2020年7月1日

STATIONflowランク100
目次: ゲーム
STATIONflowのランクが100になりました。何か実績と紐づいているかなと思いましたが、特に何も起きませんでした。しょんぼり。
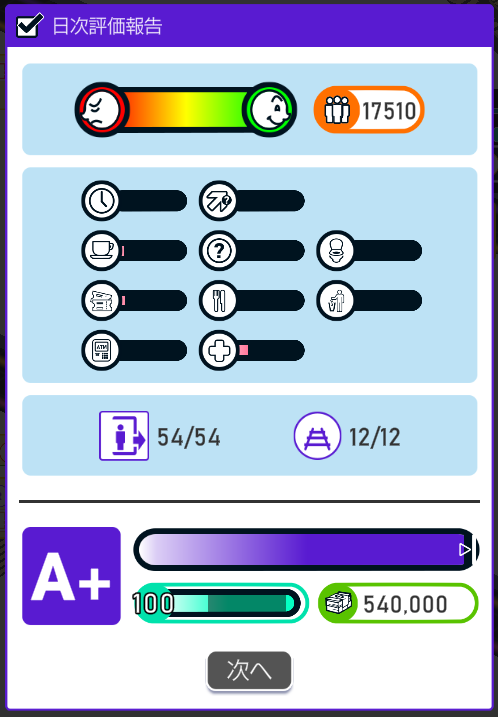
普通のマップだと重いし、時間も掛かりすぎてやってられないので、専用の軽量マップを作ってひたすら待ちました。それでも相当時間が掛かります。普通に遊ぶ分にはランク50で十分ですね。
わかったこと
STATIONflowでランク100にする途中でいくつかわかったことがありました。
- 集客レベル
-
途中で出入口と乗り場の集客レベルがカンストし、変化もやることもなくなります。実績解除に必要なランク50以降はほぼ無意味です。
集客レベルの上がる余地は最大132(※)なので、ランク100まで上がり続けるかと思いきや、ランク1上がるごとに集客レベルが2〜4くらい上がるので、だいたいランク60くらいでカンストします。 - 評価収入
- ランクとは無関係で、出入口と乗り場の集客レベルの合計に依存するようです。出入口と乗り場を最大数作り、集客レベルを全て最大にして、ランクA+ を取ったときが540,000 でした。おそらくこれが最大値です。
ランク100まで行ってもまだ取れない実績が残っていて(ラッキーセブン、トウキョウ)、なかなか気が遠くなるゲームです。
(※)出入口が6 x 9 = 54、乗り場が6 x 2 = 12、集客レベルは2段階上がるため (54 + 12) x 2 = 132です。
実績のtypo
STATIONflowの実績にtypoがありました。

漢字だけ間違ってます。惜しい……!
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2020年7月2日
Steamの秘密の実績を暴く方法
目次: ゲーム
Steamの買い物カートの中身一覧を見る方法を探していたんですが、全くわかりませんでした。だいぶ彷徨いましたが、未だトップ画面からカートを見る方法はわからないままです。Steamは本当にUIがひどい。Amazonを見習ってくれ……。
その際に副産物として、秘密の実績を確認する方法を見つけたのでメモしておきます。
- Steamのウインドウ
- ユーザー名のタブ
- プロフィール
- 最近プレイした全てのゲーム
- すべてのゲーム
と辿ると自分が所持しているゲームの一覧が出ますから、実績を見たいゲームの
- データを表示
- グローバル実績
と辿ると全ての実績が表示されます。
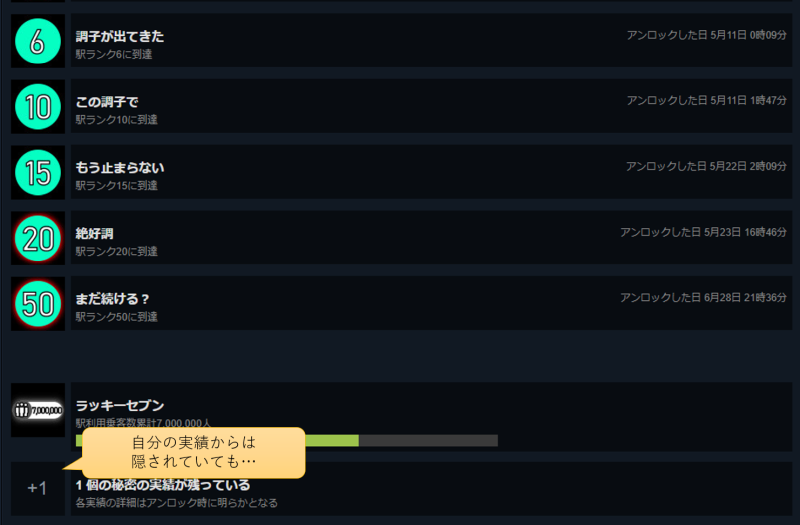

秘密の実績の意味とは一体……??
コメント一覧
- 初心者さん(2025/01/29 07:34)
Steamを見たとき、AmazonよりUIが悪いと思いました。
大きい面積に黄緑色を指定した。
マウスを重ねたとき灰色矩形が大きくなるけど、背面の灰色と明度差がない。
このブログも同じ。
登録されているゲームのほとんどは邪悪で、虐殺、暴力、戦争、殺人、魔法、偶像崇拝、卑猥、などでした。
ぷよぷよテトリスのようなものもあるけど、パズル以外の色の彩度が高すぎて目が痛い。
- すずきさん(2025/01/30 22:40)
ちょっと何を言っているのか良くわからなかったです。。。
ブログが見づらいようならすみません。
この記事にコメントする
2020年7月3日
C言語でSEGV
SEGVを出すのがTwitterで流行しているみたいなので、少し考えてみました。Twitterで見かけたのは、*a;main(){*a=0;}(16文字)です。最適化オプションにもよりますが、異常なアドレスへのmovか、未定義命令ud2が出力されてSEGVします。
16文字でSEGV
$ echo -n '*a;main(){*a=0;}' > a.c && gcc a.c
a.c:1:1: warning: data definition has no type or storage class
1 | *a;main(){*a=0;}
| ^
a.c:1:2: warning: type defaults to 'int' in declaration of 'a' [-Wimplicit-int]
1 | *a;main(){*a=0;}
| ^
a.c:1:4: warning: return type defaults to 'int' [-Wimplicit-int]
1 | *a;main(){*a=0;}
| ^~~~
$ ./a.out
Segmentation fault
ただSEGVするだけで良ければ、mainのアドレスを .textではないアドレスにすれば良いので、main;(5文字)でも、達成できます。
5文字でSEGV
$ echo -n 'main;' > a.c && gcc a.c
a.c:1:1: warning: data definition has no type or storage class
1 | main;
| ^~~~
a.c:1:1: warning: type defaults to 'int' in declaration of 'main' [-Wimplicit-int]
$ ./a.out
Segmentation fault
この例はmainを関数ではなく変数として定義し、mainをbssセクションに配置します。最近のLinuxならばデータが置かれているセグメントは実行禁止にするはずなので、mainが指すデータが何であろうと、ジャンプした瞬間にSEGV します。
趣旨とは外れますがSEGVを避けて正常終了させたければ、
SEGVしたくない場合
$ echo -n 'main=0xc3;' > a.c && gcc -z execstack a.c
a.c:1:1: warning: data definition has no type or storage class
1 | main=0xc3;
| ^~~~
a.c:1:1: warning: type defaults to 'int' in declaration of 'main' [-Wimplicit-int]
$ ./a.out
(SEGVしない)
変数mainが指す位置にretq命令(0xc3)を置いて、-z execstackオプションでデータ領域を実行可能にしています。attributeで .text領域に置いても実行できますが、そんなことするくらいならmain() 関数を書いた方が短いです。
これが最短か?
変化球を使ってよければ0文字でSEGVできます。nostdlibオプションを使います。
0文字でSEGV
$ echo -n > a.c && gcc -nostdlib a.c /usr/bin/ld: warning: cannot find entry symbol _start; defaulting to 0000000000001000 $ ./a.out Segmentation fault
GNU ld(他のリンカーでも同じだと思いますけど)はELFのエントリアドレスに _startというシンボルのアドレスを使います。通常はcrt.oなど、リンク時に自動的に追加されるオブジェクトが _startを定義しますが、nostdlibオプションによりcrt.oがリンクされなくなって、_startは未定義になります。
するとldは _startを適当なアドレスに設定(上記の例では0x1000に)します。当然 _startが指すアドレスにコードはありませんから、実行するとクラッシュします。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月4日
ELFバイナリでSEGVその1 - 92バイト
目次: ベンチマーク
昨日(2020年7月3日の日記参照)試したところによると、C言語は0文字でSEGVするプログラムを書けました。
では、出力されたバイナリだと最短はいくつでしょうか?とりあえずベースとしてC言語の0文字SEGVプログラムの出力を見ます。
0文字でSEGVのバイナリサイズ
$ gcc -nostdlib a.c /usr/bin/ld: warning: cannot find entry symbol _start; defaulting to 0000000000001000 $ ls -la a.out -rwxr-xr-x 1 katsuhiro katsuhiro 9528 Jul 3 04:11 a.out
なんと9KBもあります。readelfで見るとダイナミックリンカー関連のシンボルが含まれているようなので、staticオプションを付けてダイナミックリンカー関連のシンボルを消します。
0文字でSEGVのバイナリサイズ、static版
$ echo -n > a.c && gcc -nostdlib -static a.c
/usr/bin/ld: warning: cannot find entry symbol _start; defaulting to 0000000000401000
$ ls -la a.out
-rwxr-xr-x 1 katsuhiro katsuhiro 968 Jul 3 04:12 a.out
$ strace ./a.out
execve("./a.out", ["./a.out"], 0x7ffc92c2b390 /* 46 vars */) = 0
--- SIGSEGV {si_signo=SIGSEGV, si_code=SEGV_MAPERR, si_addr=0x401000} ---
+++ killed by SIGSEGV +++
Segmentation fault
ログが大量に出るはずのstraceも、わずか1行しかログが出ません。何もしないバイナリにも関わらずa.outのサイズは1KB近くあります。
ツールでバイナリを削る
お手軽なバイナリのダイエットとして、実行に不要なセクションをstripします。
SEGVするバイナリ、stripする
$ strip -R ".note.gnu.build-id" -R ".comment" a.out $ ls -la a.out -rwxr-xr-x 1 katsuhiro katsuhiro 376 Jul 3 04:18 a.out
それでも376バイト。まだでかいですね。
手でバイナリを削る
この376バイトのファイルを元にして、バイナリを手で削ります。加工の方針としては、
- ELFヘッダ(64バイト)とプログラムヘッダ(56バイト)を一部重ねる(-28バイト)
- 不要なプログラムヘッダ2つを消す(-56 x 2バイト)
- セクションヘッダを消す(-64 x 2バイト)
- .shstrtabセクションを消す(-16バイト)
- ELFヘッダの辻褄を合わせる
結果92バイトになりました。
SEGVするバイナリ、手で削る
$ ls -la a.out -rwxrwxr-x+ 1 katsuhiro katsuhiro 92 Jul 3 05:43 a.out

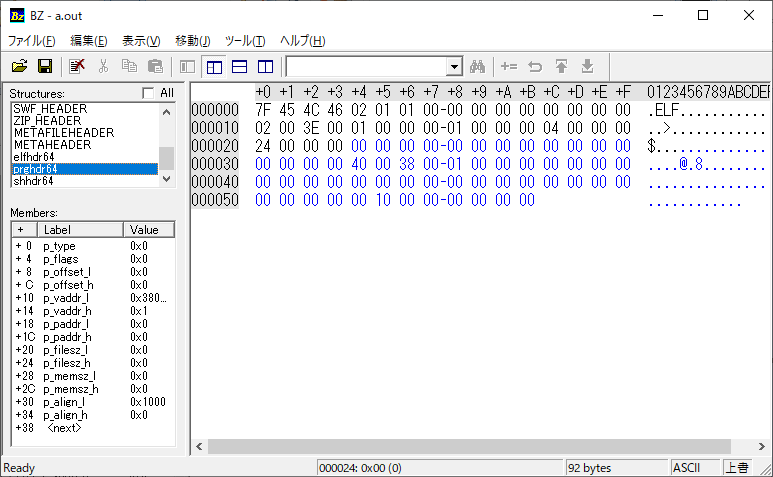
もっとアグレッシブにELFヘッダとプログラムヘッダを重ねれば、64バイトにできるかもしれません。
SEGVする92バイトバイナリの検証
このファイルを実行してみると、システムコールexecveがエラーを返さないで進むので、ELFファイルとして認識してもらえているようです。
SEGVする92バイトバイナリ、実行
$ strace ./a.out
execve("./a.out", ["./a.out"], 0x7fff2b4f74a0 /* 47 vars */) = 0
--- SIGSEGV {si_signo=SIGSEGV, si_code=SEGV_MAPERR, si_addr=0x400000001} ---
+++ killed by SIGSEGV +++
Segmentation fault
SEGVする92バイトバイナリ、readelf
$ readelf -a a.out
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x400000001
Start of program headers: 36 (bytes into file)
Start of section headers: 0 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 1
Size of section headers: 0 (bytes)
Number of section headers: 0
Section header string table index: 0
There are no sections in this file.
