2020年7月21日
ARM SBCリスト2
目次: ARM
最近はたくさんのARMのシングルボードコンピュータ(SBC)が市販されています。2019年以降のボードも追加してみました。値段は変動するので参考です。
- Amlogic S905X3
- ボードHardkernel ODROID-C4, A55/2.0GHz x 4, 4GB DDR4-2666, 12nm, $50, 2020/04
- Amlogic A311D (S922X + NPU)
- ボードKhadas KVIM3-P-002, A73/2.2GHz x 4, A53/1.8GHz x 2, 4GB LPDDR4-????, 12nm, $160, 2019/06
- Amlogic S912
- ボードKhadas KVIM2-M-002, A53/1.5GHz x 8, 3GB DDR4-????, 28nm, $170, 2017/08
- Broadcom BCM2711
- ボードRaspberry Pi 4 Model B, A72/1.5GHz x 4, 8GB LPDDR4, 28nm, $75, 2019/11
- HiSilicon Kirin 970
- ボード96boards HiKey 970, A73/2.36GHz x 4, A53/1.8GHz x 4, 6GB LPDDR4-1866, 10nm, $299, 2018/??
- MediaTek Helio X20
- ボード96boards MediaTek X20, A72/2.1GHz x 2, A53/1.85GHz x 4, A53/1.4GHz x 4, 2GB LPDDR3-????, 20nm, $199, 2017/??
- NVIDIA Xavier AGX
- ボードNVIDIA Jetson Xavier AGX, Carmel/2.26GHz x 8, 8MB L2, 4MB L3, 32GB LPDDR4-2133, 12nm, $700, 2020/??
- NVIDIA Xavier NX
- ボードNVIDIA Jetson Xavier NX, Carmel/1.4GHz x 6, 6MB L2, 4MB L3, 8GB LPDDR4-1600, 12nm, $400, 2020/??
- Rockchip RK3399
- ボードFriendlyARM NanoPC-T4, A72/2GHz x 2, A53/1.5GHz x 4, 4GB LPDDR3-1866, 28nm, $109, 2018/??
- Samsung S5P6818
- ボードFriendlyARM NanoPC-T3 Plus, A53/1.4GHz x 8, 2GB DDR3, $75, 2018/??
古い世代のSoCを採用したボード達です。
- AllWinner H6
- ボードPINE64 PINE H64, A53 x 4, 2GB LPDDR3-1600, 28nm, $36
- AllWinner H5
- ボードFriendlyARM NanoPi NEO2, A53/1.5GHz x 4, 1GB DDR3, 40nm, $20
- Amlogic S905
- ボードHardkernel ODROID-C2, A53/1.5GHz x 4, 2GB DDR3-1866? (912MHz), 28nm, $39
- Broadcom BCM2837B
- ボードRaspberry Pi 3 Model B, A53/1.2GHz x 4, 1GB LPDDR2, 28nm, $35
- HiSilicon Kirin 960
- ボードHiKey 960, A72 x 4, A53 x 4, 3GB LPDDR4, 16nm FinFET, $239
- NVIDIA Tegra X2 (Parker)
- ボードJetson TX2, Denver/2GHz x 2, A57/2GHz x 4, 8GB LPDDR4, 16nm, $600
- NVIDIA Tegra X1
- ボードJetson TX1, A57/1.9GHz x 4, 4GB LPDDR4, 20nm, $500
- Rockchip RK3328
- ボードPINE64 ROCK64, A53/1.4GHz x 4, 4GB LPDDR3-1866, 28nm, $24.95 (1GB) $34.95 (2GB) $44.95 (4GB)
以前(2019年5月15日の日記参照)載せた情報も含んでいます。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2020年7月20日
GCCを調べる - その18 - ベクトルNot演算の定義
目次: GCC
前回(2020年7月19日の日記参照)は四則演算と論理演算(and, or, xor)を定義しました。今回はNot演算を定義します。他の論理演算と異なり、Not演算は2オペランドしか取りませんから、define_insnを別に書く必要があります。
ベクトルNot演算の定義
;; gcc/config/riscv/riscv.md
(define_insn "one_cmpl<mode>2"
[(set (match_operand:ANYV 0 "register_operand" "=v")
(not:ANYV (match_operand:ANYV 1 "register_operand" "%v")))]
"TARGET_VECTOR"
"vnot.vt%0,%1"
[(set_attr "type" "logical")
(set_attr "vecmode" "<MODE>")])
前回同様に、ベクトル拡張記法(Vector Extensions (Using the GNU Compiler Collection (GCC)))を使ってビット毎Notを使うプログラムを書きます。
ベクトルNot演算のサンプルプログラム
typedef int __v64si __attribute__((__vector_size__(256)));
void test()
{
__v64si v10, v11;
static int b[1024 * 1024] = {0};
__asm__ volatile ("vlw.v %0, %1\n" : "=&v"(v10) : "A"(b[10]));
__asm__ volatile ("vlw.v %0, %1\n" : "=&v"(v11) : "A"(b[20]));
v10 = ~v11;
__asm__ volatile ("vsw.v %1, %0\n" : "=A"(b[40]) : "v"(v10));
}
コンパイルするとエラーが発生します。何かお気に召さないようです。
コンパイルエラー
$ riscv32-unknown-elf-gcc b.c -nostdlib -Og -march=rv32gcv -mabi=ilp32f
during RTL pass: reload
dump file: b.c.282r.reload
b.c: In function 'test':
b.c:14:1: internal compiler error: in setup_operand_alternative, at lra.c:814
14 | }
| ^
0xea5c36 setup_operand_alternative
gcc/gcc/lra.c:814
0xea70c2 lra_set_insn_recog_data(rtx_insn*)
gcc/gcc/lra.c:1073
0xea30f9 lra_get_insn_recog_data
gcc/gcc/lra-int.h:488
0xeab0b9 remove_scratches_1
gcc/gcc/lra.c:2058
0xeab4c4 remove_scratches
gcc/gcc/lra.c:2094
0xeac629 lra(_IO_FILE*)
gcc/gcc/lra.c:2396
0xe1a41f do_reload
gcc/gcc/ira.c:5523
0xe1ae5c execute
gcc/gcc/ira.c:5709
コードを見ると最後のオペランドに % を付けるべきではないそうです。確かにdefine_insnを見ると % が要らないのに付いています。
エラーを出している箇所
// gcc/lra.c
/* Setup info about operands in alternatives of LRA DATA of insn. */
static void
setup_operand_alternative (lra_insn_recog_data_t data,
const operand_alternative *op_alt)
{
int i, j, nop, nalt;
int icode = data->icode;
struct lra_static_insn_data *static_data = data->insn_static_data;
static_data->commutative = -1;
nop = static_data->n_operands;
nalt = static_data->n_alternatives;
static_data->operand_alternative = op_alt;
for (i = 0; i < nop; i++)
{
static_data->operand[i].early_clobber_alts = 0;
static_data->operand[i].is_address = false;
if (static_data->operand[i].constraint[0] == '%') //★★% が付いていればcommutative
{
/* We currently only support one commutative pair of operands. */
if (static_data->commutative < 0)
static_data->commutative = i;
else
lra_assert (icode < 0); /* Asm */
/* The last operand should not be marked commutative. */
lra_assert (i != nop - 1); //★★このアサートに引っかかる
}
}
...
