2023年11月3日

Googleから探しやすくしたい
この日記にはいくつかヘッダ(Hxタグ)を使っており、文書の構造は下記のようにしています。
- H1: タイトル
- H2: 不使用(昔は使っていたけどデザイン変更でなくなった)
- H3: 日記の日付
- H4: 日記内のトピック
しかしどうもGoogleさんはH4タグを拾わないときがあるようで、
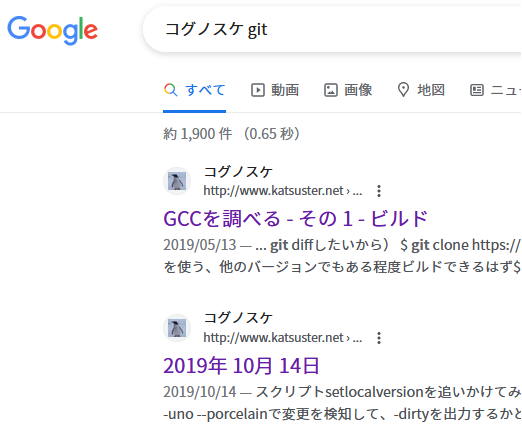
こんな風に日付だけが出て、内容が良くわからなくなってしまうことがあります。試しに日記内のトピックを格上げし、日記の日付と同格のH3にして検索結果がどうなるか観察しようと思います。
日付を消すことも少し考えましたが、とりあえず今のままにしておきます。テキスト環境のブラウザで見るときにも日付があると結構見やすいですし(日記の切れ目が分かりやすい……気がする)。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2023年11月6日
yesの高速化(パイプ限定)
目次: ベンチマーク
FizzBuzzを作っていて気づきましたが、vmsplice()を使うとメチャクチャ速いyesコマンドを実装できます。
昔に紹介した通り(2017年6月14日の日記参照)GNU yes 8.26近辺から出力がとても速くなっています。あとで分析しますがwrite()を使ったときの最速と思われる速度が出ますが、出力先をパイプに限定して良ければvmsplice()を使うことでさらに速くできます。
vmsplice()で端末に出力するとEBADFエラーになる
$ ./yes vmsplice: Bad file descriptor
ちなみに今回紹介する高速化の手法であるvmsplice()はパイプ以外、例えば端末に出そうとするとエラーになりますから、汎用的なyesコマンドの実装としては使えません。状況に制限を掛けてまで高速なyesが欲しい場合が果たしてあるだろうか?と言われると、うーん、すぐには思いつかないですね……。ベンチマークには役に立ちますけども。
レギュレーションとテスト
本来のyesコマンドの仕様は「引数で受け取った文字列と改行を無限に出力する」ですが、ベンチマークの都合上どこか一定の場所で終わってほしいので、適当に0x2ffffffff行(128億行)くらい出力したら終わりとします。行数は多少増減しても気にしないことにします。デフォルトでは1行2バイト('y'と改行)なので出力するデータ量の合計は24GBくらいになります。
内容的には難しくないので不要な気もしますが、正常動作を確かめるテストプログラムを作ります。基本的に延々と同じ内容の行が出力されるだけなので、全て見なくても0x0fff_ffff(2億行)も見れば十分でしょう。たぶん。
yesのテストプログラム
// 20231106_test_yes.c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(int argc, char *argv[])
{
const char *ex;
char expected[256];
char *inbufp = NULL;
size_t insz = 0;
if (argc < 2) {
ex = "y";
} else {
ex = argv[1];
}
snprintf(expected, sizeof(expected), "%s\n", ex);
for (unsigned int i = 1; i < 0xfffffff; i++) {
getline(&inbufp, &insz, stdin);
if ((i & 0xffffff) == 0) {
printf("\r%u ", i);
fflush(stdout);
}
if (strcmp(expected, inbufp) != 0) {
printf("\n");
printf("Not matched in %u\n", i);
printf(" expected: %s\n", expected);
printf(" input : %s\n", inbufp);
return 1;
}
}
printf("\nOK\n");
return 0;
}
本物のyesをテストしてみてfailしないか確かめます。
テストのテスト
$ yes | ./test_yes 251658240 OK $ yes aaaaaaaa | ./test_yes aaaaaaaa 251658240 OK ### 引数の指定が効いているか確かめる $ yes | ./test_yes aaaaaaaa Not matched in 1 expected: aaaaaaaa input : y $ yes aaaaaaaa | ./test_yes Not matched in 1 expected: y input : aaaaaaaa
良さそうですね。あとは測定環境です。省電力PCの測定環境は、
- Intel Pentium J4205/1.5GHz
- DDR3L-1600 8GB x 2
- Linux kernel 6.1.52
- GCC 12.2.0 (Debian 12.2.0-14)
- glibc 2.36 (Debian 2.36-9+deb12u1)
デスクトップPCの測定環境は、
- AMD Ryzen 7 5700X
- DDR4-3200 32GB x 2
- Linux kernel 6.4.13 (Debian 6.4.13-1)
- GCC 13.2.0 (Debian 12.2.0-14)
- glibc 2.37 (Debian 2.37-7)
準備完了です。ではいってみよう。
単純なyes
最初はprintf()で普通に実装しましょう。
単純なyes
// 20231106_yes_simple.c
#include <stdint.h>
#include <stdio.h>