There are no sections to group in this file.
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
NULL 0x0000000000000000 0x0000000100380040 0x0000000000000000
0x0000000000000000 0x0000000000000000 0x1000
There is no dynamic section in this file.
There are no relocations in this file.
The decoding of unwind sections for machine type Advanced Micro Devices X86-64 is not currently supported.
Dynamic symbol information is not available for displaying symbols.
No version information found in this file.
一応readelfでも読めますし、そこそこ真っ当なファイルをキープできていると思います。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月5日
ELFバイナリでSEGVその2 - 64バイト
目次: ベンチマーク
昨日(2020年7月4日の日記参照)はSEGVするELFバイナリサイズを92バイトまで削ることができました。
その後、色々弄っていて見つけたのですが、プログラムヘッダのtypeをNULLにしておけば、ファイルサイズやオフセットがめちゃくちゃでもexecveは文句を言わないっぽいみたいです。
ELFヘッダのe_identの後半8バイトは0(前半を書き換えるとELFと認識されなくなります)なので、この部分をプログラムヘッダだよ、と指定すればtype NULLに解釈されます。
これで64バイト、つまりELFヘッダしかない実行ファイルができました。何の役にも立たないですけどね……。
SEGVするバイナリ、64バイト版
$ ls -la a.out -rwxrwxr-x+ 1 katsuhiro katsuhiro 64 Jul 3 06:39 a.out

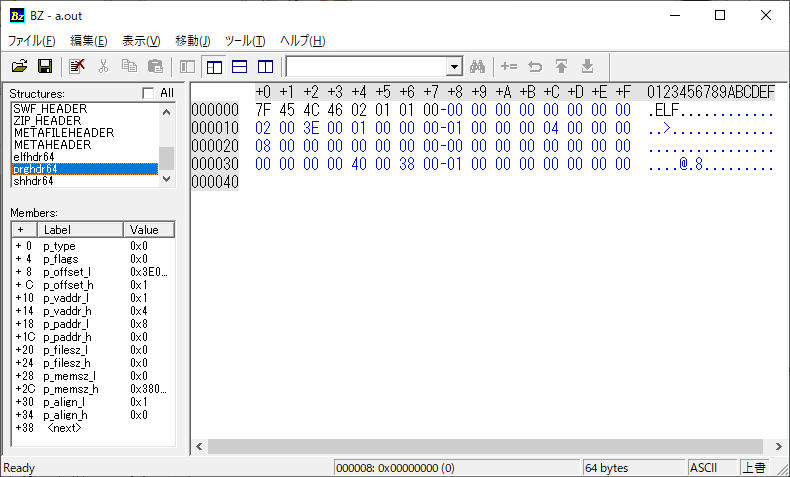
これ以上1バイトでも削るとELFヘッダの長さを下回るため、ELFバイナリとして成立しません。よって64バイトが最短だと思いますが、私が気づいていない裏技があるかもしれません。
SEGVする64バイトバイナリの検証
このファイルを実行してみると、システムコールexecveがエラーを返さないで進むので、ELFファイルとして認識してもらえているようです。
SEGVする64バイトバイナリ、実行
$ strace ./a.out
execve("./a.out", ["./a.out"], 0x7ffedf7dfa90 /* 47 vars */) = 0
--- SIGSEGV {si_signo=SIGSEGV, si_code=SEGV_MAPERR, si_addr=0x400000001} ---
+++ killed by SIGSEGV +++
Segmentation fault
SEGVする64バイトバイナリ、readelf
$ readelf -a a.out
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x400000001
Start of program headers: 8 (bytes into file)
Start of section headers: 0 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 1
Size of section headers: 0 (bytes)
Number of section headers: 0
Section header string table index: 0
There are no sections in this file.
There are no sections to group in this file.
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
NULL 0x00000001003e0002 0x0000000400000001 0x0000000000000008
0x0000000000000000 0x0038004000000000 0x1
There is no dynamic section in this file.
There are no relocations in this file.
The decoding of unwind sections for machine type Advanced Micro Devices X86-64 is not curr
ently supported.
Dynamic symbol information is not available for displaying symbols.
No version information found in this file.
一応readelfでも読めますが、プログラムヘッダのオフセットやアドレスはめちゃくちゃです。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月6日
GCCを調べる - その15-1 - 浮動小数点のロードストアになぜかベクトルレジスタが出現する
目次: GCC
以前(2020年3月27日の日記参照)ベクトルレジスタの定義を追加したとき、riscv_hard_regno_mode_ok() を変更しました。machine modeは無視して、ベクトルレジスタを指すレジスタ番号だったらとにかくtrueを返すようにしましたが、実はこの実装は正しくありません。
例えば以下のようなプログラムを書くと、おかしなことが起こります。
浮動小数点を60個使うプログラム
void _start(void)
{
static volatile float gf[60];
float f00, f01, f02, f03, f04, f05, f06, f07, f08, f09;
float f10, f11, f12, f13, f14, f15, f16, f17, f18, f19;
float f20, f21, f22, f23, f24, f25, f26, f27, f28, f29;
float f30, f31, f32, f33, f34, f35, f36, f37, f38, f39;
float f40, f41, f42, f43, f44, f45, f46, f47, f48, f49;
float f50, f51, f52, f53, f54, f55, f56, f57, f58, f59;
__asm__ volatile("nop;\n");
f00 = gf[ 0]; f01 = gf[ 1]; f02 = gf[ 2]; f03 = gf[ 3]; f04 = gf[ 4];
f05 = gf[ 5]; f06 = gf[ 6]; f07 = gf[ 7]; f08 = gf[ 8]; f09 = gf[ 9];
f10 = gf[10]; f11 = gf[11]; f12 = gf[12]; f13 = gf[13]; f14 = gf[14];
f15 = gf[15]; f16 = gf[16]; f17 = gf[17]; f18 = gf[18]; f19 = gf[19];
f20 = gf[20]; f21 = gf[21]; f22 = gf[22]; f23 = gf[23]; f24 = gf[24];
f25 = gf[25]; f26 = gf[26]; f27 = gf[27]; f28 = gf[28]; f29 = gf[29];
f30 = gf[30]; f31 = gf[31]; f32 = gf[32]; f33 = gf[33]; f34 = gf[34];
f35 = gf[35]; f36 = gf[36]; f37 = gf[37]; f38 = gf[38]; f39 = gf[39];
f40 = gf[40]; f41 = gf[41]; f42 = gf[42]; f43 = gf[43]; f44 = gf[44];
f45 = gf[45]; f46 = gf[46]; f47 = gf[47]; f48 = gf[48]; f49 = gf[49];
f50 = gf[59]; f51 = gf[51]; f52 = gf[52]; f53 = gf[53]; f54 = gf[54];
f55 = gf[55]; f56 = gf[56]; f57 = gf[57]; f58 = gf[58]; f59 = gf[59];
__asm__ volatile("nop;\n");
gf[ 0] = f00; gf[ 1] = f01; gf[ 2] = f02; gf[ 3] = f03; gf[ 4] = f04;
gf[ 5] = f05; gf[ 6] = f06; gf[ 7] = f07; gf[ 8] = f08; gf[ 9] = f09;
gf[10] = f10; gf[11] = f11; gf[12] = f12; gf[13] = f13; gf[14] = f14;
gf[15] = f15; gf[16] = f16; gf[17] = f17; gf[18] = f18; gf[19] = f19;
gf[20] = f20; gf[21] = f21; gf[22] = f22; gf[23] = f23; gf[24] = f24;
gf[25] = f25; gf[26] = f26; gf[27] = f27; gf[28] = f28; gf[29] = f29;
gf[30] = f30; gf[31] = f31; gf[32] = f32; gf[33] = f33; gf[34] = f34;
gf[35] = f35; gf[36] = f36; gf[37] = f37; gf[38] = f38; gf[39] = f39;
gf[40] = f40; gf[41] = f41; gf[42] = f42; gf[43] = f43; gf[44] = f44;
gf[45] = f45; gf[46] = f46; gf[47] = f47; gf[48] = f48; gf[49] = f49;
gf[50] = f50; gf[51] = f51; gf[52] = f52; gf[53] = f53; gf[54] = f54;
gf[55] = f55; gf[56] = f56; gf[57] = f57; gf[58] = f58; gf[59] = f59;
__asm__ volatile("nop;\n");
}
最適化O1以上でビルドするとinternal compile errorが発生します。
reloadでコンパイルエラー
$ riscv32-unknown-elf-gcc b.c -march=rv32imafcv -mabi=ilp32f -O3 -Wall -fno-builtin -fno-inline -nostdlib -g
b.c: In function '_start':
b.c:52:1: error: insn does not satisfy its constraints:
52 | }
| ^
(insn 562 17 18 2 (set (reg/v:SF 65 v1 [orig:104 f00 ] [104])
(reg/v:SF 47 fa5 [orig:104 f00 ] [104])) "b.c":23:6 153 {*movsf_hardfloat}
(nil))
during RTL pass: reload
dump file: b.c.282r.reload
b.c:52:1: internal compiler error: in extract_constrain_insn, at recog.c:2195
0x11b9e4d _fatal_insn(char const*, rtx_def const*, char const*, int, char const*)
gcc/gcc/rtl-error.c:108
0x11b9ed1 _fatal_insn_not_found(rtx_def const*, char const*, int, char const*)
gcc/gcc/rtl-error.c:118
0x1130298 extract_constrain_insn(rtx_insn*)
gcc/gcc/recog.c:2195
0xeabdd8 check_rtl
gcc/gcc/lra.c:2167
0xead5c0 lra(_IO_FILE*)
gcc/gcc/lra.c:2604
0xe1a63b do_reload
gcc/gcc/ira.c:5523
0xe1b078 execute
gcc/gcc/ira.c:5709
エラーが発生している箇所はreloadで、エラーの原因となったRTLも出力されています。RTLのsetを見ると、宛先がreg/v:SF 65 v1になっています。浮動小数点の処理のはずなのに、どうしてベクトルレジスタが選択されているのでしょうか?
エラーを出力している箇所
エラーを出力するのは関数check_rtl() です。lra() の最初あたりcheck_rtl(false) と、最後あたりcheck_rtl(true) の2回呼ばれます。エラーが発生しているのは、2回目の呼び出しです。
エラーの出力箇所を追う
// gcc/lra.c
/* Function checks RTL for correctness. If FINAL_P is true, it is
done at the end of LRA and the check is more rigorous. */
static void
check_rtl (bool final_p)
{
basic_block bb;
rtx_insn *insn;
lra_assert (! final_p || reload_completed);
FOR_EACH_BB_FN (bb, cfun)
FOR_BB_INSNS (bb, insn)
if (NONDEBUG_INSN_P (insn)
&& GET_CODE (PATTERN (insn)) != USE
&& GET_CODE (PATTERN (insn)) != CLOBBER
&& GET_CODE (PATTERN (insn)) != ASM_INPUT)
{
if (final_p)
{
extract_constrain_insn (insn); //★★これ
continue;
}
// gcc/recog.c
/* Do uncached extract_insn, constrain_operands and complain about failures.
