2019年4月1日

簡易CPU消費電力測定
簡易的にCPUの消費電力を測ってみました。測定ポイントはATX電源とACコンセントの間です。要はワットチェッカーでPC全体の消費電力を測っています。
アイドル状態から1スレッド、2スレッド、と負荷を増やし、
(負荷時の消費電力) - (アイドル時の消費電力) =CPUの消費電力
と見なしています。負荷には仮想通貨のマイニングソフトのベンチマークモードを使っています。それなりに複雑な計算と、スレッド数の制御が容易いので便利です。
Ryzen 7 2700のTDPは65Wなのに、消費電力が70W以上に計算されるところからわかるように、消費電力は若干多めに出ています。おそらくCPUの負荷に連動して冷却ファンが回ること、ATX電源の変換効率が負荷によって変わること、などが原因だと思われます。

Ryzen 7 2700は8コア16スレッドですが、5スレッドを超えた辺りから、フルパワーの消費電力とあまり差がなくなります。
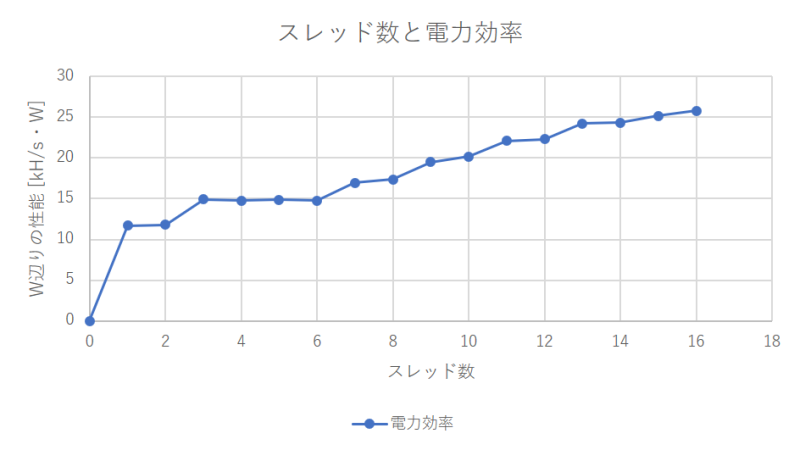
またW辺りの計算効率(kH/s・W)を計算すると、16並列が一番効率が良いです。逆に5〜6スレッド程度だと効率が悪いです。中途半端な並列度で計算するくらいなら、16スレッドフルに使いきれということですね。
コア優先で割り当てたらどうなるか?
上記の実験方法を見て「スレッドをどのCPUに張り付けるかを制御しなくても良いのか?」疑問に感じた方、さすがです。手抜きしていたことがバレましたね。
マイニングソフトのコードを見たら、ちょいと改造すれば簡単にスレッドのaffinityを設定できそうだったので、改造してもう一度測りました。
まずRyzen 7 2700はSMT構成になっていまして、1コアが2スレッド実行可能(OSからは1コア =2 CPUとして扱う)です。私の環境Debian Testingだと、
- CPU 0: コア0スレッド0
- CPU 1: コア0スレッド1
- CPU 2: コア1スレッド0
- CPU 3: コア1スレッド1
- ...
以上のように割り当たるようです。ここで素直にCPU 0から順にスレッドのaffinityを設定すると、1つのコアに2スレッドずつ張り付きます。どういうことかと言いますと、4スレッド起動したとき、コア0とコア1に2スレッドずつ張り付いて、他の6コアはヒマになるということです。これはあまり効率が良くなさそうですよね?
今回の測定では、コアを使い切ることを優先してスレッドを割り当てました。当然ながら16スレッドの性能は変わらないのですが、途中の傾向が少し変わります。

消費電力は4コアの時点でピークにかなり近くなります。8コアじゃないのは何ででしょうね?2コアがペアで電源制御されているんでしょうか……?