int main(int argc, char *argv[])
{
const char *arg;
if (argc < 2) {
arg = "y";
} else {
arg = argv[1];
}
for (uint64_t i = 0; i < 0x2ffffffff; i++) {
printf("%s\n", arg);
}
return 0;
}
単純なyesの速度
$ gcc 20231106_yes_simple.c -msse4 -O3 24.0GiB 0:08:31 [48.1MiB/s] [ <=> ] real 8m31.031s user 8m26.537s sys 0m36.512s
一度のprintf()で2バイトしか出力しないので、メチャクチャ遅いですね。
バッファリング版yes
次はwrite()とバッファリングを使います。アイデアは単純で、適当な大きさのバッファに出力する文字を詰められるだけ詰めて、バッファをwrite()に渡して複数行を一気に出力する方法です。本来の処理では不要ですが、ベンチマークのため一度に何行出力しているか覚えておく必要があります。
バッファリング版yes
// 20231106_yes_buf.c
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#define CHUNKSIZE (4096 * 2)
char output[CHUNKSIZE] __attribute__((aligned(4096)));
int main(int argc, char *argv[])
{
const char *arg;
char out_one[256];
size_t len_one, len = 0;
int d = 0;
if (argc < 2) {
arg = "y";
} else {
arg = argv[1];
}
len_one = snprintf(out_one, sizeof(out_one), "%s\n", arg);
while (len + len_one < sizeof(output) - 1) {
strcat(output, out_one);
len += len_one;
d++;
}
for (uint64_t i = 0; i < 0x2ffffffff - 1; i += d) {
write(1, output, len);
}
return 0;
}
バッファリング版yesの速度
$ gcc 20231106_yes_buf.c -msse4 -O3 24.0GiB 0:00:11 [2.16GiB/s] [ <=> ] real 0m11.095s user 0m1.564s sys 0m20.571s (参考 GNU yesの速度) $ yes --version yes (GNU coreutils) 9.1 (以下略) $ time taskset 0x1 yes | taskset 0x4 pv > /dev/null 24.2GiB 0:00:11 [2.23GiB/s] [ <=> ] ^C real 0m11.600s user 0m1.528s sys 0m21.621s
一気に速くなりました。GNU yesの速度も参考に載せましたが、ほぼ同じ速度です。これがwrite()で出力するときの限界速度でしょう。
vmsplice版yes
最後はvmsplice()です。基本的なアイデアはバッファリング版yesと同じです。ただしvmsplice()に対応するために、ダブルバッファリングとバッファ終端からはみ出た場合の処理を追加します。
vmsplice版yes
// 20231106_yes_vmsplice.c
#define _GNU_SOURCE
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <fcntl.h>
#include <sys/uio.h>
#define CHUNKSIZE (4096 * 64)
char buf2[2][CHUNKSIZE + 4096] __attribute__((aligned(4096)));
int f __attribute__((aligned(8)));
char output[2048] __attribute__((aligned(4096)));
static void vwrite(int fd, void *buf, size_t count)
{
struct iovec iov;
ssize_t n;
iov.iov_base = buf;
iov.iov_len = count;
while (iov.iov_len > 0) {
n = vmsplice(1, &iov, 1, 0);
if (n < 0) {
perror("vmsplice");
exit(1);
}
iov.iov_base += n;
iov.iov_len -= n;
}
}
int main(int argc, char *argv[])
{
const char *arg;
char out_one[256];
char *p = buf2[f];
size_t len_one, len = 0;
int d = 0;
fcntl(1, F_SETPIPE_SZ, CHUNKSIZE);
if (argc < 2) {
arg = "y";
} else {
arg = argv[1];
}
len_one = snprintf(out_one, sizeof(out_one), "%s\n", arg);
while (len + len_one < sizeof(output) - 1) {
strcat(output, out_one);
len += len_one;
d++;
}
for (uint64_t i = 0; i < 0x2ffffffff - 1; i += d) {
memcpy(p, output, len);