This should be used when extracting a pre-existing constrained instruction
if the caller wants to know which alternative was chosen. */
void
extract_constrain_insn (rtx_insn *insn)
{
extract_insn (insn); //★★INSN RTLからrecog_dataを作成する
if (!constrain_operands (reload_completed, get_enabled_alternatives (insn))) //★★ここでfalseが返る
fatal_insn_not_found (insn); //★★internal compile errorが出力される
}
おさらいですが、エラーが発生するときのinsnの先頭は下記のようなRTLでした。
エラーが発生するRTL
(insn 562 17 18 2 (set (reg/v:SF 65 v1 [orig:104 f00 ] [104])
(reg/v:SF 47 fa5 [orig:104 f00 ] [104])) "b.c":23:6 145 {*movsf_hardfloat}
(nil))
関数constrain_operands() は何度も呼ばれるので、エラーが起きるRTLが来たときUID 562で止めます。INSN_UID(insn) == 562が来たときに止められるようにコードを少し改変し、ブレークポイントを仕掛けます。
もしくはINSN_UID(insn) はデバッガから参照するときはinsn->u2.insn_uidで見えますから、条件ブレークでも止められると思います。
ブレークするために少し改造
// gcc/lra.c
/* Function checks RTL for correctness. If FINAL_P is true, it is
done at the end of LRA and the check is more rigorous. */
static void
check_rtl (bool final_p)
{
basic_block bb;
rtx_insn *insn;
lra_assert (! final_p || reload_completed);
FOR_EACH_BB_FN (bb, cfun)
FOR_BB_INSNS (bb, insn)
if (NONDEBUG_INSN_P (insn)
&& GET_CODE (PATTERN (insn)) != USE
&& GET_CODE (PATTERN (insn)) != CLOBBER
&& GET_CODE (PATTERN (insn)) != ASM_INPUT)
{
if (INSN_UID(insn) == 562) //★★ブレークポイントを仕掛けるために追加した部分
printf("check point!!\n"); //★★ブレークポイントを仕掛けるために追加した部分
if (final_p)
{
extract_constrain_insn (insn);
continue;
}
関数constrain_operands() を追ってみると、RTLが取るオペランド(今回は2つ取っている)に対応するconstraintsをチェックしています。recog_data.constraintsを見るとconstraintsがわかります。
コードは以前(2020年3月29日の日記参照)見たprocess_alt_operands() の前半部分に似た作りとなっています。同じようなコードを色々なところに書くのはやめてほしいですね……。
エラーが発生するconstraints
(gdb) p recog_data.constraints
$6 = {
0x2d717f9 "=f,f,f,m,m,*f,*r,*r,*r,*m",
0x2d71813 "f,G,m,f,G,*r,*f,*G*r,*m,*r",
...
このconstraintsは降って湧いたものではなくて、下記の *movsf_hardfloatの定義が由来です。
エラーが起きているときのconstraints
// gcc/config/riscv/riscv.md
(define_insn "*movsf_hardfloat"
[(set (match_operand:SF 0 "nonimmediate_operand" "=f,f,f,m,m,*f,*r, *r,*r,*m")
(match_operand:SF 1 "move_operand" " f,G,m,f,G,*r,*f,*G*r,*m,*r"))]
...
浮動小数点の移動の定義ですから当たり前なんですけど、ベクトルレジスタを受け付けるconstraints 'v' は含まれません。なのにベクトルレジスタを渡そうとしているのでconstrain_operands() が怒っているわけです。
と、ここまでエラー出力に至るまでを追いましたが、残念なことにエラーの原因はreloadパスにはありません。エラーが出ている箇所と、エラーの原因が全く関係ない現象はGCCでは珍しくなくて、いつも解析が難しくて困っています。
振り出しに戻ってしまいました。続きは次回。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月7日
GCCを調べる - その15-2 - ベクトルレジスタが選ばれてしまう原因追跡
目次: GCC
前回(2020年7月6日の日記参照)はエラー出力のコードを追いましたが、エラーの原因とは無関係でした。
問題解決のヒントはRTLのダンプファイルにあります。エラーを起こす282r.reloadの1つ前のパス281r.iraのダンプ(オプション --dump-rtl-allで出力できます)を見ると下記のような記述が見つかります。
エラーが起きたときの281r.ira
...
Popping a57(r107,l0) -- assign reg 26
Popping a58(r106,l0) -- assign reg 27
Popping a59(r105,l0) -- assign reg 64 ★64はv0レジスタの番号
Popping a60(r104,l0) -- assign reg 65 ★65はv1レジスタの番号
Popping a61(r165,l0) -- assign reg 5
...
レジスタ番号にベクトルレジスタが出てきます。とても怪しいですね。このメッセージを出しているコードを追います。
281r.iraでPopping ... を出力しているコード
// gcc/ira-color.c
/* Pop the coloring stack and assign hard registers to the popped
allocnos. */
static void
pop_allocnos_from_stack (void)
{
ira_allocno_t allocno;
enum reg_class aclass;
for (;allocno_stack_vec.length () != 0;)
{
allocno = allocno_stack_vec.pop ();
aclass = ALLOCNO_CLASS (allocno);
if (internal_flag_ira_verbose > 3 && ira_dump_file != NULL)
{
fprintf (ira_dump_file, " Popping"); //★★Poppingはここで出力
ira_print_expanded_allocno (allocno);
fprintf (ira_dump_file, " -- ");
}
if (aclass == NO_REGS)
{
ALLOCNO_HARD_REGNO (allocno) = -1;
ALLOCNO_ASSIGNED_P (allocno) = true;
ira_assert (ALLOCNO_UPDATED_HARD_REG_COSTS (allocno) == NULL);
ira_assert
(ALLOCNO_UPDATED_CONFLICT_HARD_REG_COSTS (allocno) == NULL);
if (internal_flag_ira_verbose > 3 && ira_dump_file != NULL)
fprintf (ira_dump_file, "assign memory\n");
}
else if (assign_hard_reg (allocno, false)) //★★レジスタの割当をする
{
if (internal_flag_ira_verbose > 3 && ira_dump_file != NULL)
fprintf (ira_dump_file, "assign reg %d\n",
ALLOCNO_HARD_REGNO (allocno)); //★★assign reg 64はここで出力
}
// gcc/ira-build.c
/* This recursive function outputs allocno A and if it is a cap the
function outputs its members. */
void
ira_print_expanded_allocno (ira_allocno_t a)
{
basic_block bb;
//★★Poppingの後ろのaxx(rxx, lxx) を出力している
fprintf (ira_dump_file, " a%d(r%d", ALLOCNO_NUM (a), ALLOCNO_REGNO (a));
if ((bb = ALLOCNO_LOOP_TREE_NODE (a)->bb) != NULL)
fprintf (ira_dump_file, ",b%d", bb->index);
else
fprintf (ira_dump_file, ",l%d", ALLOCNO_LOOP_TREE_NODE (a)->loop_num);
if (ALLOCNO_CAP_MEMBER (a) != NULL)
{
fprintf (ira_dump_file, ":");
ira_print_expanded_allocno (ALLOCNO_CAP_MEMBER (a));
}
fprintf (ira_dump_file, ")");
}
// gcc/ira-int.h
#define ALLOCNO_NUM(A) ((A)->num)
#define ALLOCNO_REGNO(A) ((A)->regno)
...
#define ALLOCNO_HARD_REGNO(A) ((A)->hard_regno)
...
281r.iraのPoppingの値
いずれもira_allocno_tのメンバを参照する。 (例) Popping a59(r105,l0) -- assign reg 64 - a59 : num - r105 : regno - l0 : loop_num - reg 64: hard_regno
割り当てたレジスタ番号はallocno->hard_regnoに格納されているようです。割り当てる関数はメッセージ出力のすぐ上にあるassign_hard_reg() 関数が行います。
281r.iraでレジスタ割当を決めるコード
// gcc/ira-color.c
static bool
assign_hard_reg (ira_allocno_t a, bool retry_p)
{
HARD_REG_SET conflicting_regs[2], profitable_hard_regs;
int i, j, hard_regno, best_hard_regno, class_size;
...
best_hard_regno = -1;
...
/* We don't care about giving callee saved registers to allocnos no
living through calls because call clobbered registers are
allocated first (it is usual practice to put them first in
REG_ALLOC_ORDER). */
mode = ALLOCNO_MODE (a);
for (i = 0; i < class_size; i++)
{
hard_regno = ira_class_hard_regs[aclass][i];
#ifdef STACK_REGS
if (no_stack_reg_p
&& FIRST_STACK_REG <= hard_regno && hard_regno <= LAST_STACK_REG)
continue;
#endif
if (! check_hard_reg_p (a, hard_regno,
conflicting_regs, profitable_hard_regs)) //★★このチェックを通過すると、割り当てる候補になる
continue;
cost = costs[i];
full_cost = full_costs[i];
if (!HONOR_REG_ALLOC_ORDER)
{
...
}
if (min_cost > cost)
min_cost = cost;
if (min_full_cost > full_cost
|| (!HONOR_REG_ALLOC_ORDER && min_full_cost == full_cost
&& best_hard_regno > hard_regno))
{
min_full_cost = full_cost;
best_hard_regno = hard_regno; //★★どのハードウェアレジスタに割り当てるか決まる
ira_assert (hard_regno >= 0);
}
if (internal_flag_ira_verbose > 5 && ira_dump_file != NULL)
fprintf (ira_dump_file, "(%d=%d,%d) ", hard_regno, cost, full_cost);
}
...
if (! retry_p)
restore_costs_from_copies (a);
ALLOCNO_HARD_REGNO (a) = best_hard_regno; //★★allocno->hard_regnoに格納
ALLOCNO_ASSIGNED_P (a) = true;
if (best_hard_regno >= 0)
update_costs_from_copies (a, true, ! retry_p);
ira_assert (ALLOCNO_CLASS (a) == aclass);
/* We don't need updated costs anymore. */
ira_free_allocno_updated_costs (a);
return best_hard_regno >= 0; //★★best_hard_regnoに何か値が入っていれば成功
}
関数assign_hard_reg() は色んな複雑なことをやっていますが、レジスタ割当の決め手は最後のループです。ループ内では基本的に先頭のレジスタから使います(※)。ループの先頭にcheck_hard_reg_p() というチェックがあって、このチェックをパスしたレジスタが割当の候補になります。
(※)厳密にはどのレジスタから割当を試みるかは、ira_class_hard_regsで決まります。この配列を初期化するのはsetup_class_hard_regs() で、コードを見た感じだと順序を変更することもできるようです。今回、詳細は調べていません。
281r.iraでレジスタ割当候補を判断するコード
// gcc/ira-color.c
/* Return true if HARD_REGNO is ok for assigning to allocno A with
PROFITABLE_REGS and whose objects have CONFLICT_REGS. */
static inline bool
check_hard_reg_p (ira_allocno_t a, int hard_regno,
HARD_REG_SET *conflict_regs, HARD_REG_SET profitable_regs)
{
int j, nwords, nregs;
enum reg_class aclass;
machine_mode mode;
aclass = ALLOCNO_CLASS (a);
mode = ALLOCNO_MODE (a);
if (TEST_HARD_REG_BIT (ira_prohibited_class_mode_regs[aclass][mode],
hard_regno)) //★★このチェックを通過したら割当候補
return false;
/* Checking only profitable hard regs. */
if (! TEST_HARD_REG_BIT (profitable_regs, hard_regno)) //★★このチェックは基本的に通過するはず
return false;
...
// gcc/ira-int.h
#define ALLOCNO_MODE(A) ((A)->mode)
...