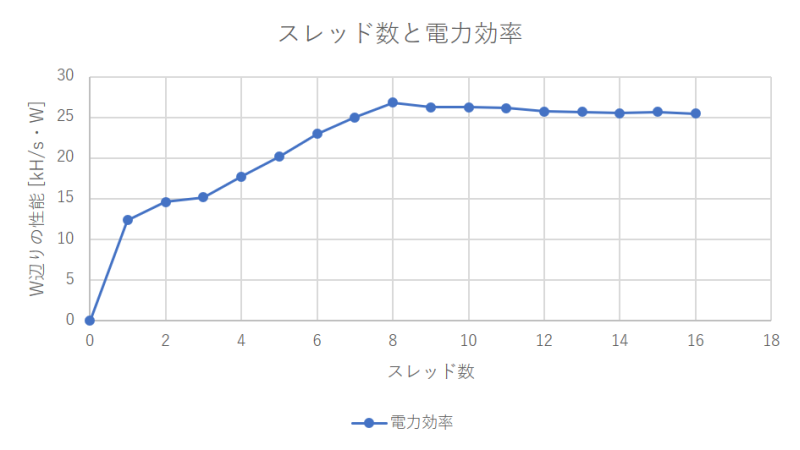
電力効率は8スレッドが最大で、16スレッドに向かってやや下がります。SMTの特徴が出ている感じがします。
メモ: 技術系の話はFacebookから転記しておくことにした。多少修正。
コメント一覧
- hdkさん(2019/04/02 22:48)
去年Ryzen 7 1700で測りましたがやはりTDPより少し高めでした: http://www.e-hdk.com/diary/d201808b.html#15-1 - すずきさん(2019/04/05 11:03)
どの CPU というかシステムでも同じ傾向ですね。CPU の消費電力だけ測れているわけではないですし、そんなもんかなーと思いました。
 この記事にコメントする
この記事にコメントする
2019年4月12日
ぼやけるWindows
以前の日記(2019年3月17日の日記参照)で、Windows Updateのあとにウインドウのタイトルがズレてしまう話を書きました。
その際に同時に発生する画面がぼやけてしまう現象についてもスクリーンショットを取ったので載せておきます。
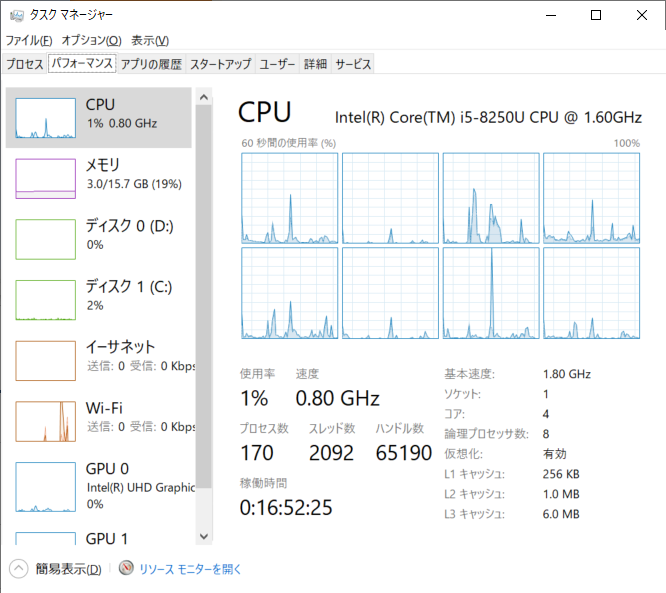
このようにフォントがボヤけてしまいます。タスクマネージャの場合はあまり目立ちませんが、アプリケーションによってはさらに顕著です。
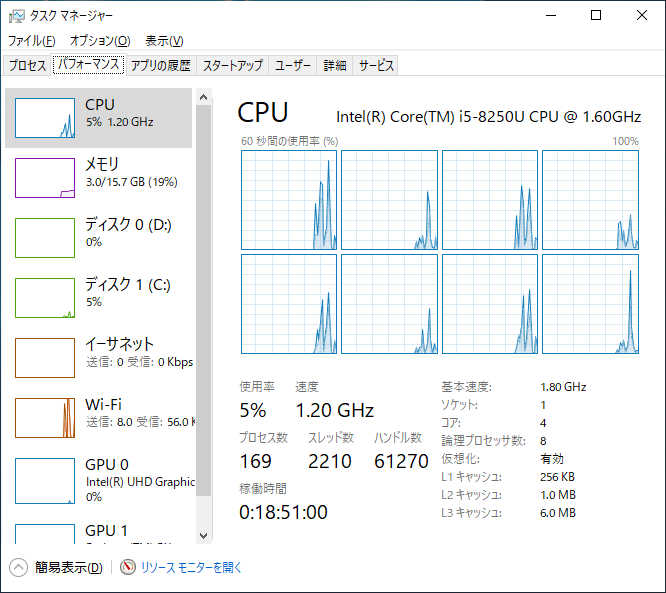
前回は「再起動で直る」と書きましたが、サインインしなおすだけでも直るようです。
ボヤける理由の予想
ざっくりいうと、Windows Updateがテキストサイズの拡大縮小設定を元に戻した後に、サインインしなおさないからじゃないか?と思っています。