p += len;
int n = p - buf2[f] - CHUNKSIZE;
if (n >= 0) {
vwrite(1, buf2[f], CHUNKSIZE);
f = !f;
memcpy(buf2[f], &buf2[!f][CHUNKSIZE], n);
p = &buf2[f][n];
}
}
return 0;
}
vmsplice版yesの速度
$ gcc 20231106_yes_vmsplice.c -msse4 -O3 24.0GiB 0:00:03 [7.14GiB/s] [ <=> ] real 0m3.367s user 0m1.849s sys 0m3.297s
予想はしていましたがメチャクチャ速くなりました……。vmsplice()恐るべし。
Ryzen 7での測定結果
$ gcc 20231106_yes_simple.c -msse4 -O3 24.0GiB 0:01:54 [ 213MiB/s] [ <=> ] real 1m54.938s user 1m52.312s sys 0m22.559s $ gcc 20231106_yes_buf.c -msse4 -O3 24.0GiB 0:00:05 [4.49GiB/s] [ <=> ] real 0m5.347s user 0m0.912s sys 0m9.776s $ gcc 20231106_yes_vmsplice.c -msse4 -O3 24.0GiB 0:00:00 [33.7GiB/s] [<=> ] real 0m0.715s user 0m0.508s sys 0m0.721s
PentiumとRyzen 7の測定結果、どの程度速くなったかを合わせて表にすると、
| FizzBuzzの種類 | Pentium, GCC -O3 | 倍率 | Ryzen 7, GCC -O3 | 倍率 |
|---|---|---|---|---|
| 単純 | 511.031 | - | 114.938 | - |
| バッファリング | 11.600 | x44.0 | 5.347 | x21.5 |
| vmsplice | 3.367 | x151.8 | 0.715 | x160.7 |
使える場所が限定されるとはいえ素晴らしい効き目ですね。ちなみにRyzen 7はバッファサイズを4倍(1MB x 2)にするとさらに速くなって、0.612秒(39.4GiB/s、187.8倍)くらいになります。まさか1秒も掛からないとは思わなんだ……。
ソースコード
ソースコードはこちらからどうぞ。
 テストプログラム
テストプログラムコメント一覧
- コメントはありません。
この記事にコメントする
2023年11月10日
Zephyr RISC-V向けのマルチコアブートを修正
目次: Zephyr
Zephyr RTOSのRISC-V向けマルチコアブート処理がバグっていて修正したので解析したメモを残しておきます。
ZephyrではCONFIG_RV_BOOT_HARTというコンフィグで設定したhartidと、mhartid CSRの値が一致するhartがメインの初期化を担当します。Zephyrのコードではfirst coreと呼び、メイン以外はsecondary coreと呼んでいます。あまり聞いたことがない呼び方ですね。この日記では素直にメインコア/サブコアと書きます。
メインコアはarch_start_cpu()という関数からサブコアを起床します。呼び出しの経路は下記です。
メインコアのブート処理の呼び出し経路
z_thread_entry()
bg_thread_main()
z_smp_init()
arch_start_cpu()
このbg_thread_main()関数はメインスレッド実行前に必要な初期化を実施していて、最終的にmain()を呼び出します。実行タイミングはカーネルの初期化が終わって、メインスレッドにコンテキストスイッチしたあとです。ブートからそれなりに時間が経過しています。
メインコアのブート処理
// zephyr/arch/riscv/core/smp.c
void arch_start_cpu(int cpu_num, k_thread_stack_t *stack, int sz,
arch_cpustart_t fn, void *arg)
{
riscv_cpu_init[cpu_num].fn = fn;
riscv_cpu_init[cpu_num].arg = arg;
riscv_cpu_sp = Z_KERNEL_STACK_BUFFER(stack) + sz;
riscv_cpu_wake_flag = _kernel.cpus[cpu_num].arch.hartid; //★★1-1: riscv_cpu_wake_flagに起床させるhartidを設定する★★
#ifdef CONFIG_PM_CPU_OPS
if (pm_cpu_on(cpu_num, (uintptr_t)&__start)) {
printk("Failed to boot secondary CPU %d\n", cpu_num);
return;
}
#endif
//★★1-2: riscv_cpu_wake_flagが0になるまで待つ★★
while (riscv_cpu_wake_flag != 0U) {
;
}
//★★1-3: riscv_cpu_wake_flagが0になったら継続★★
}
サブコアは下記のようにブート直後にフラグチェックし、起動の指示があるまで待っています。
サブコアのブート処理
// zephyr/arch/riscv/core/reset.S
SECTION_FUNC(TEXT, __initialize)
csrr a0, mhartid //★★a0 <- mhartid★★
li t0, CONFIG_RV_BOOT_HART
beq a0, t0, boot_first_core
j boot_secondary_core
//...