素直に応じるとエラーは消えます。
ベクトル演算のNotの定義(修正後)
(define_insn "one_cmpl<mode>2"
[(set (match_operand:ANYV 0 "register_operand" "=v")
(not:ANYV (match_operand:ANYV 1 "register_operand" " v")))] ★★% を消す
"TARGET_VECTOR"
"vnot.vt%0,%1"
[(set_attr "type" "logical")
(set_attr "vecmode" "<MODE>")])
四則演算、論理演算(3オペランド系)と、Not演算(2オペランド系)が揃いました。残りの頻出する演算はビットシフト系かな?
最後のオペランドをcommutativeにできない理由
最後のオペランドをcommutativeにしてはいけない理由は、GCCのConstraintsの説明を見るとわかります。
`%' Declares the instruction to be commutative for this operand and the following operand. This means that the compiler may interchange the two operands if that is the cheapest way to make all operands fit the constraints. GCC can only handle one commutative pair in an asm; if you use more, the compiler may fail. Note that you need not use the modifier if the two alternatives are strictly identical; this would only waste time in the reload pass. The modifier is not operational after register allocation, so the result of define_peephole2 and define_splits performed after reload cannot rely on `%' to make the intended insn match.
難しいことを言っていますが、commutativeは % を付けたオペランドと「次」のオペランドが可換だと宣言することだそうです。最後のオペランドには「次」のオペランドがありませんから、% を付けてはいけません。なるほど。
RISC-Vの場合は論理演算のdefine_insnの2番目のオペランドに % が使われています。
RISC-Vスカラ論理演算の定義
;; gcc/config/riscv/riscv.md
;; This code iterator allows the three bitwise instructions to be generated
;; from the same template.
(define_code_iterator any_bitwise [and ior xor])
...
(define_insn "<optab><mode>3"
[(set (match_operand:X 0 "register_operand" "=r,r")
(any_bitwise:X (match_operand:X 1 "register_operand" "%r,r")
(match_operand:X 2 "arith_operand" " r,I")))]
""
"<insn>%i2t%0,%1,%2"
[(set_attr "type" "logical")
(set_attr "mode" "<MODE>")])
例えばand r1, r2, r3とand r1, r3, r2は結果が同じですから、2番目と3番目のオペランドは入れ替え可能です。3つの論理演算(any_bitwiseはand, or, xorのこと)はいずれも同様に入れ替え可能ですので、このような定義になっています。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月19日
GCCを調べる - その17 - ベクトル四則演算、論理演算の定義
目次: GCC
ベクトルのロード、ストアだけでは自動ベクトル化できるコードが少なすぎるので、他の演算も定義したいと思います。
ベクトル演算の加算、減算、乗算、除算、論理演算(and, or, xor)の定義
;; gcc/config/riscv/riscv.md
(define_attr "vecmode" "unknown,V32SI,V64SI"
(const_string "unknown"))
...
;; Iterator for hardware supported vector modes.
(define_mode_iterator ANYV [(V32SI "TARGET_VECTOR")
(V64SI "TARGET_VECTOR")])
...
;;★★加算
(define_insn "add<mode>3"
[(set (match_operand:ANYV 0 "register_operand" "=v")
(plus:ANYV (match_operand:ANYV 1 "register_operand" " v")
(match_operand:ANYV 2 "arith_operand" " v")))]
"TARGET_VECTOR"
"vadd.vvt%0,%1,%2"
[(set_attr "type" "arith")
(set_attr "vecmode" "<MODE>")])
;;★★減算
(define_insn "sub<mode>3"
[(set (match_operand:ANYV 0 "register_operand" "=v")
(minus:ANYV (match_operand:ANYV 1 "register_operand" " v")
(match_operand:ANYV 2 "arith_operand" " v")))]
"TARGET_VECTOR"
"vsub.vvt%0,%1,%2"
[(set_attr "type" "arith")
(set_attr "vecmode" "<MODE>")])
;;★★乗算
(define_insn "mul<mode>3"
[(set (match_operand:ANYV 0 "register_operand" "=v")
(mult:ANYV (match_operand:ANYV 1 "register_operand" " v")
(match_operand:ANYV 2 "arith_operand" " v")))]
"TARGET_VECTOR"
"vmul.vvt%0,%1,%2"
[(set_attr "type" "arith")
(set_attr "vecmode" "<MODE>")])
;;★★除算
;; This code iterator allows unsigned and signed division to be generated
;; from the same template.
(define_code_iterator any_div [div udiv mod umod])
(define_insn "<optab><mode>3"
[(set (match_operand:ANYV 0 "register_operand" "=v")
(any_div:ANYV (match_operand:ANYV 1 "register_operand" " v")
(match_operand:ANYV 2 "arith_operand" " v")))]
"TARGET_VECTOR"
"v<insn>.vvt%0,%1,%2"
[(set_attr "type" "arith")
(set_attr "vecmode" "<MODE>")])
;;★★論理演算
;; This code iterator allows the three bitwise instructions to be generated
;; from the same template.
(define_code_iterator any_bitwise [and ior xor])
...
(define_insn "<optab><mode>3"
[(set (match_operand:ANYV 0 "register_operand" "=v")
(any_bitwise:ANYV (match_operand:ANYV 1 "register_operand" "%v")
(match_operand:ANYV 2 "arith_operand" " v")))]
"TAREGET_VECTOR"
"v<insn>.vvt%0,%1,%2"
[(set_attr "type" "logical")
(set_attr "vecmode" "<MODE>")])
四則演算、論理演算を使う下記のプログラムを書きます。自動ベクトル化で四則演算のループをベクトル化しても良いですが、ベクトル拡張記法(Vector Extensions (Using the GNU Compiler Collection (GCC)))を使ったほうが狙った演算が出しやすく、テストするときに楽です。
ベクトル四則演算、論理演算のサンプルプログラム
typedef int __v64si __attribute__((__vector_size__(256)));
void test()
{
__v64si v10, v11, v12, v13;0;
__asm__ volatile ("vlw.v %0, %1\n" : "=&v"(v10) : "A"(b[10]));
__asm__ volatile ("vlw.v %0, %1\n" : "=&v"(v11) : "A"(b[20]));
__asm__ volatile ("vlw.v %0, %1\n" : "=&v"(v12) : "A"(b[30]));
__asm__ volatile ("vlw.v %0, %1\n" : "=&v"(v13) : "A"(b[40]));
v10 = v11 + v12;
v11 &= v12 - v13;
v12 |= v13 * v10;
v13 ^= v10 / v11;
__asm__ volatile ("vsw.v %1, %0\n" : "=A"(b[40]) : "v"(v10));
__asm__ volatile ("vsw.v %1, %0\n" : "=A"(b[50]) : "v"(v11));
__asm__ volatile ("vsw.v %1, %0\n" : "=A"(b[60]) : "v"(v12));
__asm__ volatile ("vsw.v %1, %0\n" : "=A"(b[70]) : "v"(v13));
}
ビルド方法は何でも良いですが、最適化レベルをOgにするとアセンブラが見やすいと思います。
ベクトル四則演算、論理演算のサンプルプログラム(逆アセンブル)
$ riscv32-unknown-elf-gcc b.c -nostdlib -g -Og -march=rv32gcv -mabi=ilp32f
$ riscv32-unknown-elf-objdump -dS a.out
...