Windows 10にはアプリケーションのテキストサイズを調整する機能があります。[Windowsの設定] -> [システム] -> [ディスプレイ] から設定できます。
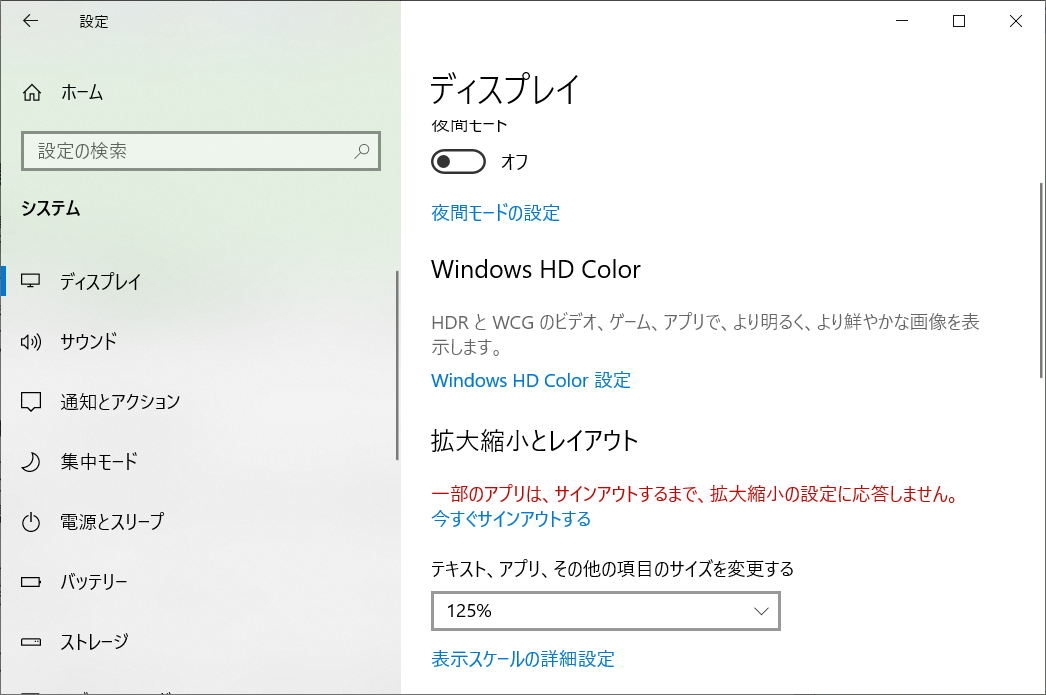
設定変更すると一部のアプリは、サインアウトするまで、拡大縮小の設定に応答しません、という警告文が表示されます。
購入当初は125% の設定になっていました。初期値はディスプレイの物理的なサイズと解像度によって決まっているそうです。あと、私は拡大縮小の設定を「100%」に変更して使用しています。
以上から導いた私の予想ですが、
- Windows Updateによって、テキストサイズの設定が初期値(125%)に戻る
- Windows UpdateがPCを再起動する
- アプリケーションがテキストサイズ125% で表示する
- Windows Updateがユーザーが使っていたテキストサイズ設定(私の場合100%)に設定しなおす
- サインアウトは行わないため、アプリケーションがついてこられずボヤけてしまう
こんな状態になっているのではないかと思っています。
コメント一覧
- コメントはありません。
この記事にコメントする
2019年4月13日
レジスタダンプ、書き換えツールmemaccess - ちょっと修正
先日(2019年3月24日の日記参照)作ったmemaccess(GitHubへのリンク)細かい部分が色々バグっていたので直しました。
- 32bit環境でビルドできない
- ビルド時にlibtoolを要求する(本来は要らない)
- 0x80000000_00000000以上のアドレスを指定すると0x7fffffff_ffffffffになってしまう
- 32bitを超える値を書き込めない