#define ALLOCNO_CLASS(A) ((A)->aclass)
...
ベクトルレジスタ(番号64以降)がcheck_hard_reg_p() に渡されるときのaclass, modeの値を見ておきます。今はどうでも良いんですが、次の章で使います。
aclass, modeの値
ブレークに設定する条件はif hard_regno == 64 (gdb) p aclass $4 = ALL_REGS (gdb) p mode $5 = E_SFmode
チェックのキモはira_prohibited_class_mode_regsで、レジスタ番号が示す位置のビットがセットされていると、チェックに引っかかって、割り当て候補から外れます。この配列を初期化している箇所はsetup_prohibited_class_mode_regs() です。
281r.iraでレジスタ割当候補を判断に使うira_prohibited_class_mode_regsを初期化するコード
// gcc/ira.c
static void
setup_prohibited_class_mode_regs (void)
ira_prohibited_class_mode_regs
{
int j, k, hard_regno, cl, last_hard_regno, count;
for (cl = (int) N_REG_CLASSES - 1; cl >= 0; cl--)
{
temp_hard_regset = reg_class_contents[cl] & ~no_unit_alloc_regs;
for (j = 0; j < NUM_MACHINE_MODES; j++)
{
count = 0;
last_hard_regno = -1;
CLEAR_HARD_REG_SET (ira_prohibited_class_mode_regs[cl][j]);
for (k = ira_class_hard_regs_num[cl] - 1; k >= 0; k--)
{
hard_regno = ira_class_hard_regs[cl][k];
if (!targetm.hard_regno_mode_ok (hard_regno, (machine_mode) j)) //★★hard_regno_mode_ok() がtrueであれば割当候補になる
SET_HARD_REG_BIT (ira_prohibited_class_mode_regs[cl][j],
hard_regno);
else if (in_hard_reg_set_p (temp_hard_regset,
(machine_mode) j, hard_regno))
{
last_hard_regno = hard_regno;
count++;
}
}
ira_class_singleton[cl][j] = (count == 1 ? last_hard_regno : -1);
}
}
}
// gcc/config/riscv/riscv.h
enum reg_class
{
NO_REGS, /* no registers in set */
SIBCALL_REGS, /* registers used by indirect sibcalls */
JALR_REGS, /* registers used by indirect calls */
GR_REGS, /* integer registers */
FP_REGS, /* floating-point registers */
VP_REGS, /* vector registers */
FRAME_REGS, /* arg pointer and frame pointer */
ALL_REGS, /* all registers */
LIM_REG_CLASSES /* max value + 1 */
};
#define N_REG_CLASSES (int) LIM_REG_CLASSES
配列の名前prohibitedの通り、この配列のビットがセットされているレジスタは割り当て「禁止」です。最初に配列のビットをクリアし(許可状態)、条件targetm.hard_regno_mode_ok() がtrueだったら変更せず(許可状態のまま)、falseだったらビットをセット(禁止状態)します。
次回は原因を修正します。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月8日
GCCを調べる - その15-3 - ベクトルレジスタを使用するmachine mode
目次: GCC
前回(2020年7月7日の日記参照)はベクトルレジスタが選択されてしまう仕組みが何となくわかりました。
今回やりたかったことを復習しておくと「ベクトルの演算以外でベクトルレジスタを使わないでほしい」でした。つまりira_prohibited_class_mode_regs[cl][j] のうちベクトル以外のmachine modeかつベクトルレジスタに相当するビットを「セット」つまり割り当て禁止状態にすれば良いはずです。
配列の次元のうちclはレジスタのクラス(enum reg_class)で、jはmachine modeです。レジスタのクラスは以前(2020年3月28日の日記参照)ちょっとだけ使いました。幸いなことに、今回はレジスタのクラスは気にしなくて良いです、というかコードのif文の条件hard_regno_mode_ok(hard_regno, (machine_mode) j) を見るとわかるように、そもそもレジスタのクラスが渡されないので、ターゲット側(=RISC-V依存の実装部分)で何もできないです。
重要なのはmachine modeで、ベクトル以外のモード(浮動小数点など)だったらベクトルレジスタを割り当て禁止状態にすれば良いです。
targetm.hard_regno_mode_ok() のRISC-V向け実装
// gcc/config/riscv/riscv.c
/* Implement TARGET_HARD_REGNO_MODE_OK. */
static bool
riscv_hard_regno_mode_ok (unsigned int regno, machine_mode mode)
{
unsigned int nregs = riscv_hard_regno_nregs (regno, mode);
if (GP_REG_P (regno))
{
if (!GP_REG_P (regno + nregs - 1))
return false;
}
else if (FP_REG_P (regno))
{
if (!FP_REG_P (regno + nregs - 1))
return false;
if (GET_MODE_CLASS (mode) != MODE_FLOAT
&& GET_MODE_CLASS (mode) != MODE_COMPLEX_FLOAT)
return false;
/* Only use callee-saved registers if a potential callee is guaranteed
to spill the requisite width. */
if (GET_MODE_UNIT_SIZE (mode) > UNITS_PER_FP_REG
|| (!call_used_or_fixed_reg_p (regno)
&& GET_MODE_UNIT_SIZE (mode) > UNITS_PER_FP_ARG))
return false;
}
else if (VP_REG_P (regno)) //★★前回足した実装
{
return true;
}
else
return false;
...
ここでベクトル系のmachine modeを直接記述(mode == V64SImodeなど)しても間違いではないと思うのですが、単純にモードがたくさんあると鬱陶しいですし、該当するモードがあとで増えたときの修正が大変です。こういうときはmachine modeのクラスが便利です。クラスってなんだったかというと、machmode.defやriscv-modes.defに書いたあれです。
machine modeクラスの定義
// gcc/machmode.def
...
/* Basic integer modes. We go up to TI in generic code (128 bits).
TImode is needed here because the some front ends now genericly
support __int128. If the front ends decide to generically support
larger types, then corresponding modes must be added here. The
name OI is reserved for a 256-bit type (needed by some back ends).
*/
//★★MODE_INTクラスになる
INT_MODE (QI, 1);
INT_MODE (HI, 2);
INT_MODE (SI, 4);
INT_MODE (DI, 8);
INT_MODE (TI, 16);
...
// gcc/config/riscv/riscv-modes.def
//★★MODE_FLOATクラスになる
FLOAT_MODE (TF, 16, ieee_quad_format);
//★★以前、追加した実装
//★★VECTOR_MODEの場合は少し特殊で、MODE_VECTOR + 最初の引数 クラスになる
//★★この例だとMODE_VECTOR_INTになる
VECTOR_MODE (INT, SI, 32);
VECTOR_MODE (INT, SI, 64);
クラスは上記の通り各所の *.defにて定義されますが、正直言ってどこにあるかわかりにくいし、クラスの名前も見えません。machine modeとクラスの対応を確認するだけなら、ビルド時に生成されるinsn-modes.cを見たほうが早いです。
machine modeとクラスの対応、早見方法
// build_gcc/insn-modes.c
const unsigned char mode_class[NUM_MACHINE_MODES] =
{
MODE_RANDOM, /* VOID */
MODE_RANDOM, /* BLK */
MODE_CC, /* CC */
MODE_INT, /* BI */
MODE_INT, /* QI */
MODE_INT, /* HI */
MODE_INT, /* SI */
MODE_INT, /* DI */
MODE_INT, /* TI */
MODE_FRACT, /* QQ */
MODE_FRACT, /* HQ */
MODE_FRACT, /* SQ */
MODE_FRACT, /* DQ */
MODE_FRACT, /* TQ */
MODE_UFRACT, /* UQQ */
MODE_UFRACT, /* UHQ */
MODE_UFRACT, /* USQ */
MODE_UFRACT, /* UDQ */
MODE_UFRACT, /* UTQ */
MODE_ACCUM, /* HA */
MODE_ACCUM, /* SA */
MODE_ACCUM, /* DA */
MODE_ACCUM, /* TA */
MODE_UACCUM, /* UHA */
MODE_UACCUM, /* USA */
MODE_UACCUM, /* UDA */
MODE_UACCUM, /* UTA */
MODE_FLOAT, /* SF */
MODE_FLOAT, /* DF */
MODE_FLOAT, /* TF */
...
MODE_COMPLEX_FLOAT, /* SC */
MODE_COMPLEX_FLOAT, /* DC */
MODE_COMPLEX_FLOAT, /* TC */
MODE_VECTOR_INT, /* V32SI */
MODE_VECTOR_INT, /* V64SI */
};
ベクトル系のmachine modeを引っ掛けるにはMODE_VECTOR_INTを使えば良さそうです。今の実装では使っていませんがRISC-Vのベクトルは浮動小数点のベクトル(MODE_VECTOR_FLOAT)も扱えるはずなので、これも条件に追加しておきましょう。
targetm.hard_regno_mode_ok() のRISC-V向け実装、修正版
// gcc/config/riscv/riscv.c
/* Implement TARGET_HARD_REGNO_MODE_OK. */
static bool
riscv_hard_regno_mode_ok (unsigned int regno, machine_mode mode)
{
unsigned int nregs = riscv_hard_regno_nregs (regno, mode);
if (GP_REG_P (regno))
{
if (!GP_REG_P (regno + nregs - 1))
return false;
}
else if (FP_REG_P (regno))
{
if (!FP_REG_P (regno + nregs - 1))
return false;
if (GET_MODE_CLASS (mode) != MODE_FLOAT
&& GET_MODE_CLASS (mode) != MODE_COMPLEX_FLOAT)
return false;
/* Only use callee-saved registers if a potential callee is guaranteed
to spill the requisite width. */
if (GET_MODE_UNIT_SIZE (mode) > UNITS_PER_FP_REG
|| (!call_used_or_fixed_reg_p (regno)
&& GET_MODE_UNIT_SIZE (mode) > UNITS_PER_FP_ARG))
return false;
}
else if (VP_REG_P (regno)) //★★前回足した実装
{
if (GET_MODE_CLASS (mode) != MODE_VECTOR_INT
&& GET_MODE_CLASS (mode) != MODE_VECTOR_FLOAT) //★★今回足した実装
return false;
return true;
}
else
return false;
...
修正後のコンパイラは浮動小数点数を60個使うコードを正常にコンパイルできます。たったこの3行を説明するだけで、えらい時間を費やしました。GCCは魔界ですね。
お気づきの方もいるかと思いますが、実は1つ上のelse if節にほぼ全く同じ判定文が既にあります。何も考えずに上からパクってMODEの名前を書き換えれば、今回の問題は直るんですけど、それだとどうして直るのか全くわからないんですよ……。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月9日
ノートPCの発熱を抑える方法 - その2
目次: Windows
前回(2020年6月29日の日記参照)、ノートPCの発熱を抑えるためにCPUのクロック上限を抑える設定をしました。
前回はTurboBoostだけ無効化する方法がわかりませんでしたが、ググっていたら割と簡単にTurboBoostを無効化できることがわかりました。
レジストリエディタで、
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Power\PowerSettings\54533251-82be-4824-96c1-47b60b740d00\be337238-0d82-4146-a960-4f3749d470c7
のAttributesというDWORD値を1から0 or 2に変更します(※)。
すると下記の「プロセッサ パフォーマンスの向上モード」オプションが出現しますので、無効を選択します。
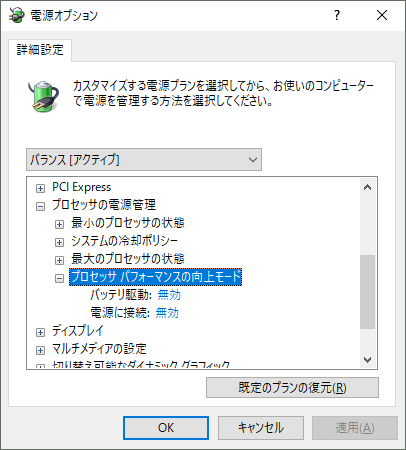
TurboBoostを無効化すると、最大のプロセッサの状態を100% にしても、ベース周波数の1.6GHzまでしか周波数が上がらなくなります。これは良い感じだ。
- 〜54%: 0.90GHz
- 〜60%: 0.99GHz
- 〜65%: 1.10GHz
- 〜71%: 1.19GHz
- 〜76%: 1.30GHz
- 〜82%: 1.39GHz
- 〜87%: 1.49GHz
- 〜100%: 3.36GHz → 1.59GHz
(※)私はSurface ProでCPUクロックが最大に張り付くという問題(フォーラムへのリンク)の解決策に載っていたものを見つけたのですが、どうも昔のWindows 8で消えた設定らしい(ASCII.jp : Windows 8.1で消えた詳細な電源管理項目を表示する!より)です。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月10日
MAD Tower Tycoon楽しい
目次: ゲーム
最近Steamで買った、MAD Tower Tycoon(開発: Eggcode)で遊んでいます。

ビル建築&経営シミュレーションゲームです。プレイヤーはビルを拡張していって、テナントや住居を作ります。テナントには住人やゲストが押し寄せてきますので、住人のストレスを溜めないように、メンテナンス施設を足したり、階段、エスカレーター、エレベーターでうまく捌き、儲けを出して、ビルをさらに拡張させるというゲームです。
The Towerの後継者?