__asm__ volatile ("vlw.v %0, %1\n" : "=&v"(v13) : "A"(b[40]));
10092: 0a028793 addi a5,t0,160
10096: 1207e207 vlw.v v4,(a5)
v10 = v11 + v12;
1009a: 022081d7 vadd.vv v3,v2,v1
v11 &= v12 - v13;
1009e: 0a120057 vsub.vv v0,v1,v4
100a2: 26010057 vand.vv v0,v0,v2
v12 |= v13 * v10;
100a6: 9641a157 vmul.vv v2,v4,v3
100aa: 2a208157 vor.vv v2,v2,v1
v13 ^= v10 / v11;
100ae: 863020d7 vdiv.vv v1,v3,v0
100b2: 2e1200d7 vxor.vv v1,v1,v4
__asm__ volatile ("vsw.v %1, %0\n" : "=A"(b[40]) : "v"(v10));
100b6: 0207e1a7 vsw.v v3,(a5)
...
うまくいっているようです。良かった良かった。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月18日
北極送り
GitHubが北極にコードを保存する取り組み(私のソースコードが北極送りに? "GitHub" アカウントに謎のラベルが付与されたとの報告が多数 - やじうまの杜 - 窓の杜)をしているそうです。面白いこと考えますよね。

GitHub Arctic Code Vault Contributor
気づいたら自分のGitHubアカウントにもArctic Code Vault Contributorと出ていました。有名なOSSには関わってないし縁がないと思っていましたが、どうやらLinuxにコントリビュートしていたので出てきたっぽいです。いわれてみるとLinuxもGitHubにミラーされてました。
未来人は現代人を理解できるだろうか?
現代人をもってしても1000年前の文字の解読(例: ヒエログリフ、前3200年〜4世紀、19世紀頃に解読された)はとても苦労したこと、解読されていない古代文字がまだまだあることを考えれば、現代文字や文明を遺しても未来人が理解不能で終わってしまう可能性もあるわけです。
少なくとも未来文明は現代文明より遥か上の水準に発展していないと、仮に現代文字や文明を発見できても、真に理解するのは難しいでしょう。
こんなことを考えると、実はCode Vaultの取り組みは「地球の未来は今より進んでいるはず」という信頼や願望が前提になっていることが見て取れます。人類か、それ以外の生命体か、誰の手に渡るかわかりませんが、SF的なロマンがありますよね。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月15日
GCCを調べる - その16 - 自動ベクトル化を有効にする
目次: GCC
GCCには自動ベクトル化(tree-vectorize)機能があります。ループ処理を自動的にSIMD命令に置き換えるために使われているようです。現状のGCCが可変長のベクトル長に対応しているかどうかはわかりません。未対応ならば可変長のベクトル長に対応する実装が必要になりますが、非常に難しそうです。
可変長のベクトルの扱いはひとまず横に置くとして、RISC-Vのベクトルを「とても長い固定長のSIMD」とみなして自動ベクトル化を動かします。
自動ベクトル化を有効にするコード
// gcc/config/riscv/riscv.c
/* Implement TARGET_VECTORIZE_AUTOVECTORIZE_VECTOR_MODES. */
static unsigned int
riscv_autovectorize_vector_modes (vector_modes *modes, bool)
{
if (TARGET_VECTOR)
{
modes->safe_push (V64SImode);
modes->safe_push (V32SImode);
}
return 0;
}
...
#undef TARGET_VECTORIZE_AUTOVECTORIZE_VECTOR_MODES
#define TARGET_VECTORIZE_AUTOVECTORIZE_VECTOR_MODES riscv_autovectorize_vector_modes
自動ベクトル化を有効にする方法は簡単で、これだけです。
テスト用のint配列をコピーする関数
void *cpy(void *dst, const void *src, int n)
{
int *d = dst;
const int *s = src;
int i;
for (i = 0; i < n / sizeof(*d); i++) {
d[i] = s[i];
}
return dst;
}
この関数がベクトル化あり、なしでどのように変わるか見ます。
自動ベクトル化の結果
//★★自動ベクトル化、あり
d[i] = s[i];
100b8: 1202e007 vlw.v v0,(t0)
100bc: 10038393 addi t2,t2,256
100c0: f0038793 addi a5,t2,-256
100c4: 10028293 addi t0,t0,256
100c8: 0207e027 vsw.v v0,(a5)
for (i = 0; i < n / sizeof(*d); i++) {
100cc: fee296e3 bne t0,a4,100b8 <cpy+0x44>
100d0: 00661293 slli t0,a2,0x6
100d4: 02568963 beq a3,t0,10106 <cpy+0x92>
100d8: 959a add a1,a1,t1
100da: 932a add t1,t1,a0
d[i] = s[i];
100dc: 0005a383 lw t2,0(a1)
//★★自動ベクトル化、なし
d[i] = s[i];
10080: 0005a303 lw t1,0(a1)
for (i = 0; i < n / sizeof(*d); i++) {
10084: 0591 addi a1,a1,4
10086: 0291 addi t0,t0,4
d[i] = s[i];
10088: fe62ae23 sw t1,-4(t0)
for (i = 0; i < n / sizeof(*d); i++) {
1008c: fe759ae3 bne a1,t2,10080 <cpy+0xc>
}
return dst;
}
10090: 8082 ret
ソースコードではベクトル型を使っていませんが、自動ベクトル化により256バイト(=64要素)ずつ処理され、vlw.v, vsw.v命令が使われるようになったことがわかります。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月14日
OpenCLとICD
目次: OpenCL
OpenCLは複数のベンダーのデバイスを同時に扱うことができます。ICD(Installable Client Driver)というそうです。ICDはGPUなどのデバイスを制御し、アプリケーションとICDの間にICDローダーが存在します。
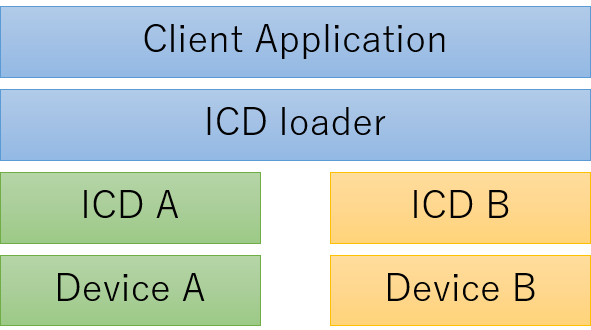
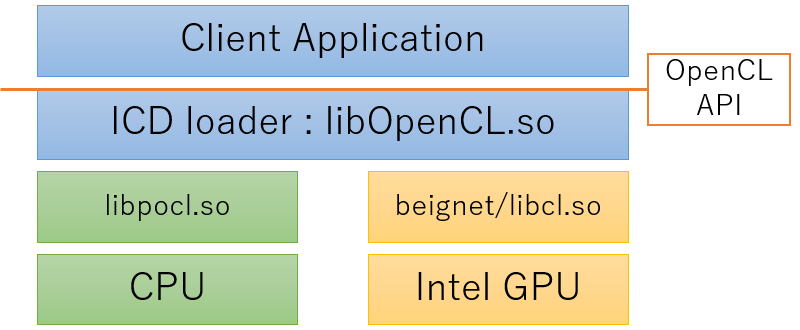
Debian TestingではICDローダーとしてocl-icd-2.2.12が使われています。
Debian TestingのICD loader