アドレスの指定は文句なしで64bit符号なし整数にしましたが、書き込む値については64bitの符号つき整数(今はこっち)と64bitの符号なし整数の、どっちが良いんでしょうね。贅沢を言えば、どちらも使いたいですけど。
コメント一覧
- コメントはありません。
この記事にコメントする
2019年4月18日
LinuxのDMAとキャッシュフラッシュ
目次: Linux
昨今のキャッシュを持ったCPUでは、DMAを行う際にCPUのキャッシュのフラッシュ(ダーティデータをメインメモリに書きだす、パージともいう)やインバリデート(キャッシュから消しさる、クリーンともいう)が必須です。
しかしアーキテクチャやCPUの実装によってキャッシュの操作方法は異なるため、LinuxではDMA APIというレイヤでアーキテクチャの差分を隠蔽しています。
LinuxでDMAを行うドライバを書くときの一番単純な作法(=単一の領域にDMAを行う、スキャッターギャザーなどはしない)は、
- dma_alloc
- バッファ確保
- dma_map_single
- バッファをCPUのメモリ空間にマップし、CPUから見えるようにする
- dma_sync_single_for_cpu
- CPUからバッファをアクセスする準備
- CPUからバッファにデータを書き込む
- dma_sync_single_for_device
- デバイスからバッファをアクセスする準備
- デバイスからDMAを行いデータを読み込む
- dma_unmap_single
- バッファのマップをやめる
- dma_free
- バッファ解放
ざっくりいってこのような感じです。先ほど述べた通り、LinuxのDMA APIにキャッシュのフラッシュやインバリデート関数はありません。ハード依存の操作をなるべく減らし、多数のアーキテクチャに対応しやすくなっているんですね。
実際はいつフラッシュしているのか?