boot_secondary_core:
#if CONFIG_MP_MAX_NUM_CPUS > 1
//★★2-1: riscv_cpu_wake_flagがmhartidになるまで待つ★★★
la t0, riscv_cpu_wake_flag
lr t0, 0(t0)
bne a0, t0, boot_secondary_core
//★★2-2: riscv_cpu_wake_flagがmhartidになったら継続する★★★
/* Set up stack */
la t0, riscv_cpu_sp
lr sp, 0(t0)
la t0, riscv_cpu_wake_flag
sr zero, 0(t0) //★★2-3: riscv_cpu_wake_flagに0をセット★★
j z_riscv_secondary_cpu_init
コードの想定する動作は下記の通りです。例としてhart0がメイン、hart1がサブの2コアのブートとします。
- hart1: 2-1: riscv_cpu_wake_flag == mhartid (= 1)になるまで待つ
- hart0: 1-1: riscv_cpu_wake_flagに起床させるhartid = 1を設定する(arch_start_cpu()関数)
- hart0: 1-2: riscv_cpu_wake_flag == 0になるまで待つ
- hart1: 2-2: riscv_cpu_wake_flag == mhartid (= 1)になったので継続
- hart1: 2-3: riscv_cpu_wake_flagを0にセットする
- hart0: 1-3: riscv_cpu_wake_flag == 0になったので継続
このときriscv_cpu_wake_flagの初期値はいずれのサブコアのmhartidとも一致しないのが期待値です。
問題点
このコードはriscv_cpu_wake_flagの初期値がいずれかのサブコアのmhartidと一致するとハングアップします。riscv_cpu_wake_flagはBSS領域に配置されておりメインコアがいずれ0に初期化しますが、サブコアはメインコアがBSS領域を初期化する前にriscv_cpu_wake_flagを参照するので間に合いません。
例えば起動直後にriscv_cpu_wake_flagが偶然1だったとすると下記のような動きをしてハングアップします。
- hart1: 2-1: riscv_cpu_wake_flag == mhartid (= 1)になるまで待つ
- hart1: 2-2: riscv_cpu_wake_flag == mhartid (= 1)なので継続
- hart1: 2-3: riscv_cpu_wake_flagを0にセットする
- hart0: 1-1: riscv_cpu_wake_flagに起床させるhartid = 1を設定する(arch_start_cpu()関数)
- hart0: 1-2: riscv_cpu_wake_flag == 0になるまで待つ
- hart0: 誰もriscv_cpu_wake_flagを0に戻さないのでハングアップ
この実装をどう変更したら良くなるのか?なぜか?については少々長くなるので、以前の日記(2021年9月28日の日記参照)をご覧ください。
対策
サブコアを起こすフラグriscv_cpu_wake_flag(初期値は-1)とサブコアが起きたことを示すフラグriscv_cpu_boot_flag(初期値は0)に分けます。riscv_cpu_wake_flagはサブコアから-1に初期化してから起動待ちに入るようにして、不定値問題に対処します。
Zephyr RTOSのプロジェクトにPull Requestを送ったところあっさり取り込まれました(Zephyrへのリンク)。1週間以上は掛かるかと思っていましたが、早かったです。今は修正に向いている時期なんでしょうか。
とまあ、ここまで書いていて対策後のコードも間違っているような気がしてきました。
メインコアがhart0じゃない場合、BSS領域の初期化でriscv_cpu_wake_flagが0に変わってしまうので、hart0が間違って起動するのではなかろうか……?それは良くないな、後で確かめようと思います。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年11月13日
ソフトバンクの料金
目次: プロバイダ
ドコモからソフトバンクに乗り換えて2か月ほど経ちました。2人暮らしで携帯2台+光回線1回線の総支払額は8,916円です。
以前は15,000円近かったから、だいぶお安くなったと思います。今まで高かった理由が「奥さんの携帯をiPhone初期のクソ高プランのまま放置してたから」なので、最近のお得系プランであればソフトバンクでもauでもなんでも良かったのかも。