$ apt-cache search ocl-icd-libopencl1 ocl-icd-libopencl1 - Generic OpenCL ICD Loader
ローダーのソースコードはGitHub(リンク)にあります。
先程、図示したもの以外にもICDはいくつか実装があります。現時点のDebian Testingでは下記が提供されていました。
- pocl-opencl-icd: 主にCPU向け
- beignet-opencl-icd: 比較的古いIntel GPU向け
- intel-opencl-icd: 比較的新しいIntel GPU向け、Testingにしか存在しない
- mesa-opencl-icd: AMD GPU向け
- nvidia-opencl-icd: nVidia GPU向け、ソースコードは公開されていない
IntelはICDのソースコードを完全にオープンにしています。NVIDIAは公開していません。AMDもないのかな?
ICDのロード手順
動作を追ってみたいと思います。アプリケーションにはclinfoを使います。ocl-icdは環境変数OCL_ICD_DEBUG=15に設定すると、動作時に詳細なログを出力します。デバッガで追うのと併用するとわかりやすいです。
- clinfo: clGetPlatformIDs() を呼ぶ
- ocl-icd: _initClIcd() -> _initClIcd_real() -> __initClIcd()
- ocl-icd: _find_num_icds(): /etc/OpenCL/vendorsの *.icdファイルを見る(*.soへのパスが書いてある)
- ocl-icd: _load_icd(): *.soをdlopen()
- ocl-icd: _find_and_check_platforms(): 後述
ローダーが走査するディレクトリは /etc/OpenCL/vendorsがハードコードされていますが、環境変数OPENCL_VENDOR_PATHで変更できます。
ICDのロードの中心となる処理は _find_and_check_platforms() です。
- dlsym() でclGetExtensionFunctionAddress() のアドレスを得る
- clGetExtensionFunctionAddress() でclIcdGetPlatformIDsKHR() のアドレスを得る
- clGetExtensionFunctionAddress() でclGetPlatformInfo() のアドレスを得る
- clIcdGetPlatformIDsKHR() でプラットフォーム数とプラットフォームの情報を得る
プラットフォームは説明が難しいですが、OpenCL APIの実体+任意のドライバ固有のデータとでも言いましょうか。変数の型はcl_platform_id * 型です。cl_platform_idは少なくとも先頭のメンバはstruct _cl_icd_dispatch *dispatchでなければなりません。dispatchの後ろには他の情報が入っていても問題ないようです。
cl_platform_idとdispatch
// ocl-icd/ocl_icd_loader.c
static inline void _find_and_check_platforms(cl_uint num_icds) {
cl_uint i;
...
cl_platform_id *platforms = (cl_platform_id *) malloc( sizeof(cl_platform_id) * num_platforms);
error = (*plt_fn_ptr)(num_platforms, platforms, NULL);
...
for(j=0; j<num_platforms; j++) {
debug(D_LOG, "Checking platform %i", j);
struct platform_icd *p=&_picds[_num_picds];
char *param_value=NULL;
p->extension_suffix=NULL;
p->vicd=&_icds[i];
p->pid=platforms[j]; //★★pid = platform IDのことらしい
/* If clGetPlatformInfo is not exported and we are here, it
* means that OCL_ICD_ASSUME_ICD_EXTENSION. Si we try to take it
* from the dispatch * table. If that fails too, we have to
* bail.
*/
if (plt_info_ptr == NULL) {
plt_info_ptr = p->pid->dispatch->clGetPlatformInfo; //★★dispatchメンバが存在することを前提としている
// ocl-icd/khronos-headers/CL/cl.h
typedef struct _cl_platform_id * cl_platform_id;
// ocl-icd/(build-dir)/ocl_icd_loader_gen.h
struct _cl_platform_id { struct _cl_icd_dispatch *dispatch; }; //★★dispatch以外は特に規定がなさそう
// ocl-icd/(build-dir)/ocl_icd.h
struct _cl_icd_dispatch {
#ifdef CL_VERSION_1_0
CL_API_ENTRY cl_int (CL_API_CALL*clGetPlatformIDs)(
cl_uint /* num_entries */,
cl_platform_id * /* platforms */,
cl_uint * /* num_platforms */
) CL_API_SUFFIX__VERSION_1_0;
#else
CL_API_ENTRY cl_int (CL_API_CALL* clUnknown0)(void);
#endif
#ifdef CL_VERSION_1_0
CL_API_ENTRY cl_int (CL_API_CALL*
clGetPlatformInfo)(
cl_platform_id /* platform */,
cl_platform_info /* param_name */,
size_t /* param_value_size */,
void * /* param_value */,
size_t * /* param_value_size_ret */
) CL_API_SUFFIX__VERSION_1_0;
#else
CL_API_ENTRY cl_int (CL_API_CALL* clUnknown1)(void);
#endif
...
//★★こんな調子で関数ポインタの定義が延々と続く
先頭のdispatchはたくさんの関数ポインタが並んだ巨大な構造体です。アプリケーションから見るとOpenCLのAPIはocl-icdが提供しているように見えますが、ocl-icdのAPI実装はdispatchの関数ポインタを呼ぶラッパー関数であり、関数ポインタと、OpenCL API実装の本体を提供するのは各ICDの役割です。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月12日
MAD Tower Tycoonコンプリート
目次: ゲーム
MAD Tower Tycoonでゾーン方式のエレベータの作り方を悩んで色々やっていたら、いつのまにかレベル100、実績コンプリートしていました。ゲーム内時間は表示されないので詳しくはわかりませんが、おそらく700日くらい?