ビル建築&経営シミュレーションの名作はThe Tower(開発: OPeNBooK)だと思います。The Towerは続編が出なくなって久しく寂しかったですが、MAD Tower TycoonはかなりThe Towerに近い作りです。
後追いだけあって基本的にThe Towerより良くなっていますが、残念な部分もあって、
- 上階に伸ばすときの建設が面倒くさい
- 中盤から金が余りまくる
- オフィス、住宅からの変な苦情(人通りが多い)
- 横移動のストレスがない、もしくは非常に低い
- エレベーターは速いが、自由度が低い
難易度は最近の風潮で優しめだとしても、最後のエレベーターの劣化は残念です。
エレベーターの変な仕様
エレベーターはThe Towerのキモで、説明書でも詳しく説明していました。MAD Tower Tycoonのエレベーターの場合は、
- エレベータのカゴ数が最大3で少ない
- 通過階の設定ができない(降車専用ならある)
特に後者の制限が厳しくて、ゾーン方式(※)エレベーターが実質建設不可能で、高層ビルを作るには厳しい仕様となっています。
(※)エレベーターを複数基用意して、1つ目は1〜5階のみ、2つ目は5〜10階のみなど、一部の階しか止まらないエレベーターを作る方式のことです。現実でも高層ビルでよく見かけます。
むりやりゾーン方式エレベーターを作るとどうなる?
バグなのか仕様なのかわからないですが、MAD Tower Tycoonではバルコニーでフロアをぶち抜いて、スカイブリッジを作ると、どことも繋がらない孤立したフロアを作れます。
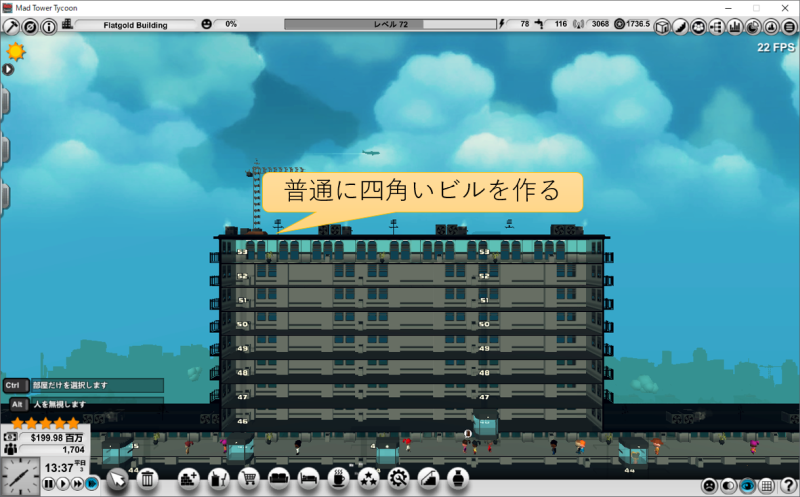
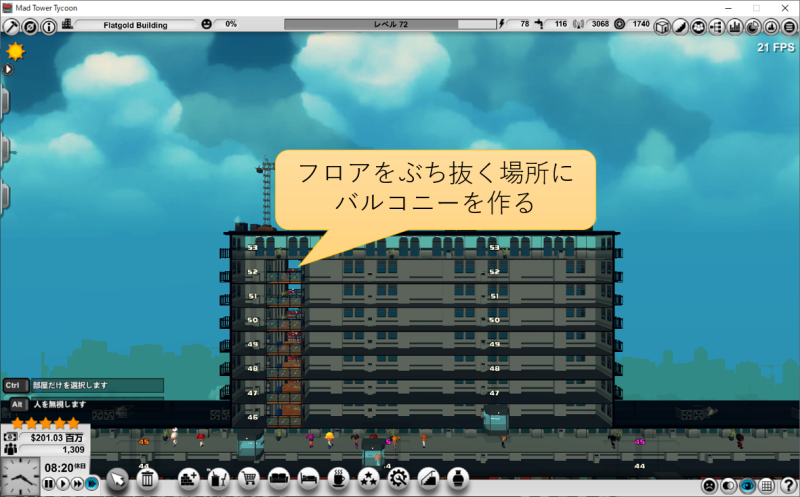
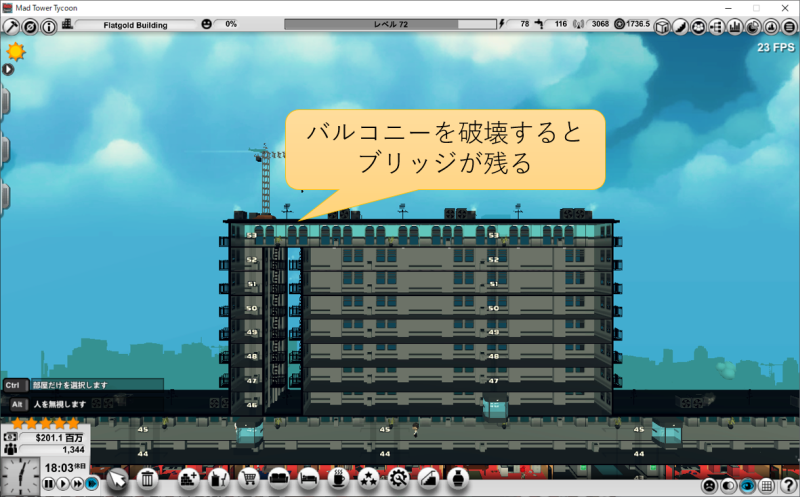
孤立したフロアにエレベーターだけを設置することで、実質的に乗車降車禁止階にできます。
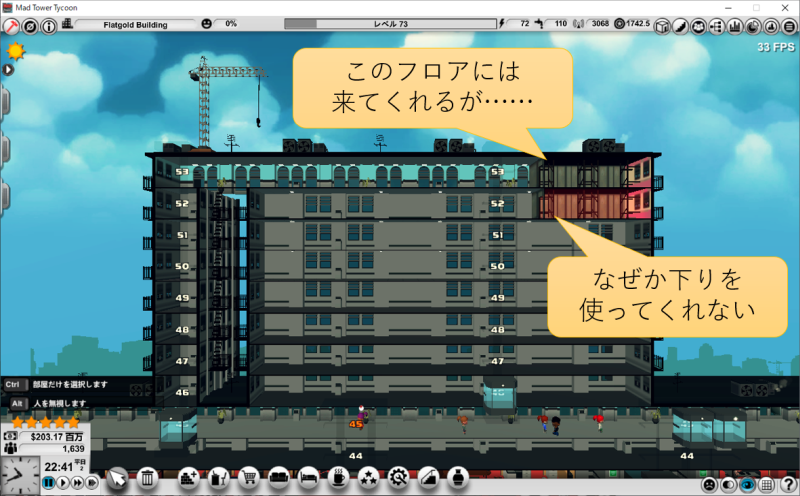
ところがこの乗車降車禁止エレベータを作っても、なぜか住人は一切利用してくれません。訳が分かりません。どうしたら良いんでしょうか??
オープンブックの紆余曲折
The Tower開発元のOPeNBooKは合併と名前変更を繰り返しています。合併相手は9003, incで、AQUAZONEという熱帯魚育成&水槽シミュレーションで名を馳せたベンダーです。
1993 2000
OPeNBooK ---, 1996 ,--> オープンブック(The Towerの版権を持つ)
+--> オープンブック9003 ---+--> シノミクス
9003, inc ---'
1990
Wikipediaを見るとこんな経歴でした。お互い、元の鞘に収まったという感じがします。合併したけどやることがなかったんですかね?
コメント一覧
- わしださん(2020/08/10 22:40)
オープンブック9003時代に鳥(Pinna?)飼ってました・・・熱帯魚はともかくなぜ鳥飼育ゲーを買ったのか、今となっては心境が分かりません・・・。 - すずきさん(2020/08/11 18:59)
鳥のゲームは知りませんでした。色々やってるなあ。オープンブック……。
あの頃は、PCの解像度がどんどん上がって綺麗になっていて、飼育ゲームとかアクアリウム的な、眺めるタイプの奴が流行ってましたよね。
この記事にコメントする
2020年7月11日
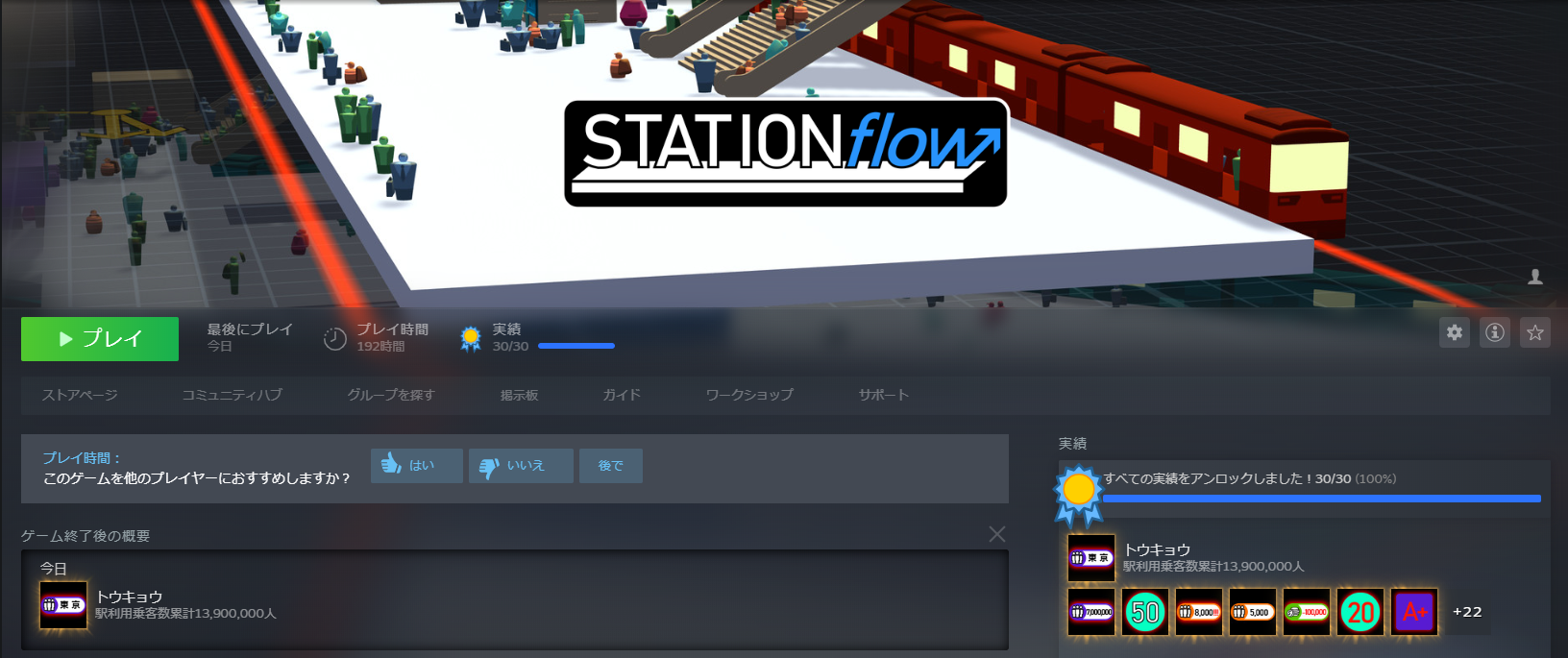
STATIONflow実績コンプリート
目次: ゲーム
STATIONflowの実績をコンプリートしました。「ラッキーセブン」と「東京」は自動化マクロを組まないと取れませんでした。
本来、このゲームにハマって色々なマップをずっと遊んでいたらいつのまにか取れていた、というタイプの実績ですが、申し訳ないことに、私はそこまでの情熱がなかったです。
ゲームやったらわかりますけど、この2つの実績だけ条件設定が異常すぎます。
- 1日の利用者数は最大17,000人程度(全出入口&乗り場が最大レベルの駅)
- 1390万人達成には単純計算でゲーム内時間800日程度
- STATIONflowの1日は最速でも15分、普通に遊ぶと30分〜1時間くらい
- 最速でも200時間は必要
実績の条件(総利用者数700万人、1,390万人)がいかに異常かがわかると思います。
自動化
自動化の方法は簡単で、PowerShellでEnterキーを3秒に1回送るマクロを組んで、会社行っている間や夜間に放置するだけです。2週間くらいで取れました。
STATIONflowは放置しても悪いイベントが起きない(=駅が壊れない)優しい仕様になっているため、自動化+放置が可能でしたが、他のシミュレーションゲームだと偶発的に悪いイベントが起きるため、この方法は使えません。
まあ、明らかに製作者の想定した取り方ではないし、こんな方法で実績取っても嬉しくないし、無理に実績取るのは今後はやめておきます。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月12日
MAD Tower Tycoonコンプリート
目次: ゲーム
MAD Tower Tycoonでゾーン方式のエレベータの作り方を悩んで色々やっていたら、いつのまにかレベル100、実績コンプリートしていました。ゲーム内時間は表示されないので詳しくはわかりませんが、おそらく700日くらい?
