1次元にして良い、という仮定が正しいか?ですが…、残念ながら私はノーアイデアです…。 - りょうさん(2014/06/08 15:11)
私もちょくちょくやらかすので同じ結果になった人がいてよかったです.
私は,
(2 が出続けるときは) 2^n のタイルを作るには 2 つの 2^(n-1) のタイルが必要で,この 2 つのタイルを合わせるときに 2^n 点加算.
この 2 つの 2^(n-1) のタイルを 4 つの 2^(n-2) のタイルから作るときに 2^n 点加算.
…
これを繰り返して,1 つの 2^n のタイルを作るとき (n-1)・2^n 点加算される,というのをもとに,
(最高得点)=Σ[n:1…16](上の式)
から求めてみたんですよね.
(最終的な式は同じになると思いますが,アプローチのしかたがここのサイトとは少し違った気がしたので一応書いておきます)
4 のみのときや両方のときも,1 つのタイルによる点数の合計をもとに考えました.
それで,件の,1 次元に落としていいか,ですが,
私もノーアイデアですね...
手詰まり形を考えれば,2 次元のときに 1 次元のときの点数を超えないのは示そうですが...
下回らないことはどう示せばいいものか...
この記事にコメントする
2014年5月13日
DynDNSのドメインが失効した
家に置いているサーバのドメイン(katsuster.dyndns.org)はDynDNSの無料DDNSを利用していたのですが、今年の5月でDynDNS無料サービスの提供が終了したとのことで、ドメインが失効してしまいました。
家のサーバにアクセスできないのは不便だな。でも、全く次を考えていなかった。どうしようかな…。
コメント一覧
- コメントはありません。
この記事にコメントする
2014年5月14日
自宅サーバ復活
先日DynDNSのドメインが失効してしまい、外から自宅のサーバにアクセスする手立てがなくなってしまいました。
復活させようと思い、他のDDNSが可能なサービスを調べていたのですが、しっくりくるところがありません。もう有償しかないか?と思ってVALUE DOMAINを見ていたら、今使っているドメイン名(katsuster.net)でDDNSが使えることに気づきました。
なんということでしょう、VALUE DOMAINにはずっとお世話になっていたのに、今までずっと気づかなかったのです…。
これを使わない手はないのでwww2.katsuster.netというホスト名を自宅サーバ用に割り当てました。ホスト名を追加しただけなので、追加料金も要らないし、DDNS機能も便利でwgetなどでGETリクエスト送るだけでIPアドレスが更新できます。確認していませんがDiCEも使えるようです。
一時はどうなるかと思いましたが、あっさり復活できて良かった良かった。
コメント一覧
- コメントはありません。
この記事にコメントする
2014年5月16日
Kindle Fire HD絶不調
目次: Kindle
最近、Kindle Fire HD 8.9で本を買おうとすると、尋常じゃなく遅くなってなかなか本が買えない上に、ホーム画面に戻るとき1分くらい固まったまま待たされて、非常につらい。
スリープからの復帰も数秒掛かるし、壁紙が出ず背景が真っ黒。
再起動したらさらにひどくなった。何が起きてんだ、これ…。
メモ: 技術系の話はFacebookから転記しておくことにした。
コメント一覧
- コメントはありません。
この記事にコメントする
2014年5月24日
はじまりとおわり
国道には○○号線、と番号が振られていて、重なっている区間もあります。中には始点や終点が別の国道と重なっている場合もあります。
じゃあ、国道の始まりと終わりは誰が決めるのか?と疑問に思い調べてみると、道路法に基づいた「一般国道の路線を指定する政令」(昭和四十年三月二十九日政令第五十八号)という政令で決められているそうです。
道路法といい、政令といい、何の捻りもないストレートな名前です。わかりやすいのでありがたくもあり、あまりにあっさり見つかったのでやや物足りなくもあり。うーん…。
試しに一つ調べてみる
我が家からもっとも近い国道はR171です。試しにR171について調べてみましょう。