ざっくり計算だとahamo x2台+ドコモ光Aプラン(2,970円 x2 + 4,300円 = 10,240円かな?)からの移行だとしても、それなりに嬉しいお値段になっているようです。まあその辺は当然考えられていますよね。
携帯電話回線
Y!mobileは安いです(光とのセット割で1,900円+税)1人2,100円くらいですね。初期のiPhoneのデータ通信価格(月額5,000円以上だったはず)と比べると格段に安いです。ahamoと比較しても数百円安くてありがたいですね。
通信の品質は値段相応の品質です。一番気になる点というと、大規模な駅など人口密集地に移動したときデータ通信が急激に遅くなったり止まったりすることです。不都合というほどではないけれど、露骨に遅くなるor止まるので気になります。
光回線
ソフトバンク光の料金はドコモ光と比べて400円くらい上がって(月額3,800+500円+税 = 4,730円、ドコモ光は4,300円)います。
単体で見ると損ですが、携帯回線とのセット割が1,000円くらいなので取り返せる仕組みです。通信会社ってのはなんでこう複雑で理解しにくい制度を考えるんでしょうね。昔からの悪癖ですね……。
通信の品質は特に変わった印象はありません。たぶん。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年11月21日
musl libcのアトミックCAS実装
目次: C言語とlibc
OSSのlibc実装の一つであるmusl libcのアトミックCAS(Compare And Swap)の実装を調べたメモです。CASはa_cas(p, t, s)関数に実装されていて、ポインタpの指す先の値がtなら、アトミックにsと入れ替える関数です。調べるのはRISC-V用の実装です。
コンパイラが提供するアトミック関数実装(stdatomic.h)は使わないみたいです。musl libc独自の実装となっています。
musl libcのアトミックCAS実装
// musl/arch/riscv64/atomic_arch.h
#define a_cas a_cas
static inline int a_cas(volatile int *p, int t, int s)
{
int old, tmp;
__asm__ __volatile__ (
"\n1: lr.w.aqrl %0, (%2)\n"
" bne %0, %3, 1f\n"
" sc.w.aqrl %1, %4, (%2)\n"
" bnez %1, 1b\n"
"1:"
: "=&r"(old), "=&r"(tmp)
: "r"(p), "r"((long)t), "r"((long)s)
: "memory");
return old;
}
RISC-V向けの実装はLR/SC(Load and Reserve, Store Conditional)という仕組みを使い実装されています。RISC-V以外のアーキテクチャでも良く見かける機能で、見たことある方も多いと思います。LRはLL(Load Link)という名前のこともあるようです。
コードはたった4行です、1行ずついきましょう。
- 1行目: pの指す先を予約付きロードします。ロードした値は変数oldに格納されます。
- 2行目: ロードした値がtでなければ終了します。
- 3行目: ロードした値がtならばpの指す先にsを条件付きストアします。
- 4行目: 条件付きストアが成功したら終了、失敗したら1行目に戻ります。
条件付きストアは、予約付きロードから条件付きストア間にpの指す先を誰も変更していない場合のみストアが成功します。pの指す先の値がsに変化します(tmpには0が返されます)。
もし予約付きロードから条件付きストアの間に誰かがpの指す先を変更していた場合はストアが失敗します。pの指す先の値は変化しません(tmpには0以外の値が返されます)。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年11月24日
Linux JMプロジェクトとOSDNの崩壊
目次: Linux
OSDNがOSCHINAに売却された(「OSDN」が中国企業に買収〜日本のオープンソースプロジェクトホスティングサービス - 窓の杜)影響か、最近OSDNのWWWサーバーが応答しなくなりました。人によっては「ふーん、そうなん」で終わりですが、私は非常に困ることが1点あります。Linux JMが見えなくなったことです。
Linux JMとはLinuxのman(マニュアル、英語)を日本語訳して公開してくれている超ありがたいプロジェクトです。man形式だけでなくHTML形式も作成していて、同プロジェクトのサイトにて公開されています……いました。Linux JMおよび同サイトがOSDNでホスティングされているため、今回の騒動で見えなくなってしまいました。