そうはいっても、実際にどこでキャッシュフラッシュしているか、気になると思います。昔、Linux 4.4を調べた情報を引っ張り出してきました。アーキテクチャはAArch64つまり64bitのARMコアです。
AArch64の場合、キャッシュ操作をしているのはdma_sync_single_for_cpu() とdma_sync_single_for_device() です。前者がインバリデート、後者がフラッシュ+インバリデートを行っています。
前者のdma_sync_single_for_cpu() を追いかけてみると、
- dma_sync_single_for_cpu()
- 関数ポインタ経由でops->sync_single_for_cpu() を呼びます。AArch64の場合opsには通常 swiotlbのDMA操作関数が入っています。ですので __swiotlb_sync_single_for_cpu() が呼ばれます
- __swiotlb_sync_single_for_cpu()
- コヒーレントバッファでない(キャッシュフラッシュがいる)場合 __dma_unmap_area() を呼びます
- __dma_unmap_area()
- __dma_inv_range() を呼びます
- __dma_inv_range()
- キャッシュをインバリデートします
こんな感じですね。しつこいですがAArch64の実装を見ただけですので、将来的に変わるかもしれないし、他のアーキテクチャでは仕組みが違います。
直接フラッシュしたがるおじさん
昔のLinuxではキャッシュ操作関数をドライバから使うことができました。その記憶からなのか、たまにフラッシュやインバリデートのようなアーキテクチャ依存の操作を直接呼びたがる人がいます。
今のLinuxではキャッシュ操作関数は当然ありますが、ドライバからは呼べない、つまり呼ぶことを推奨していません。もちろんオープンソースなので改造すれば何でもできますけど、メンテナンス性や再利用性、移植性を下げるだけで、損しかないでしょう。
コメント一覧
- コメントはありません。
この記事にコメントする
2019年4月19日
RISC-V SoC搭載ボード探し
目次: RISC-V
Linuxが動くくらいのRISC-VのSoC搭載ボードを探していたのですが、どうやらまだ市販されてなさそうでした……。
代わり(?)にSiFiveの高性能RISC-V SoCであるHiFive Unleashed(リンク)のマニュアルを眺めていました。
HiFive Unleashedは高性能と紹介されていることが多いですが、現状RISC-VはArduinoくらいの小規模SoCがほとんどで、それらと比較して高性能、と言っているのだと思われます。
特に珍しい機能もないですし、最近のテレビやタブレット向けの巨大なARM系SoCと比べると、どうしてもショボく見えてしまうのは仕方ないでしょう。
ああ、でもErrataの章があるのは珍しいかもしれません。
- ROCK-2: High 24 address bits are ignored
- Workaround
Do not access out-of-bound addresses in software. - I2C-1: I2C interrupt can not be cleared
- Workaround
Poll the I2C controller state to wait for TIP (transaction in progress) to go low.
などの豪快なバグがある様子が伺えます。特にROCK-2のWorkaroundは全然Workaroundになっておらずのが面白いです。アクセス違反をするな、と言ってアクセス違反がなくなるならOSの苦労はないでしょ。かなり悲惨なバグです。
ボードには修正したSoCを載せるのか、バグったSoCを強引に搭載するのか、どちらなんでしょうね……。
メモ: 技術系の話はFacebookから転記しておくことにした。
コメント一覧
- コメントはありません。
この記事にコメントする
2019年4月27日
クロスビルド用ツールチェーン - その1
目次: GCC
先日(2019年3月27日の日記参照)クロスビルド向けLLVMのビルド方法がわかったので、今度はクロスビルド向けGCCのツールチェーン(超基本的なbinutils + GCC + glibcの組み合わせ)を作ろうとしていますが、さっぱりうまくいかないです。
そもそもどのバージョンの組み合わせならビルドが通るのか全くわかりません……。対象となるクロス環境(ARM向けなのか、RISC-V向けなのか)と、ホスト側のコンパイラバージョンが影響するようで、昔ビルドが通っていた組み合わせを引っ張り出してきても、今の環境だとビルドが通らないなんてことがおきます。
やりたいこと
ビルドできる組み合わせは頑張れば見つけられるとは思いますが、本来やりたいことはクロスビルド用のコンパイラのソースコードリポジトリをダウンロードし、自分でソースコードに何か変更を入れ、変更した内容も含めてビルドすることです(ダウンロードは最悪手動でも良いですけど)。
世の中にはクロスビルド用のツールチェーンを作成できるツールはいくつかありますが、いずれもtarballからのビルドを想定していて、改変を入れて再ビルドする方法が良くわかりません。
ツールが想定しているリリース用のビルドは、