The Towerと比べて色々思うところはありますが、総合的にみれば面白いと思います。
序盤だけ金欠になりやすいですが、難易度はかなり低めですし、ビル建築シミュレーション初めての方にオススメしたいゲームです。
高層ビルを作りたい
MAD Tower Tycoonは住人を追尾する機能があり、ビルの住人が困っていないか把握するのに便利です。基本的には目的地に行って、家に帰る(住人の場合)、もしくはビルから出る(ゲストの場合)だけですけど、大きなビルを作ると変な行動が目立ちます。
- ビルの端から端まで歩いて、わざわざ遠いエレベーターで乗り換え
- 近所のレストランを無視して、わざわざ遠いレストランに行く
前回(2020年7月10日の日記参照)も書きましたが、MAD Tower Tycoonはゾーン方式のエレベーターを作る方法がわかりません。今はメンテナンス施設の射程(上下6Fに効果がある)の関係で、7階+8階(※)おきに乗り換え階を作っています。
どうもこの方式だと40階くらいで限界っぽいです。乗り換えに時間が掛かりすぎて、目的地に行くだけで半日費やしている気の毒な住民がいます。彼らはなぜか不満は言いませんが、見ていると不憫です……。
救いとしてはMAD Tower Tycoonはビルの横幅がめちゃくちゃ広く取れるので、45階もあれば、レベル100、五つ星ビルが余裕で作れることです。だけど、やっぱりThe Towerにあやかるなら、100階建て目指したいですよね?
(※)効率重視ならば7F, 14F乗り換えが最適ですが、スカイロビーを作成できるのは15Fからなので、あえて14Fを空きフロアにして、15F乗り換えにしています。
どうしてもThe Towerと比較してしまう
MAD Tower Tycoonは、The Towerとかなり似ているがゆえに、つい比較してしまいます。
良いところ
- エレベータ乗り換えがロビー階以外でも可能
- 何度でも乗り継げる(1F → 7F → 15F → 23Fのような乗り継ぎが可能)
- かなり上の階でも階段で行ける(The Towerは確か4Fくらいしか上らない)
悪いところ
- エレベータの通過階設定ができない(今、一番困っている制限)※通過階設定はできるが設定が効かないバグ、とのこと(2023/10/20追記)
- 一度上に行ってから、下に行く乗り換えが不可能(1F → 15F → 7Fみたいな乗り換えはしないようだ)
ゾーン方式のエレベーターが作れたら、高層ビルに効率的に人を運べるようになって、もっと面白くなるはずなのに。もったいないよ〜。
コメント一覧
- わしださん(2020/08/10 22:36)
The Tower懐かしいですね。
話題とずれる荒しみたいなコメントになりますが、旧姓でエゴサーチして最も古い自分の名前が出るのが、Geocitiesの他人のサイトに投稿したThe towerのビルでした。小6くらいだったのですが、本名とビル名に「第百ビル」とか付けてて。
その10年以上後、新卒で会社入って最初の移動先の課長に「第百ビルの人?」って聞かれてびびりました。(会社入って一年くらいは旧姓だったので)
いまはGeocitiesも閉鎖になったので出てきませんが、いい思い出ではあります。
ということでとにもかくにも100階建てにしてチャペル建てたくなる気持ちを思い出しました。 - すずきさん(2020/08/11 18:59)
小学生でサイトに投稿はスゴイです。そして会社バレしてるのも奇遇というかなんというか。
The Tower で遊んでいたのは、たしか中学生時代だったと思いますが、当時インターネットとかパソコン通信はさっぱりわからず、ビルを投稿しようという考えが全くなかったです。
Mad Tower Tycoon も 100階にチャペルを建てられますが、The Tower ほどの重要なポジションではない(集客施設の一つに過ぎない)です。星 3〜4辺りからゲーム性が極端に下がってダレてしまうのも、ちょっと残念なポイントです。 - 通り縋りさん(2023/10/18 19:08)
上の記事2023年9月編集という事ですが間違ってます。
2023年10月現在、正しくは「エレベーターの通過階設定自体は出来るが正確に反映されない」です。
通過階設定自体は出来る事を確認してますが、特に高速エレベーターに於いて設定が正常に反映されず「通過階にも待ちが発生し停車してしまう」というバグとなっています。 - すずきさん(2023/10/19 11:17)
ご指摘ありがとうございます。9月の編集は先頭にリンクを加えただけで、内容は2020年7月に書いたときのままです。わかりにくくてすみません。
それは良いとして、ご指摘の内容に合わせて修正しておきます。
この記事にコメントする
2020年7月11日
STATIONflow実績コンプリート
目次: ゲーム
STATIONflowの実績をコンプリートしました。「ラッキーセブン」と「東京」は自動化マクロを組まないと取れませんでした。
本来、このゲームにハマって色々なマップをずっと遊んでいたらいつのまにか取れていた、というタイプの実績ですが、申し訳ないことに、私はそこまでの情熱がなかったです。
ゲームやったらわかりますけど、この2つの実績だけ条件設定が異常すぎます。
- 1日の利用者数は最大17,000人程度(全出入口&乗り場が最大レベルの駅)
- 1390万人達成には単純計算でゲーム内時間800日程度
- STATIONflowの1日は最速でも15分、普通に遊ぶと30分〜1時間くらい
- 最速でも200時間は必要
実績の条件(総利用者数700万人、1,390万人)がいかに異常かがわかると思います。
自動化
自動化の方法は簡単で、PowerShellでEnterキーを3秒に1回送るマクロを組んで、会社行っている間や夜間に放置するだけです。2週間くらいで取れました。
STATIONflowは放置しても悪いイベントが起きない(=駅が壊れない)優しい仕様になっているため、自動化+放置が可能でしたが、他のシミュレーションゲームだと偶発的に悪いイベントが起きるため、この方法は使えません。
まあ、明らかに製作者の想定した取り方ではないし、こんな方法で実績取っても嬉しくないし、無理に実績取るのは今後はやめておきます。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月10日
MAD Tower Tycoon楽しい
目次: ゲーム
最近Steamで買った、MAD Tower Tycoon(開発: Eggcode)で遊んでいます。

ビル建築&経営シミュレーションゲームです。プレイヤーはビルを拡張していって、テナントや住居を作ります。テナントには住人やゲストが押し寄せてきますので、住人のストレスを溜めないように、メンテナンス施設を足したり、階段、エスカレーター、エレベーターでうまく捌き、儲けを出して、ビルをさらに拡張させるというゲームです。
The Towerの後継者?