私はmanpage + API名という雑な検索をしても、ほぼ一番最初に出てくるLinux JMを大変重宝しておりました。これが使えなくなるのは辛いよー……。
ソースコードリポジトリは公開されていますので、泣き言を言う暇があったら自分でHTMLに変換すれば良かろうって?全く持っておっしゃるとおりですね。やりましょう。
Linux JMプロジェクトのリポジトリ
リポジトリのアドレスはgit://git.osdn.net/gitroot/linuxjm/jm.gitです。OSDNのシステムをよく知りませんが、GitHubなどとは異なりHTTPSでcloneできるサーバーはなさそうな気配です。リポジトリは他に3つ存在しますが、いずれも過去の履歴を保持するために残されたリポジトリです。READMEファイル以外は何も入っていません。
- git://git.osdn.net/gitroot/linuxjm/LDP_man-pages.git
- git://git.osdn.net/gitroot/linuxjm/coreutils.git
- git://git.osdn.net/gitroot/linuxjm/iptables.git
今回はこれらは使いませんので、リポジトリのアドレスを紹介するだけに留めます。
Linux JMプロジェクトのビルド
ビルドというほど大げさでもないですけど。apt-getなどでman2htmlをインストールした後に、下記を実行します。
Linux JMのビルド方法(HTMLファイルのみ)
$ git clone git://git.osdn.net/gitroot/linuxjm/jm.git $ cd jm $ make JMHOME=`pwd`/result MAN2HTML=/usr/bin/man2html html
成功するとJMHOMEで指定したディレクトリの下(result/htdocs/html)にHTMLファイルの入ったディレクトリが生成されます。この日記のサイトから読めるようにしておきます(一覧へのリンク)。右側のコンテンツメニューからも辿れるようにしました。
HTMLファイルだけでもマニュアルとしては十分ですが、白黒で目が痛いしデザインがそっけないです。デザインを変更するにはhtmlディレクトリと同列にjm.cssというファイルを置くと良いみたいです。リポジトリのwwwディレクトリ以下にある*.cssファイルを使うのが手っ取り早いでしょう。
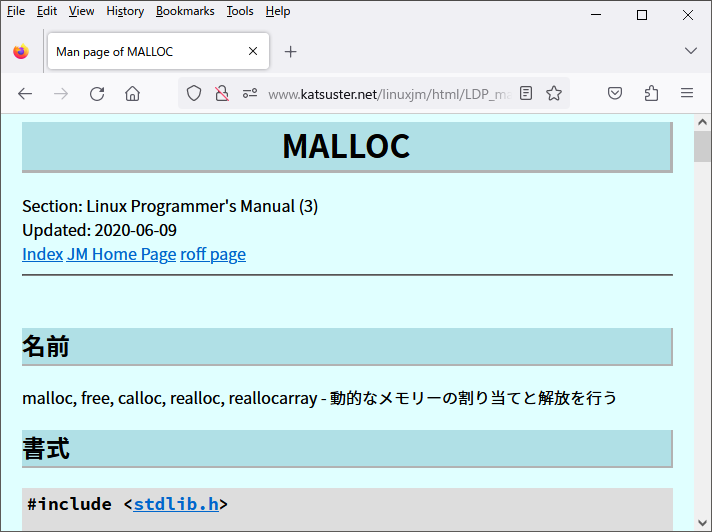
いつもの見慣れたデザインになりました。黄色いデザインのイメージでしたが、デフォルトは青いみたいです。知りませんでした……。
一覧を見る方法
HTMLファイルが生成されたディレクトリを見ると、ツールの名前がついたディレクトリが延々と並んでいます。JavaDocのようなIndex HTMLを出力する機能はなさそうです。
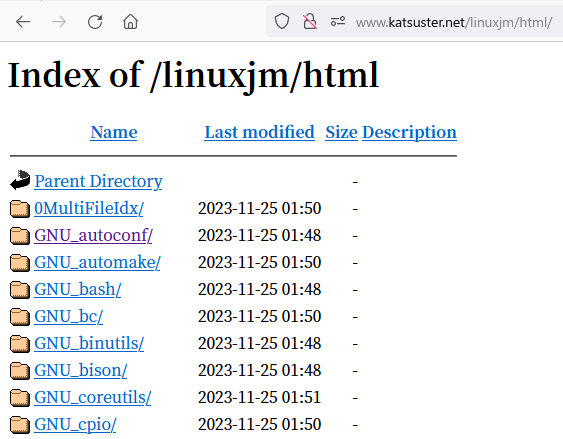
とはいえさほど複雑な構造でもありませんし、わざわざ作らずともApacheのIndexes機能を開放するだけで十分でしょう。
検索が悩ましい
配置したLinux JMはとりあえず正常に読めるようになりました。Indexesも出せるようにしました。残る問題はGoogleが検索結果に出してくれるかどうかで、使い勝手という意味では割と大きい要素です。最初に紹介したように、私はmanpage + API名で検索してLinux JMが一番上に出る使い方に慣れきった軟弱者なので……他の文字を打たないと出ないなら使いにくいんです。
Googleはそのうちクロールしてくれると思うので、しばらく放置しようと思います。検索できるようになっても検索順位が低すぎるとか、どうにも使いにくかったらまた何か考えます。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年11月25日
JTSA Limited大会参加2023
目次: 射的
JTSA Limitedの大会に参加しました。いつも使っているエアガンであるベレッタ92(東京マルイ、US M9)が大会の朝に壊れてしまい、急遽グロック17(東京マルイ、GLOCK 17 Gen.4)で参加するというトラブル付きです。にも関わらず、記録は絶好調で76.68秒の自己ベストが出ました(総合105位/135人、LM 24位/37人)。えー。
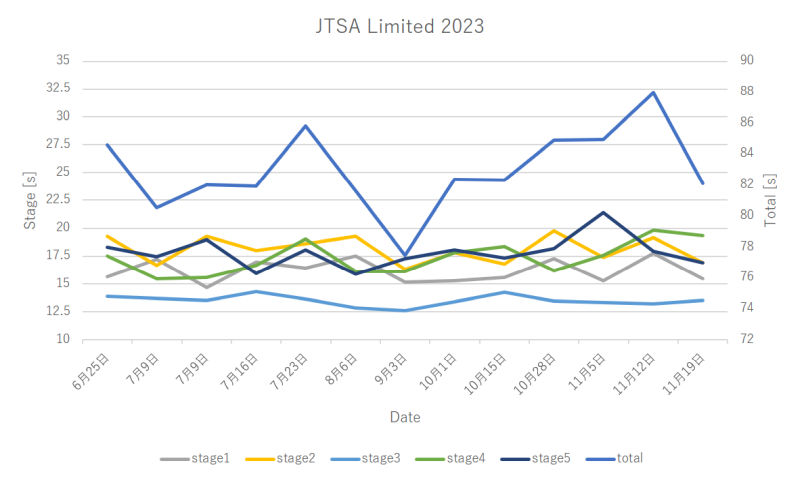
ダブルアクションのベレッタ92とシングルアクションのグロック17を比べれば、後者が有利なのはわかりますが、練習会で一度も出たことがない好タイムが大会本番の一発勝負で出るのはどういうことなんだ。うーん、普段の練習の意味とは一体……良い記録が出ただけに複雑な気分です……。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年11月28日
glibcのclone_threadが使うシステムコール