- リリースバージョンのtarballか、ソースコードリポジトリのリリースタグを持ってきてビルド
- 実機で使える形、インストーラなどにパッケージング
開発用は、リリース用に加え、
- 最新のソースコードリポジトリを持ってくる
- ソースコードに素早くアクセス、改変
- 改変した部分だけ差分ビルド
- (必要なら)モジュールを足す
が必要ですが、意外とできないです……。
クロスビルド用ツールチェーンを作成できるツール
いくつかツールを調べてみました。
- Yocto
-
ソースコードはアクセスしづらいです。例えばAGL(Yoctoを使っています)は、
agl/build/tmp/work-shared/gcc-8.2.0-r0/gcc-8.2.0/
に置かれます。何回見ても覚えられません。
ソースコードの改変はできますが、bitbakeはソースコードの変更を認識しないようです。bitbakeにモジュールを明示的に指定すれば良さそうです。もしくはパッチを作ってレシピに足してbitbakeするのがYocto的には正しいのかな?どちらにせよ面倒です。
新たにモジュールを足す方法は、レシピを足すだけなので簡単だと思いますが、それ以外が辛すぎます。開発用には向いていません。 - crosstool-NG
-
ソースコードは、
crosstool-ng/.build/src/gcc-8.2.0/
にあります。アクセスしやすいです。
ソースコードの改変は反映されますが、差分ビルドはしないようで、./ct-ng buildとすると全てビルドしなおされます。ちょっと微妙です。
新たなモジュールの追加はどうやるのかわかりません。Yoctoなどとは違い、コンパイラなどのツールチェーンをビルドする専用ツールなので、Linuxカーネルやbusyboxはビルドしません。足すものはあまりないんじゃないでしょうか。 - buildroot
-
ソースコードは、
buildroot/output/build/host-gcc-final-7.4.0/
にあります。Yoctoよりわかりやすいです。
ソースコードの改変は認識されていないように見えます。ソースコードを変更してmakeしても何もビルドされません。
新たなモジュールの追加方法は知らないですが、比較的簡単なのかな…?
ツールチェーン単体だとcrosstool-NGですし、将来的に追加するものを考えるとbuildrootが良さそうですけど。変更を反映して差分ビルドする方法ないのかな……??
コメント一覧
- コメントはありません。
この記事にコメントする
2019年4月29日
クロスビルド用ツールチェーン - その2
目次: GCC
引き続き、超基本的なbinutils + GCC + glibcの組み合わせのクロスビルド環境を作っています。やや苦戦したものの、ARM, AArch64, RISC-V 64でビルドが通りました。良かった良かった。
残念ながらRISC-V 32はglibcが対応しておらず、libcなしのベアメタル向けコンパイラしか作れませんでした。glibc does not yet support 32-bit systemsと怒られます。glibcの代わりにnewlibなどを使えば、libcありのLinux向けコンパイラが作れるかもしれませんが、試していないのでわかりません。
環境
昔作ったクロスコンパイラをビルドするMakefile(GitHubへのリンク)を改造して、作りました。
前回(その1)検討した通り、本格的に運用するなら独自のビルドツールよりcrosstool-NGかbuildrootに切り替えた方が良いと思います。
ビルド方法
詳細はGitHubを見た方が良いですが、configureに指定しているオプションだけ、ざっと列挙しておきます。
変数の定義(イメージ)
CROSS_ARCH = riscv64-unknown-linux-gnu
TOP_DIR = `pwd`
CROSS_ROOT = $TOP_DIR/buildroot
PREFIX ?= $(CROSS_ROOT)
SYSROOT ?= $(CROSS_ROOT)/$(CROSS_ARCH)/sysroot
まずbinutilsは、
binutilsのconfigure
./configure \
--target=$(CROSS_ARCH) \
--prefix=$(CROSS_ROOT) \
--disable-nls \
--disable-static \
--disable-werror \
--with-lib-path=$(CROSS_ROOT)/lib \
--with-sysroot=$(CROSS_ROOT)
次にgccは、
gcc 1回目 のconfigure
./configure \
--target=$(CROSS_ARCH) \
--prefix=$(PREFIX) \
--enable-languages=c \
--disable-libatomic \
--disable-libitm \
--disable-libgomp \
--disable-libmudflap \
--disable-libquadmath \
--disable-libsanitizer \
--disable-libssp \
--disable-libstdcxx-pch \
--enable-long-long \
--enable-lto \
--disable-multiarch \
--disable-multilib \
--disable-nls \