The Towerと比べて色々思うところはありますが、総合的にみれば面白いと思います。
序盤だけ金欠になりやすいですが、難易度はかなり低めですし、ビル建築シミュレーション初めての方にオススメしたいゲームです。
高層ビルを作りたい
MAD Tower Tycoonは住人を追尾する機能があり、ビルの住人が困っていないか把握するのに便利です。基本的には目的地に行って、家に帰る(住人の場合)、もしくはビルから出る(ゲストの場合)だけですけど、大きなビルを作ると変な行動が目立ちます。
- ビルの端から端まで歩いて、わざわざ遠いエレベーターで乗り換え
- 近所のレストランを無視して、わざわざ遠いレストランに行く
前回(2020年7月10日の日記参照)も書きましたが、MAD Tower Tycoonはゾーン方式のエレベーターを作る方法がわかりません。今はメンテナンス施設の射程(上下6Fに効果がある)の関係で、7階+8階(※)おきに乗り換え階を作っています。
どうもこの方式だと40階くらいで限界っぽいです。乗り換えに時間が掛かりすぎて、目的地に行くだけで半日費やしている気の毒な住民がいます。彼らはなぜか不満は言いませんが、見ていると不憫です……。
救いとしてはMAD Tower Tycoonはビルの横幅がめちゃくちゃ広く取れるので、45階もあれば、レベル100、五つ星ビルが余裕で作れることです。だけど、やっぱりThe Towerにあやかるなら、100階建て目指したいですよね?
(※)効率重視ならば7F, 14F乗り換えが最適ですが、スカイロビーを作成できるのは15Fからなので、あえて14Fを空きフロアにして、15F乗り換えにしています。
どうしてもThe Towerと比較してしまう
MAD Tower Tycoonは、The Towerとかなり似ているがゆえに、つい比較してしまいます。
良いところ
- エレベータ乗り換えがロビー階以外でも可能
- 何度でも乗り継げる(1F → 7F → 15F → 23Fのような乗り継ぎが可能)
- かなり上の階でも階段で行ける(The Towerは確か4Fくらいしか上らない)
悪いところ
- エレベータの通過階設定ができない(今、一番困っている制限)※通過階設定はできるが設定が効かないバグ、とのこと(2023/10/20追記)
- 一度上に行ってから、下に行く乗り換えが不可能(1F → 15F → 7Fみたいな乗り換えはしないようだ)
ゾーン方式のエレベーターが作れたら、高層ビルに効率的に人を運べるようになって、もっと面白くなるはずなのに。もったいないよ〜。
コメント一覧
- わしださん(2020/08/10 22:36)
The Tower懐かしいですね。
話題とずれる荒しみたいなコメントになりますが、旧姓でエゴサーチして最も古い自分の名前が出るのが、Geocitiesの他人のサイトに投稿したThe towerのビルでした。小6くらいだったのですが、本名とビル名に「第百ビル」とか付けてて。
その10年以上後、新卒で会社入って最初の移動先の課長に「第百ビルの人?」って聞かれてびびりました。(会社入って一年くらいは旧姓だったので)
いまはGeocitiesも閉鎖になったので出てきませんが、いい思い出ではあります。
ということでとにもかくにも100階建てにしてチャペル建てたくなる気持ちを思い出しました。 - すずきさん(2020/08/11 18:59)
小学生でサイトに投稿はスゴイです。そして会社バレしてるのも奇遇というかなんというか。
The Tower で遊んでいたのは、たしか中学生時代だったと思いますが、当時インターネットとかパソコン通信はさっぱりわからず、ビルを投稿しようという考えが全くなかったです。
Mad Tower Tycoon も 100階にチャペルを建てられますが、The Tower ほどの重要なポジションではない(集客施設の一つに過ぎない)です。星 3〜4辺りからゲーム性が極端に下がってダレてしまうのも、ちょっと残念なポイントです。 - 通り縋りさん(2023/10/18 19:08)
上の記事2023年9月編集という事ですが間違ってます。
2023年10月現在、正しくは「エレベーターの通過階設定自体は出来るが正確に反映されない」です。
通過階設定自体は出来る事を確認してますが、特に高速エレベーターに於いて設定が正常に反映されず「通過階にも待ちが発生し停車してしまう」というバグとなっています。 - すずきさん(2023/10/19 11:17)
ご指摘ありがとうございます。9月の編集は先頭にリンクを加えただけで、内容は2020年7月に書いたときのままです。わかりにくくてすみません。
それは良いとして、ご指摘の内容に合わせて修正しておきます。
この記事にコメントする
2020年7月14日
OpenCLとICD
目次: OpenCL
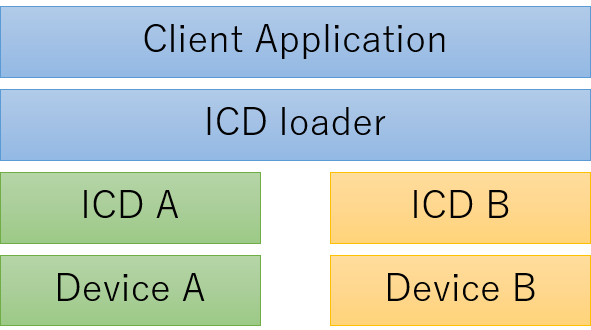
OpenCLは複数のベンダーのデバイスを同時に扱うことができます。ICD(Installable Client Driver)というそうです。ICDはGPUなどのデバイスを制御し、アプリケーションとICDの間にICDローダーが存在します。
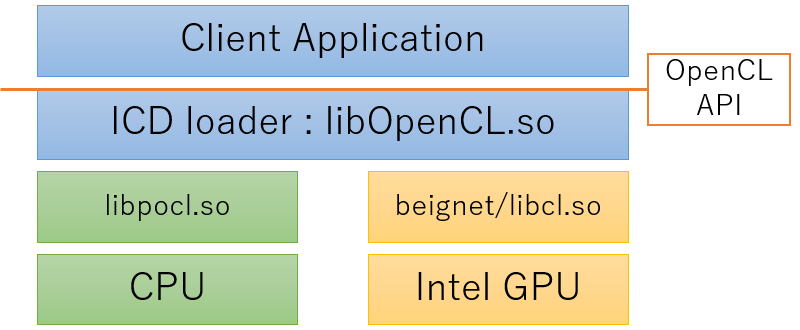
Debian TestingではICDローダーとしてocl-icd-2.2.12が使われています。
Debian TestingのICD loader
$ apt-cache search ocl-icd-libopencl1 ocl-icd-libopencl1 - Generic OpenCL ICD Loader
ローダーのソースコードはGitHub(リンク)にあります。
先程、図示したもの以外にもICDはいくつか実装があります。現時点のDebian Testingでは下記が提供されていました。
- pocl-opencl-icd: 主にCPU向け
- beignet-opencl-icd: 比較的古いIntel GPU向け
- intel-opencl-icd: 比較的新しいIntel GPU向け、Testingにしか存在しない
- mesa-opencl-icd: AMD GPU向け
- nvidia-opencl-icd: nVidia GPU向け、ソースコードは公開されていない
IntelはICDのソースコードを完全にオープンにしています。NVIDIAは公開していません。AMDもないのかな?
ICDのロード手順
動作を追ってみたいと思います。アプリケーションにはclinfoを使います。ocl-icdは環境変数OCL_ICD_DEBUG=15に設定すると、動作時に詳細なログを出力します。デバッガで追うのと併用するとわかりやすいです。
- clinfo: clGetPlatformIDs() を呼ぶ
- ocl-icd: _initClIcd() -> _initClIcd_real() -> __initClIcd()
- ocl-icd: _find_num_icds(): /etc/OpenCL/vendorsの *.icdファイルを見る(*.soへのパスが書いてある)
- ocl-icd: _load_icd(): *.soをdlopen()
- ocl-icd: _find_and_check_platforms(): 後述
ローダーが走査するディレクトリは /etc/OpenCL/vendorsがハードコードされていますが、環境変数OPENCL_VENDOR_PATHで変更できます。
ICDのロードの中心となる処理は _find_and_check_platforms() です。
- dlsym() でclGetExtensionFunctionAddress() のアドレスを得る
- clGetExtensionFunctionAddress() でclIcdGetPlatformIDsKHR() のアドレスを得る
- clGetExtensionFunctionAddress() でclGetPlatformInfo() のアドレスを得る
- clIcdGetPlatformIDsKHR() でプラットフォーム数とプラットフォームの情報を得る
プラットフォームは説明が難しいですが、OpenCL APIの実体+任意のドライバ固有のデータとでも言いましょうか。変数の型はcl_platform_id * 型です。cl_platform_idは少なくとも先頭のメンバはstruct _cl_icd_dispatch *dispatchでなければなりません。dispatchの後ろには他の情報が入っていても問題ないようです。
cl_platform_idとdispatch
// ocl-icd/ocl_icd_loader.c
static inline void _find_and_check_platforms(cl_uint num_icds) {
cl_uint i;
...
cl_platform_id *platforms = (cl_platform_id *) malloc( sizeof(cl_platform_id) * num_platforms);
error = (*plt_fn_ptr)(num_platforms, platforms, NULL);
...
for(j=0; j<num_platforms; j++) {
debug(D_LOG, "Checking platform %i", j);
struct platform_icd *p=&_picds[_num_picds];
char *param_value=NULL;
p->extension_suffix=NULL;
p->vicd=&_icds[i];
p->pid=platforms[j]; //★★pid = platform IDのことらしい
/* If clGetPlatformInfo is not exported and we are here, it
* means that OCL_ICD_ASSUME_ICD_EXTENSION. Si we try to take it
* from the dispatch * table. If that fails too, we have to
* bail.