先の政令58号によれば、国道171号線の起点は京都市、終点は神戸市です。重要な経過地は、向日市、長岡京市、京都府乙訓郡大山崎町、高槻市、茨木市、箕面市、池田市、伊丹市、尼崎市、西宮市(河原町)、芦屋市(清水町)です。
あれ?これだけ?どうも政令58号では具体的な位置(交差点名、何号線に吸収される、など)は言及していないようです。
詳細な位置
道路整備促進期成同盟会全国協議会が発行していた「道路時刻表」によると、道路を走行した際の所要時間の概算値を見ることができます。
走行時間の付属情報として、始点、主な交差点(と交差する道)、終点も書いてあるため、どこで何の道が重なっているかがわかります。本来の用途と異なる使い方ですが、この際わかれば何でも良いのです。
が、しかし道路時刻表は2008年で絶版とのこと。うーん、最新の情報はどこにあるんですかねえ…。
コメント一覧
- コメントはありません。
この記事にコメントする
2014年5月25日
企業も生きている
企業の生涯を追うと、若い時は素早くて何でもチャレンジするけれど、時が経つと緩慢で億劫になって何もしなくなり、やがて体が動かなくなって息絶えるんです。
なんか、企業と生き物って似ているなーと思ったら、色々浮かんできました。
- 不採算部門のレイオフ
- 内臓切るような外科手術、あるいはスタンガンですかね。体力が激減するし、調子に乗って何度もやればショック死です。
- 税金での救済
- 死体のゾンビ改造術のようなもん?ゾンビは周りにいる健康な人を襲うため、市場に悪影響が出る、ってな感じです。
メモ: 技術系の話はFacebookから転記しておくことにした。
コメント一覧
- コメントはありません。
この記事にコメントする
2014年5月30日
自作エミュレータ - ワード幅とハーフワード読み出し
目次: Linux
RISC CPUにはワード幅での読み書きしかできないアーキテクチャがありますが、より狭いハーフワードやバイトへのアクセスってどうしているのでしょう?
単純に考えると、ひとまず近しいアドレスからワード幅で読み出して、しかるべきシフト演算を行うことで、目的のハーフワードやバイトデータを得ていそうです。
例えば、ワード幅64bits、読みたいデータ幅16bits、アクセス先のアドレスが0x12として考えてみます。
まず、データバスにはアドレス0x12ではアクセスできませんので、ひとまず0x12を超えない最大の8の倍数(64bits = 8bytes)であるアドレス0x10から64bitsを読み出します。
このときバスから読み出したデータが0x1234_5678_0246_8aceだとして、バスから読み出したデータを読みたいデータ幅(= 16bits)ごとに分割し、符号ビットから近い順から並べると、
0x1234:
0x5678:
0x0246:
0x8ace:
となります。
リトルエンディアンシステムの場合、データの上位から、アドレス+6、アドレス+4、アドレス+2、アドレスそのもの、に対応しますので、
0x1234: アドレス+6 = 0x16
0x5678: アドレス+4 = 0x14
0x0246: アドレス+2 = 0x12
0x8ace: アドレスそのもの = 0x10
と対応します。
従って目的のアドレス0x12にあるデータは0x0246であることがわかり、バスから読み出したデータをシフトすべき量は16bitsであることがわかります。
同様にアドレス0x14ならばデータは0x5678となり、シフトすべき量は32bitsです。
コードでどうぞ
このような処理をいちいち考えていると面倒で死にそうなので、コードで書いてみることにしました。
バスから読んだデータから対応するアドレスのデータを得る関数(リトルエンディアン)
public static long ADDR_MASK_64 = ~0x7L;
public static long ADDR_MASK_32 = ~0x3L;
public static long ADDR_MASK_16 = ~0x1L;
public static long ADDR_MASK_8 = ~0x0L;
/**
* @param dataLenデータ幅
* @returnアドレスマスク
*/
public long getAddressMask(int dataLen) {
switch (dataLen) {
case 64:
return ADDR_MASK_64;
case 32:
return ADDR_MASK_32;
case 16:
return ADDR_MASK_16;
case 8:
return ADDR_MASK_8;
default:
throw new IllegalArgumentException("Data length" +
String.format("(0x%08x) is not supported.", dataLen));
}
}
/*
* @param addr データのアドレス
* @param data バスから読んだデータ
* @param busLen データバス幅
* @param dataLen データ幅
* @return addrにあるデータ
*/
public long readMasked(long addr, long data, int busLen, int dataLen) {
long busMask = getAddressMask(busLen);
long dataMask = getAddressMask(dataLen);
int sh = (int)(addr & ~busMask & dataMask) * 8;
return data >> sh;
}
ふっざけんなー!意味がわからんわー!!と叫んでいる半年後の自分が見えたので、併せて解説も書いておきます。
バスから読み出したデータをシフトする量を求める部分がaddr & ~busMask & dataMask * 8の部分です。
まずaddr & ~busMaskですが、バス幅で割った余りのアドレスを求めています。
例えば、幅が64bitsでアドレスが0x12ならば、8で割った余りのアドレス0x02を求めています。
次にaddr & ~busMask & dataMaskですが、データ幅境界にアドレスを揃えています。この意味と必要性の議論は後述します。
例えばデータ幅が16bitsならば、アドレスを2の倍数にします。アドレス0x01なら0x00、アドレス0x02なら0x02、アドレス0x03なら0x02です。
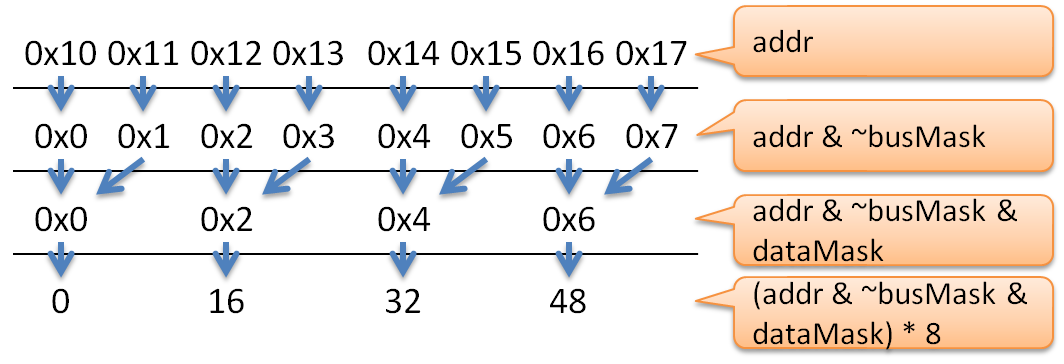
残りの処理はアドレスに8を掛けて右ビットシフトしています。関数の返値は上位に余計なデータが残っていますので、返り値を受け取った人は、余計な上位のデータを捨てる必要があります。

呼び出す側のコードは、こんな感じです。
呼び出し側の例
//データバス幅
public static int BITS_DATA_BUS = 64;
public byte read8(long addr) {
return (byte)readMasked(addr, readWord(addr), BITS_DATA_BUS, 8);
}
public short read16(long addr) {
return (short)readMasked(addr, readWord(addr), BITS_DATA_BUS, 16);
}
public int read32(long addr) {
return (int)readMasked(addr, readWord(addr), BITS_DATA_BUS, 32);
}
他のアドレスが渡される場合も同様です。


他のバス幅、他のビット幅でも同じ考え方で処理可能です。

データ幅の境界にアドレスを揃える意味
データ幅境界以外からデータを読んで良い、つまり0x13から読んだときに0x0246ではなくて、0x7802を返せるシステムならば、& dataMaskは不要です。

この方が便利ですが良いことばかりでもなく、バス幅をまたぐ際の読み出し、例えば0x17から16bits読む際の処理が必要になります。
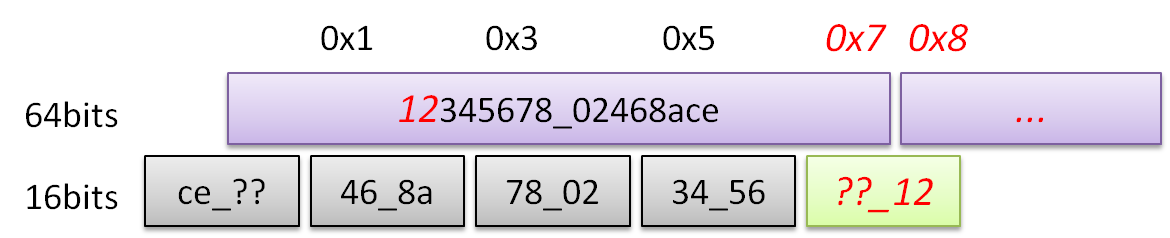
しかし前述のコードではバス幅の境界をまたぐ読み出し方に対応できませんから、データ幅境界以外からデータを読めないようにして、異常動作しないように防いでいます。
コメント一覧
- コメントはありません。
この記事にコメントする
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報