ビル建築&経営シミュレーションの名作はThe Tower(開発: OPeNBooK)だと思います。The Towerは続編が出なくなって久しく寂しかったですが、MAD Tower TycoonはかなりThe Towerに近い作りです。
後追いだけあって基本的にThe Towerより良くなっていますが、残念な部分もあって、
- 上階に伸ばすときの建設が面倒くさい
- 中盤から金が余りまくる
- オフィス、住宅からの変な苦情(人通りが多い)
- 横移動のストレスがない、もしくは非常に低い
- エレベーターは速いが、自由度が低い
難易度は最近の風潮で優しめだとしても、最後のエレベーターの劣化は残念です。
エレベーターの変な仕様
エレベーターはThe Towerのキモで、説明書でも詳しく説明していました。MAD Tower Tycoonのエレベーターの場合は、
- エレベータのカゴ数が最大3で少ない
- 通過階の設定ができない(降車専用ならある)
特に後者の制限が厳しくて、ゾーン方式(※)エレベーターが実質建設不可能で、高層ビルを作るには厳しい仕様となっています。
(※)エレベーターを複数基用意して、1つ目は1〜5階のみ、2つ目は5〜10階のみなど、一部の階しか止まらないエレベーターを作る方式のことです。現実でも高層ビルでよく見かけます。
むりやりゾーン方式エレベーターを作るとどうなる?
バグなのか仕様なのかわからないですが、MAD Tower Tycoonではバルコニーでフロアをぶち抜いて、スカイブリッジを作ると、どことも繋がらない孤立したフロアを作れます。
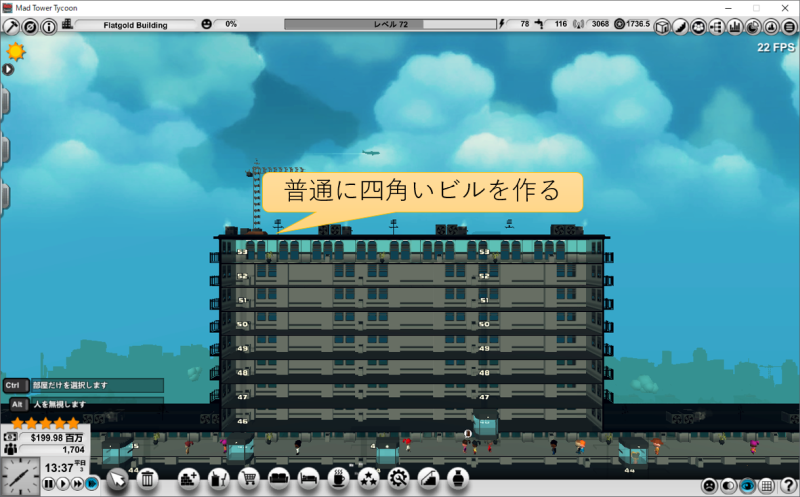
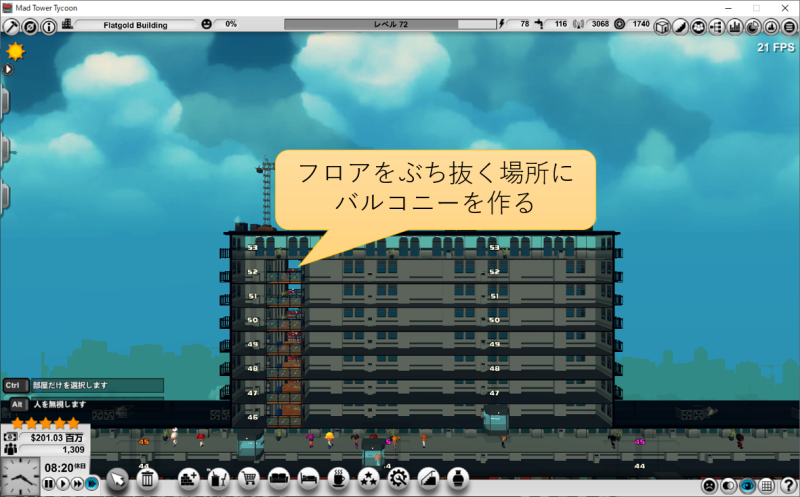
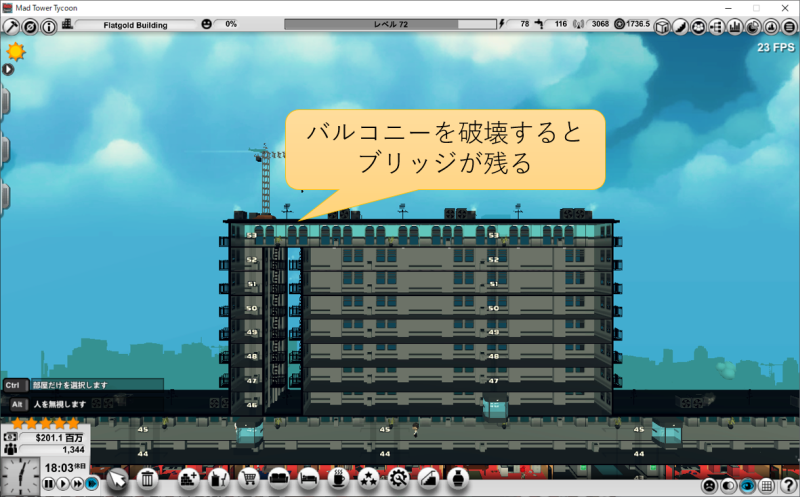
孤立したフロアにエレベーターだけを設置することで、実質的に乗車降車禁止階にできます。
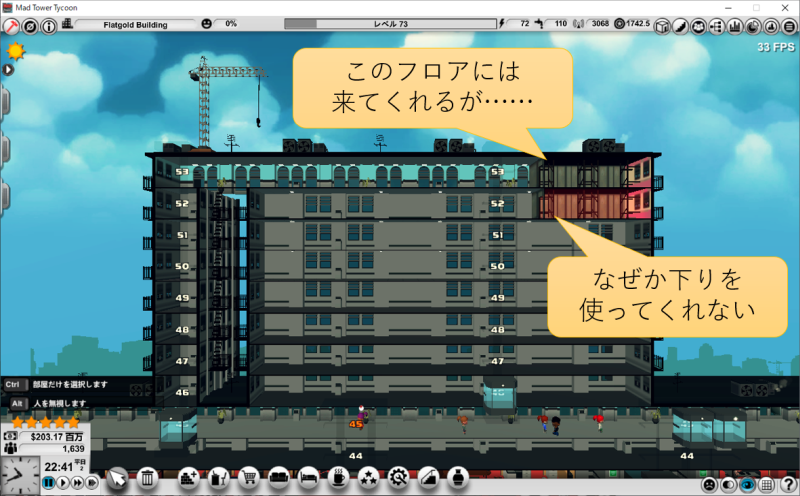
ところがこの乗車降車禁止エレベータを作っても、なぜか住人は一切利用してくれません。訳が分かりません。どうしたら良いんでしょうか??