--disable-plugin \
--disable-shared \
--disable-threads \
--disable-__cxa_atexit \
--without-headers \
--with-local-prefix=$(SYSROOT) \
--with-sysroot=$(SYSROOT) \
--with-newlib
難関のglibcはこんな感じ、
glibcのconfigure
./configure \
--host=$(CROSS_ARCH) \
--prefix=$(SYSROOT)/usr \
--disable-profile \
--disable-multilib \
--enable-add-ons \
--enable-kernel=3.0.0 \
--disable-multi-arch \
--enable-obsolete-rpc \
--with-binutils=$(PREFIX)/bin \
--with-headers=$(SYSROOT)/usr/include \
--with-sysroot=$(SYSROOT)
最後にglibcを動的リンク可能なgccは、
gcc 2回目のconfigure
./configure \
--target=$(CROSS_ARCH) \
--prefix=$(PREFIX) \
--enable-languages=c,c++,fortran \
--enable-libatomic \
--disable-libitm \
--enable-libgomp \
--enable-libmudflap \
--enable-libquadmath \
--disable-libsanitizer \
--enable-libssp \
--enable-libstdcxx-pch \
--enable-long-long \
--enable-lto \
--disable-multiarch \
--disable-multilib \
--enable-nls \
--enable-plugin \
--enable-shared \
--enable-threads=posix \
--enable-__cxa_atexit \
--with-local-prefix=$(SYSROOT)/usr \
--with-build-sysroot=$(SYSROOT) \
--with-sysroot=$(SYSROOT) \
--with-native-system-header-dir=/usr/include
この設定が正しいかどうか確証は持てませんが、printfを呼び出すCソースコードをエラーなくビルド可能なコンパイラが作成できるので、良しとします。
引っかかったポイント
色々引っかかったのですが、覚えている限りのエラーと自分が取った対策を列挙しておきます。
- どのバージョンのライブラリを組み合わせれば良いかわからない
- 私はDebianなどの既存Linuxディストリビューションが採用しているバージョンを参考にしました。ホスト側のコンパイラのバージョンも影響するため、昔ビルドが通っていた組み合わせでもビルドが通らないことはあります。
- AArch64に変えるとglibcビルドエラー
- エラーの内容はredefinition of 'struct user_regs_structでした。何それ……??と思いきや、sysrootにインストールしたLinuxカーネルヘッダがRISC-V向けになっていた凡ミスでした。
- glibcビルドエラー
- エラーの内容はenable-multi-arch support require gcc, assembler and linker indirect-function supportでした。これは解決方法がわからんので、GCCのconfigureに --disable-multi-archを指定し、回避しています。
- gccビルドエラー
- エラーの内容はPthreads are required to build libgompでした。これはややこしいので、別建てで書きます。
gccビルドエラー(詳細)
エラーメッセージだけ読むとさっぱりですが、config.logに記録されたテストプログラムとテスト結果によれば、pthread.hが見当たらないと言っているようです。
- GCCのconfigureに --enable-libgompを指定したため、libgompがビルドされている
- libgompはpthread.hが見つからないのでPthreads are required to build libgompと文句を言っていた
もちろんGCCの前にglibcのクロスビルドに成功しているので、pthread.hは存在しているものの、
- glibcのヘッダをインストールする場所を間違えていた
- gccの --with-native-system-header-dirに指定したパスが間違っていた
これらの原因によって、pthread.hが見えなくなっていたようです。
感想
ツールチェーン構築って大変です。実際に体験すると、crosstool-NGやbuildrootのありがたさが身に沁みます。
コメント一覧
- コメントはありません。
この記事にコメントする
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報