目次: C言語とlibc
RISC-V向けglibcの実装を眺めていたところ、2.37と2.38でスレッドを作成する関数(__clone_internal関数)が使っているシステムコールが変わっていることに気づきました。
スレッドを作成するcloneシステムコールにはいくつか亜種がありますが、大抵のアーキテクチャではcloneとclone3が実装されています。cloneは引数を値で渡します。clone3は構造体へのポインタと構造体のサイズを渡します。cloneの引数は非常に多く、しかも昔より増えているような気がします……。今後の拡張も考えれば引数の個数に制限がある値渡しよりも、構造体のポインタを渡したほうが合理的ですね。
実装は全アーキテクチャ共通で、下記のような感じです。struct clone_argsがclone3に渡す構造体です。__clone3_internal()はcl_argsを直接clone3システムコールに渡します。__clone_internal_fallback()はcl_argsの各フィールドをバラバラにしてcloneシステムコールに渡します。
glibc-2.38のcloneの実装
// glibc/sysdeps/unix/sysv/linux/clone-internal.c
int
__clone_internal (struct clone_args *cl_args,
int (*func) (void *arg), void *arg)
{
#ifdef HAVE_CLONE3_WRAPPER
int saved_errno = errno;
int ret = __clone3_internal (cl_args, func, arg); //★★SYS_clone3を呼ぶ
if (ret != -1 || errno != ENOSYS)
return ret;
/* NB: Restore errno since errno may be checked against non-zero
return value. */
__set_errno (saved_errno);
#endif
return __clone_internal_fallback (cl_args, func, arg); //★★SYS_cloneを呼ぶ
}
これまで(2.37まで)のglibcのRISC-V向け実装でclone3システムコールが使われていなかった理由は、有効/無効のスイッチが無効側に設定されていたからです。スイッチとなるマクロ定義はsysdep.hというヘッダにあります。
clone3を使うか使わないかのスイッチ(RISC-V向け)
// glibc/sysdeps/unix/sysv/linux/riscv/sysdep.h
# define HAVE_CLONE3_WRAPPER 1
2.37まではHAVE_CLONE3_WRAPPERが未定義で、2.38ではHAVE_CLONE3_WRAPPERの定義が追加されました。以上が__clone_internal()が使っているシステムコールが変わる仕組みでした。良くできてます。
コメント一覧
- コメントはありません。
この記事にコメントする
2023年11月29日
newlib-4.3.0 for RISC-V 32bitのバグ
RISC-V用のツールチェーンを更新しているときに気づいたバグです。
現在の時刻を取得するgettimeofday()というAPIがあります。newlib-4.1.0ではSYS_gettimeofdayを使っていましたが、newlib-4.3.0ではSYS_clock_gettime64を使うように変更されました。が、これがバグっていました。
newlib-4.3.0のgettimeofday()の実装
// newlib-cygwin/libgloss/riscv/sys_gettimeofday.c
/* Get the current time. Only relatively correct. */
int
_gettimeofday(struct timeval *tp, void *tzp)
{
#if __riscv_xlen == 32
struct __timespec64
{
int64_t tv_sec; /* Seconds */
# if BYTE_ORDER == BIG_ENDIAN
int32_t __padding; /* Padding */
int32_t tv_nsec; /* Nanoseconds */
# else
int32_t tv_nsec; /* Nanoseconds */
int32_t __padding; /* Padding */
# endif
};
struct __timespec64 ts64;
int rv;
rv = syscall_errno (SYS_clock_gettime64, 2, 0, (long)&ts64, 0, 0, 0, 0);