*/
if (plt_info_ptr == NULL) {
plt_info_ptr = p->pid->dispatch->clGetPlatformInfo; //★★dispatchメンバが存在することを前提としている
// ocl-icd/khronos-headers/CL/cl.h
typedef struct _cl_platform_id * cl_platform_id;
// ocl-icd/(build-dir)/ocl_icd_loader_gen.h
struct _cl_platform_id { struct _cl_icd_dispatch *dispatch; }; //★★dispatch以外は特に規定がなさそう
// ocl-icd/(build-dir)/ocl_icd.h
struct _cl_icd_dispatch {
#ifdef CL_VERSION_1_0
CL_API_ENTRY cl_int (CL_API_CALL*clGetPlatformIDs)(
cl_uint /* num_entries */,
cl_platform_id * /* platforms */,
cl_uint * /* num_platforms */
) CL_API_SUFFIX__VERSION_1_0;
#else
CL_API_ENTRY cl_int (CL_API_CALL* clUnknown0)(void);
#endif
#ifdef CL_VERSION_1_0
CL_API_ENTRY cl_int (CL_API_CALL*
clGetPlatformInfo)(
cl_platform_id /* platform */,
cl_platform_info /* param_name */,
size_t /* param_value_size */,
void * /* param_value */,
size_t * /* param_value_size_ret */
) CL_API_SUFFIX__VERSION_1_0;
#else
CL_API_ENTRY cl_int (CL_API_CALL* clUnknown1)(void);
#endif
...
//★★こんな調子で関数ポインタの定義が延々と続く
先頭のdispatchはたくさんの関数ポインタが並んだ巨大な構造体です。アプリケーションから見るとOpenCLのAPIはocl-icdが提供しているように見えますが、ocl-icdのAPI実装はdispatchの関数ポインタを呼ぶラッパー関数であり、関数ポインタと、OpenCL API実装の本体を提供するのは各ICDの役割です。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月15日
GCCを調べる - その16 - 自動ベクトル化を有効にする
目次: GCC
GCCには自動ベクトル化(tree-vectorize)機能があります。ループ処理を自動的にSIMD命令に置き換えるために使われているようです。現状のGCCが可変長のベクトル長に対応しているかどうかはわかりません。未対応ならば可変長のベクトル長に対応する実装が必要になりますが、非常に難しそうです。
可変長のベクトルの扱いはひとまず横に置くとして、RISC-Vのベクトルを「とても長い固定長のSIMD」とみなして自動ベクトル化を動かします。
自動ベクトル化を有効にするコード
// gcc/config/riscv/riscv.c
/* Implement TARGET_VECTORIZE_AUTOVECTORIZE_VECTOR_MODES. */
static unsigned int
riscv_autovectorize_vector_modes (vector_modes *modes, bool)
{
if (TARGET_VECTOR)
{
modes->safe_push (V64SImode);
modes->safe_push (V32SImode);
}
return 0;
}
...
#undef TARGET_VECTORIZE_AUTOVECTORIZE_VECTOR_MODES
#define TARGET_VECTORIZE_AUTOVECTORIZE_VECTOR_MODES riscv_autovectorize_vector_modes
自動ベクトル化を有効にする方法は簡単で、これだけです。
テスト用のint配列をコピーする関数
void *cpy(void *dst, const void *src, int n)
{
int *d = dst;
const int *s = src;
int i;
for (i = 0; i < n / sizeof(*d); i++) {
d[i] = s[i];
}
return dst;
}
この関数がベクトル化あり、なしでどのように変わるか見ます。
自動ベクトル化の結果
//★★自動ベクトル化、あり
d[i] = s[i];
100b8: 1202e007 vlw.v v0,(t0)
100bc: 10038393 addi t2,t2,256
100c0: f0038793 addi a5,t2,-256
100c4: 10028293 addi t0,t0,256
100c8: 0207e027 vsw.v v0,(a5)
for (i = 0; i < n / sizeof(*d); i++) {
100cc: fee296e3 bne t0,a4,100b8 <cpy+0x44>
100d0: 00661293 slli t0,a2,0x6
100d4: 02568963 beq a3,t0,10106 <cpy+0x92>
100d8: 959a add a1,a1,t1
100da: 932a add t1,t1,a0
d[i] = s[i];
100dc: 0005a383 lw t2,0(a1)
//★★自動ベクトル化、なし
d[i] = s[i];
10080: 0005a303 lw t1,0(a1)
for (i = 0; i < n / sizeof(*d); i++) {
10084: 0591 addi a1,a1,4
10086: 0291 addi t0,t0,4
d[i] = s[i];
10088: fe62ae23 sw t1,-4(t0)
for (i = 0; i < n / sizeof(*d); i++) {
1008c: fe759ae3 bne a1,t2,10080 <cpy+0xc>
}
return dst;
}
10090: 8082 ret
ソースコードではベクトル型を使っていませんが、自動ベクトル化により256バイト(=64要素)ずつ処理され、vlw.v, vsw.v命令が使われるようになったことがわかります。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月18日
北極送り
GitHubが北極にコードを保存する取り組み(私のソースコードが北極送りに? "GitHub" アカウントに謎のラベルが付与されたとの報告が多数 - やじうまの杜 - 窓の杜)をしているそうです。面白いこと考えますよね。

GitHub Arctic Code Vault Contributor
気づいたら自分のGitHubアカウントにもArctic Code Vault Contributorと出ていました。有名なOSSには関わってないし縁がないと思っていましたが、どうやらLinuxにコントリビュートしていたので出てきたっぽいです。いわれてみるとLinuxもGitHubにミラーされてました。
未来人は現代人を理解できるだろうか?
現代人をもってしても1000年前の文字の解読(例: ヒエログリフ、前3200年〜4世紀、19世紀頃に解読された)はとても苦労したこと、解読されていない古代文字がまだまだあることを考えれば、現代文字や文明を遺しても未来人が理解不能で終わってしまう可能性もあるわけです。
少なくとも未来文明は現代文明より遥か上の水準に発展していないと、仮に現代文字や文明を発見できても、真に理解するのは難しいでしょう。
こんなことを考えると、実はCode Vaultの取り組みは「地球の未来は今より進んでいるはず」という信頼や願望が前提になっていることが見て取れます。人類か、それ以外の生命体か、誰の手に渡るかわかりませんが、SF的なロマンがありますよね。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月19日
GCCを調べる - その17 - ベクトル四則演算、論理演算の定義
目次: GCC
ベクトルのロード、ストアだけでは自動ベクトル化できるコードが少なすぎるので、他の演算も定義したいと思います。
ベクトル演算の加算、減算、乗算、除算、論理演算(and, or, xor)の定義
;; gcc/config/riscv/riscv.md
(define_attr "vecmode" "unknown,V32SI,V64SI"
(const_string "unknown"))
...
;; Iterator for hardware supported vector modes.
(define_mode_iterator ANYV [(V32SI "TARGET_VECTOR")
(V64SI "TARGET_VECTOR")])
...
;;★★加算
(define_insn "add<mode>3"
[(set (match_operand:ANYV 0 "register_operand" "=v")
(plus:ANYV (match_operand:ANYV 1 "register_operand" " v")
(match_operand:ANYV 2 "arith_operand" " v")))]
"TARGET_VECTOR"
"vadd.vvt%0,%1,%2"
[(set_attr "type" "arith")
(set_attr "vecmode" "<MODE>")])
;;★★減算
(define_insn "sub<mode>3"
[(set (match_operand:ANYV 0 "register_operand" "=v")
(minus:ANYV (match_operand:ANYV 1 "register_operand" " v")
(match_operand:ANYV 2 "arith_operand" " v")))]
"TARGET_VECTOR"
"vsub.vvt%0,%1,%2"
[(set_attr "type" "arith")
(set_attr "vecmode" "<MODE>")])
;;★★乗算
(define_insn "mul<mode>3"
[(set (match_operand:ANYV 0 "register_operand" "=v")
(mult:ANYV (match_operand:ANYV 1 "register_operand" " v")
(match_operand:ANYV 2 "arith_operand" " v")))]
"TARGET_VECTOR"
"vmul.vvt%0,%1,%2"
[(set_attr "type" "arith")
(set_attr "vecmode" "<MODE>")])
;;★★除算
;; This code iterator allows unsigned and signed division to be generated
;; from the same template.
(define_code_iterator any_div [div udiv mod umod])
(define_insn "<optab><mode>3"
[(set (match_operand:ANYV 0 "register_operand" "=v")
(any_div:ANYV (match_operand:ANYV 1 "register_operand" " v")
(match_operand:ANYV 2 "arith_operand" " v")))]
"TARGET_VECTOR"
"v<insn>.vvt%0,%1,%2"
[(set_attr "type" "arith")
(set_attr "vecmode" "<MODE>")])
;;★★論理演算
;; This code iterator allows the three bitwise instructions to be generated
;; from the same template.
(define_code_iterator any_bitwise [and ior xor])
...
(define_insn "<optab><mode>3"
[(set (match_operand:ANYV 0 "register_operand" "=v")
(any_bitwise:ANYV (match_operand:ANYV 1 "register_operand" "%v")
(match_operand:ANYV 2 "arith_operand" " v")))]
"TAREGET_VECTOR"
"v<insn>.vvt%0,%1,%2"
[(set_attr "type" "logical")
(set_attr "vecmode" "<MODE>")])
四則演算、論理演算を使う下記のプログラムを書きます。自動ベクトル化で四則演算のループをベクトル化しても良いですが、ベクトル拡張記法(Vector Extensions (Using the GNU Compiler Collection (GCC)))を使ったほうが狙った演算が出しやすく、テストするときに楽です。
ベクトル四則演算、論理演算のサンプルプログラム
typedef int __v64si __attribute__((__vector_size__(256)));
void test()
{
__v64si v10, v11, v12, v13;0;
__asm__ volatile ("vlw.v %0, %1\n" : "=&v"(v10) : "A"(b[10]));
__asm__ volatile ("vlw.v %0, %1\n" : "=&v"(v11) : "A"(b[20]));
__asm__ volatile ("vlw.v %0, %1\n" : "=&v"(v12) : "A"(b[30]));
__asm__ volatile ("vlw.v %0, %1\n" : "=&v"(v13) : "A"(b[40]));
v10 = v11 + v12;
v11 &= v12 - v13;
v12 |= v13 * v10;
v13 ^= v10 / v11;
__asm__ volatile ("vsw.v %1, %0\n" : "=A"(b[40]) : "v"(v10));
__asm__ volatile ("vsw.v %1, %0\n" : "=A"(b[50]) : "v"(v11));
__asm__ volatile ("vsw.v %1, %0\n" : "=A"(b[60]) : "v"(v12));
__asm__ volatile ("vsw.v %1, %0\n" : "=A"(b[70]) : "v"(v13));
}
ビルド方法は何でも良いですが、最適化レベルをOgにするとアセンブラが見やすいと思います。
ベクトル四則演算、論理演算のサンプルプログラム(逆アセンブル)
$ riscv32-unknown-elf-gcc b.c -nostdlib -g -Og -march=rv32gcv -mabi=ilp32f
$ riscv32-unknown-elf-objdump -dS a.out
...
__asm__ volatile ("vlw.v %0, %1\n" : "=&v"(v13) : "A"(b[40]));
10092: 0a028793 addi a5,t0,160
10096: 1207e207 vlw.v v4,(a5)
v10 = v11 + v12;
1009a: 022081d7 vadd.vv v3,v2,v1
v11 &= v12 - v13;
1009e: 0a120057 vsub.vv v0,v1,v4
100a2: 26010057 vand.vv v0,v0,v2
v12 |= v13 * v10;
100a6: 9641a157 vmul.vv v2,v4,v3
100aa: 2a208157 vor.vv v2,v2,v1
v13 ^= v10 / v11;
100ae: 863020d7 vdiv.vv v1,v3,v0
100b2: 2e1200d7 vxor.vv v1,v1,v4
__asm__ volatile ("vsw.v %1, %0\n" : "=A"(b[40]) : "v"(v10));
100b6: 0207e1a7 vsw.v v3,(a5)
...