オープンブックの紆余曲折
The Tower開発元のOPeNBooKは合併と名前変更を繰り返しています。合併相手は9003, incで、AQUAZONEという熱帯魚育成&水槽シミュレーションで名を馳せたベンダーです。
1993 2000
OPeNBooK ---, 1996 ,--> オープンブック(The Towerの版権を持つ)
+--> オープンブック9003 ---+--> シノミクス
9003, inc ---'
1990
Wikipediaを見るとこんな経歴でした。お互い、元の鞘に収まったという感じがします。合併したけどやることがなかったんですかね?
コメント一覧
- わしださん(2020/08/10 22:40)
オープンブック9003時代に鳥(Pinna?)飼ってました・・・熱帯魚はともかくなぜ鳥飼育ゲーを買ったのか、今となっては心境が分かりません・・・。 - すずきさん(2020/08/11 18:59)
鳥のゲームは知りませんでした。色々やってるなあ。オープンブック……。
あの頃は、PCの解像度がどんどん上がって綺麗になっていて、飼育ゲームとかアクアリウム的な、眺めるタイプの奴が流行ってましたよね。
この記事にコメントする
2020年7月9日
ノートPCの発熱を抑える方法 - その2
目次: Windows
前回(2020年6月29日の日記参照)、ノートPCの発熱を抑えるためにCPUのクロック上限を抑える設定をしました。
前回はTurboBoostだけ無効化する方法がわかりませんでしたが、ググっていたら割と簡単にTurboBoostを無効化できることがわかりました。
レジストリエディタで、
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\Power\PowerSettings\54533251-82be-4824-96c1-47b60b740d00\be337238-0d82-4146-a960-4f3749d470c7
のAttributesというDWORD値を1から0 or 2に変更します(※)。
すると下記の「プロセッサ パフォーマンスの向上モード」オプションが出現しますので、無効を選択します。
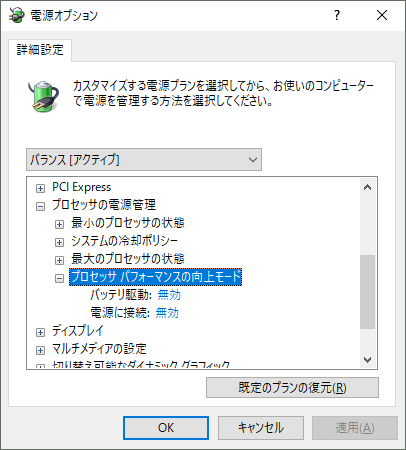
TurboBoostを無効化すると、最大のプロセッサの状態を100% にしても、ベース周波数の1.6GHzまでしか周波数が上がらなくなります。これは良い感じだ。
- 〜54%: 0.90GHz
- 〜60%: 0.99GHz
- 〜65%: 1.10GHz
- 〜71%: 1.19GHz
- 〜76%: 1.30GHz
- 〜82%: 1.39GHz
- 〜87%: 1.49GHz
- 〜100%: 3.36GHz → 1.59GHz
(※)私はSurface ProでCPUクロックが最大に張り付くという問題(フォーラムへのリンク)の解決策に載っていたものを見つけたのですが、どうも昔のWindows 8で消えた設定らしい(ASCII.jp : Windows 8.1で消えた詳細な電源管理項目を表示する!より)です。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年7月8日
GCCを調べる - その15-3 - ベクトルレジスタを使用するmachine mode
目次: GCC
前回(2020年7月7日の日記参照)はベクトルレジスタが選択されてしまう仕組みが何となくわかりました。
今回やりたかったことを復習しておくと「ベクトルの演算以外でベクトルレジスタを使わないでほしい」でした。つまりira_prohibited_class_mode_regs[cl][j] のうちベクトル以外のmachine modeかつベクトルレジスタに相当するビットを「セット」つまり割り当て禁止状態にすれば良いはずです。
配列の次元のうちclはレジスタのクラス(enum reg_class)で、jはmachine modeです。レジスタのクラスは以前(2020年3月28日の日記参照)ちょっとだけ使いました。幸いなことに、今回はレジスタのクラスは気にしなくて良いです、というかコードのif文の条件hard_regno_mode_ok(hard_regno, (machine_mode) j) を見るとわかるように、そもそもレジスタのクラスが渡されないので、ターゲット側(=RISC-V依存の実装部分)で何もできないです。
重要なのはmachine modeで、ベクトル以外のモード(浮動小数点など)だったらベクトルレジスタを割り当て禁止状態にすれば良いです。
targetm.hard_regno_mode_ok() のRISC-V向け実装
// gcc/config/riscv/riscv.c
/* Implement TARGET_HARD_REGNO_MODE_OK. */
static bool
riscv_hard_regno_mode_ok (unsigned int regno, machine_mode mode)
{
unsigned int nregs = riscv_hard_regno_nregs (regno, mode);
if (GP_REG_P (regno))
{
if (!GP_REG_P (regno + nregs - 1))
return false;
}
else if (FP_REG_P (regno))
{
if (!FP_REG_P (regno + nregs - 1))
return false;
if (GET_MODE_CLASS (mode) != MODE_FLOAT
&& GET_MODE_CLASS (mode) != MODE_COMPLEX_FLOAT)
return false;
/* Only use callee-saved registers if a potential callee is guaranteed
to spill the requisite width. */
if (GET_MODE_UNIT_SIZE (mode) > UNITS_PER_FP_REG
|| (!call_used_or_fixed_reg_p (regno)
&& GET_MODE_UNIT_SIZE (mode) > UNITS_PER_FP_ARG))
return false;
}
else if (VP_REG_P (regno)) //★★前回足した実装
{
return true;
}
else
return false;
...
ここでベクトル系のmachine modeを直接記述(mode == V64SImodeなど)しても間違いではないと思うのですが、単純にモードがたくさんあると鬱陶しいですし、該当するモードがあとで増えたときの修正が大変です。こういうときはmachine modeのクラスが便利です。クラスってなんだったかというと、machmode.defやriscv-modes.defに書いたあれです。
machine modeクラスの定義
// gcc/machmode.def
...
/* Basic integer modes. We go up to TI in generic code (128 bits).
TImode is needed here because the some front ends now genericly
support __int128. If the front ends decide to generically support
larger types, then corresponding modes must be added here. The
name OI is reserved for a 256-bit type (needed by some back ends).
*/
//★★MODE_INTクラスになる
INT_MODE (QI, 1);
INT_MODE (HI, 2);
INT_MODE (SI, 4);
INT_MODE (DI, 8);
INT_MODE (TI, 16);
...