うまくいっているようです。良かった良かった。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月20日
GCCを調べる - その18 - ベクトルNot演算の定義
目次: GCC
前回(2020年7月19日の日記参照)は四則演算と論理演算(and, or, xor)を定義しました。今回はNot演算を定義します。他の論理演算と異なり、Not演算は2オペランドしか取りませんから、define_insnを別に書く必要があります。
ベクトルNot演算の定義
;; gcc/config/riscv/riscv.md
(define_insn "one_cmpl<mode>2"
[(set (match_operand:ANYV 0 "register_operand" "=v")
(not:ANYV (match_operand:ANYV 1 "register_operand" "%v")))]
"TARGET_VECTOR"
"vnot.vt%0,%1"
[(set_attr "type" "logical")
(set_attr "vecmode" "<MODE>")])
前回同様に、ベクトル拡張記法(Vector Extensions (Using the GNU Compiler Collection (GCC)))を使ってビット毎Notを使うプログラムを書きます。
ベクトルNot演算のサンプルプログラム
typedef int __v64si __attribute__((__vector_size__(256)));
void test()
{
__v64si v10, v11;
static int b[1024 * 1024] = {0};
__asm__ volatile ("vlw.v %0, %1\n" : "=&v"(v10) : "A"(b[10]));
__asm__ volatile ("vlw.v %0, %1\n" : "=&v"(v11) : "A"(b[20]));
v10 = ~v11;
__asm__ volatile ("vsw.v %1, %0\n" : "=A"(b[40]) : "v"(v10));
}
コンパイルするとエラーが発生します。何かお気に召さないようです。
コンパイルエラー
$ riscv32-unknown-elf-gcc b.c -nostdlib -Og -march=rv32gcv -mabi=ilp32f
during RTL pass: reload
dump file: b.c.282r.reload
b.c: In function 'test':
b.c:14:1: internal compiler error: in setup_operand_alternative, at lra.c:814
14 | }
| ^
0xea5c36 setup_operand_alternative
gcc/gcc/lra.c:814
0xea70c2 lra_set_insn_recog_data(rtx_insn*)
gcc/gcc/lra.c:1073
0xea30f9 lra_get_insn_recog_data
gcc/gcc/lra-int.h:488
0xeab0b9 remove_scratches_1
gcc/gcc/lra.c:2058
0xeab4c4 remove_scratches
gcc/gcc/lra.c:2094
0xeac629 lra(_IO_FILE*)
gcc/gcc/lra.c:2396
0xe1a41f do_reload
gcc/gcc/ira.c:5523
0xe1ae5c execute
gcc/gcc/ira.c:5709
コードを見ると最後のオペランドに % を付けるべきではないそうです。確かにdefine_insnを見ると % が要らないのに付いています。
エラーを出している箇所
// gcc/lra.c
/* Setup info about operands in alternatives of LRA DATA of insn. */
static void
setup_operand_alternative (lra_insn_recog_data_t data,
const operand_alternative *op_alt)
{
int i, j, nop, nalt;
int icode = data->icode;
struct lra_static_insn_data *static_data = data->insn_static_data;
static_data->commutative = -1;
nop = static_data->n_operands;
nalt = static_data->n_alternatives;
static_data->operand_alternative = op_alt;
for (i = 0; i < nop; i++)
{
static_data->operand[i].early_clobber_alts = 0;
static_data->operand[i].is_address = false;
if (static_data->operand[i].constraint[0] == '%') //★★% が付いていればcommutative
{
/* We currently only support one commutative pair of operands. */
if (static_data->commutative < 0)
static_data->commutative = i;
else
lra_assert (icode < 0); /* Asm */
/* The last operand should not be marked commutative. */
lra_assert (i != nop - 1); //★★このアサートに引っかかる
}
}
...
素直に応じるとエラーは消えます。
ベクトル演算のNotの定義(修正後)
(define_insn "one_cmpl<mode>2"
[(set (match_operand:ANYV 0 "register_operand" "=v")
(not:ANYV (match_operand:ANYV 1 "register_operand" " v")))] ★★% を消す
"TARGET_VECTOR"
"vnot.vt%0,%1"
[(set_attr "type" "logical")
(set_attr "vecmode" "<MODE>")])
四則演算、論理演算(3オペランド系)と、Not演算(2オペランド系)が揃いました。残りの頻出する演算はビットシフト系かな?
最後のオペランドをcommutativeにできない理由
最後のオペランドをcommutativeにしてはいけない理由は、GCCのConstraintsの説明を見るとわかります。
`%' Declares the instruction to be commutative for this operand and the following operand. This means that the compiler may interchange the two operands if that is the cheapest way to make all operands fit the constraints. GCC can only handle one commutative pair in an asm; if you use more, the compiler may fail. Note that you need not use the modifier if the two alternatives are strictly identical; this would only waste time in the reload pass. The modifier is not operational after register allocation, so the result of define_peephole2 and define_splits performed after reload cannot rely on `%' to make the intended insn match.
難しいことを言っていますが、commutativeは % を付けたオペランドと「次」のオペランドが可換だと宣言することだそうです。最後のオペランドには「次」のオペランドがありませんから、% を付けてはいけません。なるほど。
RISC-Vの場合は論理演算のdefine_insnの2番目のオペランドに % が使われています。
RISC-Vスカラ論理演算の定義
;; gcc/config/riscv/riscv.md
;; This code iterator allows the three bitwise instructions to be generated
;; from the same template.
(define_code_iterator any_bitwise [and ior xor])
...
(define_insn "<optab><mode>3"
[(set (match_operand:X 0 "register_operand" "=r,r")
(any_bitwise:X (match_operand:X 1 "register_operand" "%r,r")
(match_operand:X 2 "arith_operand" " r,I")))]
""
"<insn>%i2t%0,%1,%2"
[(set_attr "type" "logical")
(set_attr "mode" "<MODE>")])
例えばand r1, r2, r3とand r1, r3, r2は結果が同じですから、2番目と3番目のオペランドは入れ替え可能です。3つの論理演算(any_bitwiseはand, or, xorのこと)はいずれも同様に入れ替え可能ですので、このような定義になっています。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月21日
ARM SBCリスト2
目次: ARM
最近はたくさんのARMのシングルボードコンピュータ(SBC)が市販されています。2019年以降のボードも追加してみました。値段は変動するので参考です。
- Amlogic S905X3
- ボードHardkernel ODROID-C4, A55/2.0GHz x 4, 4GB DDR4-2666, 12nm, $50, 2020/04
- Amlogic A311D (S922X + NPU)
- ボードKhadas KVIM3-P-002, A73/2.2GHz x 4, A53/1.8GHz x 2, 4GB LPDDR4-????, 12nm, $160, 2019/06
- Amlogic S912
- ボードKhadas KVIM2-M-002, A53/1.5GHz x 8, 3GB DDR4-????, 28nm, $170, 2017/08
- Broadcom BCM2711
- ボードRaspberry Pi 4 Model B, A72/1.5GHz x 4, 8GB LPDDR4, 28nm, $75, 2019/11
- HiSilicon Kirin 970
- ボード96boards HiKey 970, A73/2.36GHz x 4, A53/1.8GHz x 4, 6GB LPDDR4-1866, 10nm, $299, 2018/??
- MediaTek Helio X20
- ボード96boards MediaTek X20, A72/2.1GHz x 2, A53/1.85GHz x 4, A53/1.4GHz x 4, 2GB LPDDR3-????, 20nm, $199, 2017/??
- NVIDIA Xavier AGX
- ボードNVIDIA Jetson Xavier AGX, Carmel/2.26GHz x 8, 8MB L2, 4MB L3, 32GB LPDDR4-2133, 12nm, $700, 2020/??
- NVIDIA Xavier NX
- ボードNVIDIA Jetson Xavier NX, Carmel/1.4GHz x 6, 6MB L2, 4MB L3, 8GB LPDDR4-1600, 12nm, $400, 2020/??
- Rockchip RK3399
- ボードFriendlyARM NanoPC-T4, A72/2GHz x 2, A53/1.5GHz x 4, 4GB LPDDR3-1866, 28nm, $109, 2018/??
- Samsung S5P6818
- ボードFriendlyARM NanoPC-T3 Plus, A53/1.4GHz x 8, 2GB DDR3, $75, 2018/??
古い世代のSoCを採用したボード達です。
- AllWinner H6
- ボードPINE64 PINE H64, A53 x 4, 2GB LPDDR3-1600, 28nm, $36
- AllWinner H5
- ボードFriendlyARM NanoPi NEO2, A53/1.5GHz x 4, 1GB DDR3, 40nm, $20
- Amlogic S905
- ボードHardkernel ODROID-C2, A53/1.5GHz x 4, 2GB DDR3-1866? (912MHz), 28nm, $39
- Broadcom BCM2837B
- ボードRaspberry Pi 3 Model B, A53/1.2GHz x 4, 1GB LPDDR2, 28nm, $35
- HiSilicon Kirin 960
- ボードHiKey 960, A72 x 4, A53 x 4, 3GB LPDDR4, 16nm FinFET, $239
- NVIDIA Tegra X2 (Parker)
- ボードJetson TX2, Denver/2GHz x 2, A57/2GHz x 4, 8GB LPDDR4, 16nm, $600
- NVIDIA Tegra X1
- ボードJetson TX1, A57/1.9GHz x 4, 4GB LPDDR4, 20nm, $500
- Rockchip RK3328
- ボードPINE64 ROCK64, A53/1.4GHz x 4, 4GB LPDDR3-1866, 28nm, $24.95 (1GB) $34.95 (2GB) $44.95 (4GB)
以前(2019年5月15日の日記参照)載せた情報も含んでいます。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月28日
またバッテリー死す
目次: 車
コロナ騒ぎが始まって、遠出することもなくなり、かれこれ4か月以上?車に乗らず放置していました。
骨折した奥さんを整形外科におくるため、JAFさんに車のバッテリー上がりを直してもらったんですけど、バッテリー電圧がなんと1Vしかありません。えー??
車のバッテリー(鉛蓄電池)の端子電圧は12V程度が正常ですから、10Vの見間違い?と思いましたけど、何回見ても1.0Vでした。乾電池だってもうちょっと電圧あるでしょう。
今まで何度となくバッテリー上がりさせ、バッテリー破壊もこれで4度目(2007年、2013年、2016年、2020年)ですけど、1Vまで下がったのは初めてです。
割とお高いGS YUASA 80D23L大容量バッテリーを使っていたのですが、いかなるバッテリーであろうと、このレベルの過放電には無力ですね。エンジン掛かった後も全く充電される気配がありませんでした。
近所のイエローハットまでバッテリー交換しに行く道中が一番嫌でした。
- 4か月ぶりの運転
- バッテリー電圧が12V〜11Vくらいでグラグラ
- アイドリングが不調で止まりそう(バッテリー上がりでエンジンの調整データが消えた?)
- エンストしたら二度と掛からない
こんな状態で、産業道路〜環七〜第二京浜と走るのはかなり怖いです。無事に辿り着けて良かったけども。
また懲りずにPanasonic 85D23Lの大容量バッテリーに交換しておきました。3万円くらいしました。たっけぇ……。今年は車検もあるし、全然乗ってない割に金ばっかり掛かってます。不思議ですね。
メモ: 技術系の話はFacebookから転記しておくことにした。
コメント一覧
- hdkさん(2020/07/30 21:40)
さすがに月イチくらいは動かしてあげてください...
ウチの原付は中古で買ってから8年半以上経っているんですが、バッテリーはそのままで未だにエンジン始動できています。買った半年後にやや電圧が低いようなことを言われていたのに、不思議です。 - すずきさん(2020/07/30 22:19)
乗る用事はないし、乗ろうと思って、いつも忘れてしまうんですよね。。。
この記事にコメントする
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報