// gcc/config/riscv/riscv-modes.def
//★★MODE_FLOATクラスになる
FLOAT_MODE (TF, 16, ieee_quad_format);
//★★以前、追加した実装
//★★VECTOR_MODEの場合は少し特殊で、MODE_VECTOR + 最初の引数 クラスになる
//★★この例だとMODE_VECTOR_INTになる
VECTOR_MODE (INT, SI, 32);
VECTOR_MODE (INT, SI, 64);
クラスは上記の通り各所の *.defにて定義されますが、正直言ってどこにあるかわかりにくいし、クラスの名前も見えません。machine modeとクラスの対応を確認するだけなら、ビルド時に生成されるinsn-modes.cを見たほうが早いです。
machine modeとクラスの対応、早見方法
// build_gcc/insn-modes.c
const unsigned char mode_class[NUM_MACHINE_MODES] =
{
MODE_RANDOM, /* VOID */
MODE_RANDOM, /* BLK */
MODE_CC, /* CC */
MODE_INT, /* BI */
MODE_INT, /* QI */
MODE_INT, /* HI */
MODE_INT, /* SI */
MODE_INT, /* DI */
MODE_INT, /* TI */
MODE_FRACT, /* QQ */
MODE_FRACT, /* HQ */
MODE_FRACT, /* SQ */
MODE_FRACT, /* DQ */
MODE_FRACT, /* TQ */
MODE_UFRACT, /* UQQ */
MODE_UFRACT, /* UHQ */
MODE_UFRACT, /* USQ */
MODE_UFRACT, /* UDQ */
MODE_UFRACT, /* UTQ */
MODE_ACCUM, /* HA */
MODE_ACCUM, /* SA */
MODE_ACCUM, /* DA */
MODE_ACCUM, /* TA */
MODE_UACCUM, /* UHA */
MODE_UACCUM, /* USA */
MODE_UACCUM, /* UDA */
MODE_UACCUM, /* UTA */
MODE_FLOAT, /* SF */
MODE_FLOAT, /* DF */
MODE_FLOAT, /* TF */
...
MODE_COMPLEX_FLOAT, /* SC */
MODE_COMPLEX_FLOAT, /* DC */
MODE_COMPLEX_FLOAT, /* TC */
MODE_VECTOR_INT, /* V32SI */
MODE_VECTOR_INT, /* V64SI */
};
ベクトル系のmachine modeを引っ掛けるにはMODE_VECTOR_INTを使えば良さそうです。今の実装では使っていませんがRISC-Vのベクトルは浮動小数点のベクトル(MODE_VECTOR_FLOAT)も扱えるはずなので、これも条件に追加しておきましょう。
targetm.hard_regno_mode_ok() のRISC-V向け実装、修正版
// gcc/config/riscv/riscv.c
/* Implement TARGET_HARD_REGNO_MODE_OK. */
static bool
riscv_hard_regno_mode_ok (unsigned int regno, machine_mode mode)
{
unsigned int nregs = riscv_hard_regno_nregs (regno, mode);
if (GP_REG_P (regno))
{
if (!GP_REG_P (regno + nregs - 1))
return false;
}
else if (FP_REG_P (regno))
{
if (!FP_REG_P (regno + nregs - 1))
return false;
if (GET_MODE_CLASS (mode) != MODE_FLOAT
&& GET_MODE_CLASS (mode) != MODE_COMPLEX_FLOAT)
return false;
/* Only use callee-saved registers if a potential callee is guaranteed
to spill the requisite width. */
if (GET_MODE_UNIT_SIZE (mode) > UNITS_PER_FP_REG
|| (!call_used_or_fixed_reg_p (regno)
&& GET_MODE_UNIT_SIZE (mode) > UNITS_PER_FP_ARG))
return false;
}
else if (VP_REG_P (regno)) //★★前回足した実装
{
if (GET_MODE_CLASS (mode) != MODE_VECTOR_INT
&& GET_MODE_CLASS (mode) != MODE_VECTOR_FLOAT) //★★今回足した実装
return false;
return true;
}
else
return false;
...
修正後のコンパイラは浮動小数点数を60個使うコードを正常にコンパイルできます。たったこの3行を説明するだけで、えらい時間を費やしました。GCCは魔界ですね。
お気づきの方もいるかと思いますが、実は1つ上のelse if節にほぼ全く同じ判定文が既にあります。何も考えずに上からパクってMODEの名前を書き換えれば、今回の問題は直るんですけど、それだとどうして直るのか全くわからないんですよ……。
コメント一覧
- コメントはありません。
この記事にコメントする
| < | 2020 | > | ||||
| << | < | 07 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| - | - | - | 1 | 2 | 3 | 4 |
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | - |
最近のコメント20件
-
 26年1月23日
26年1月23日
すずきさん (01/29 09:48)
「おおー、そんな昔からなんですね。歴史感じ...」 -
26年1月23日
hdkさん (01/27 19:53)
「#! はUNIX v8からだったってWi...」 -
24年12月9日
すずきさん (01/18 15:45)
「Thank you for your i...」 -
24年12月9日
Up2Uさん (01/15 12:57)
「Hi I also find the p...」 -
25年12月18日
すずきさん (12/23 23:51)
「良く見たらksys_read()でfil...」 -
25年12月18日
すずきさん (12/23 23:15)
「ですね、まあpread+readだと話が...」 -
25年12月18日
hdkさん (12/21 08:34)
「昔試しにデバイスドライバーを作ったことが...」 -
25年11月28日
hdkさん (12/04 08:10)
「あれ、停止直前くらいの時のトルクコンバー...」 -
25年11月28日
すずきさん (12/03 11:24)
「トルクコンバーターがいてエンブレは掛かり...」 -
25年11月28日
hdkさん (12/02 08:02)
「"停止直前に急にエンブレがほぼゼロになる...」 -
25年10月6日
すずきさん (10/10 13:14)
「ですね。ccはもはやコンパイラというより...」 -
25年10月6日
hdkさん (10/10 08:27)
「ただのHello, worldでも試して...」 -
25年9月29日
すずきさん (10/03 00:29)
「なんと、メタパッケージ入れてなかったです...」 -
25年9月29日
hdkさん (10/02 06:51)
「あれ、dkmsは自動ビルドされるのが便利...」 -
20年8月24日
すずきさん (08/30 22:06)
「ですね、自分も今はPulseAudioを...」 -
20年8月24日
hdkさん (08/29 09:32)
「ALSA懐かしい... PulseAud...」 -
16年2月14日
すずきさん (08/04 01:31)
「お役に立ったようでしたら幸いです。」 -
16年2月14日
enc28j60さん (08/03 17:40)
「ちょうど詰まっていたところです。\n非常...」 -
25年7月20日
すずきさん (07/30 00:10)
「ギクシャクするのは減速時の2速シフトダウ...」 -
25年7月20日
hdkさん (07/29 07:38)
「2速発進でギクシャクするんですか? 面白...」
最近の記事3件
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