tp->tv_sec = ts64.tv_sec;
tp->tv_usec = ts64.tv_nsec * 1000; //★★計算式を間違えている、* 1000ではなく / 1000が正しい★★
return rv;
#else
return syscall_errno (SYS_gettimeofday, 1, tp, 0, 0, 0, 0, 0);
#endif
}
見ての通り、gettimeofdayは結果を秒(tv_sec)とマイクロ秒(tv_usec)のペアで返します。clock_gettime64は秒とナノ秒で結果を返してきますので、ナノ秒→マイクロ秒へ変換する必要があります。しかし悲しいことにナノ秒→マイクロ秒の変換コードがバグっており、マイクロ秒の値がかなり大きな値(本来1usなのに1msになってしまう(訂正: 1nsなのに1msになってしまう))になってしまいます。
長らく放置され、今日直っていた
実装変更がnewlibに入ったのは約2年前(2021年4月13日、commit id: 20d008199)でした。結構時間が経っていますね。先ほど紹介したgettimeofdayの実装はRISC-V 32bit向けの時しか使わないので、他のアーキを使っている開発者の皆様がバグに気づかなかったのだろうと思われます。
バグったコミット
commit 20d00819984058e439cfe40818f81d7315c89201
Author: Kito Cheng <kito.cheng@sifive.com>
Date: Tue Apr 13 17:33:03 2021 +0800
RISC-V: Using SYS_clock_gettime64 for rv32 libgloss.
- RISC-V 32 bits linux/glibc didn't provide gettimeofday anymore
after upstream, because RV32 didn't have backward compatible issue,
so RV32 only support 64 bits time related system call.
- So using clock_gettime64 call instead for rv32 libgloss.
このバグは既に下記のコミットで修正されています。
バグが修正されたコミット
commit 5f15d7c5817b07a6b18cbab17342c95cb7b42be4
Author: Kuan-Wei Chiu <visitorckw@gmail.com>
Date: Wed Nov 29 11:57:14 2023 +0800
RISC-V: Fix timeval conversion in _gettimeofday()
Replace multiplication with division for microseconds calculation from
nanoseconds in _gettimeofday function.
Signed-off-by: Kuan-Wei Chiu <visitorckw@gmail.com>
コミットの日付を見てびっくりしたのですが、なんと今日のコミットです。きっと世界のどこかで私と同じようなことを調べ、なんじゃこりゃー?!とバグを見つけて直した人が居たんでしょう。やー、奇遇ですね……。
コメント一覧
- 大山恵弘さん(2023/12/02 18:53)
すずきさんのX(旧Twitter)へのポストを見て気づいた可能性もあるかもしれないと思っています.
私はOSの時間管理に興味があるので時々gettimeofdayでエゴサーチをかけますが,そのエゴサーチで私はすずきさんのこのポストに気づきました.
そして,これはすごいバグがみつかったと思っていたところでした.
今回のfixを施したのは日本語を理解しない人かもしれませんが,当該ポストの画像を見れば何がまずいかはどの国の人にも一目瞭然だと思います.
- すずきさん(2023/12/03 00:35)
大山先生、お久しぶりです。コメントありがとうございます。
gettimeofdayでエゴサーチ……!!さすがです、私はやったことがありませんでした。
私がバグに気づいてnewlibのリポジトリをチェックしたとき、既に修正されていたので、本当にほぼ同時に気づいた(向こうの方が修正&ML投稿の時間分だけ早いですが)のだろうと思います。偶然ってすごいです。 - hdkさん(2023/12/03 18:49)
>(本来1usなのに1msになってしまう)
1 nsが1 msになる、ですかね。本来の値の範囲を大幅に超えて桁溢れもおこしてしまいそうなバグですね... - すずきさん(2023/12/04 00:38)
あ、そうか。1nsですね。ありがとうございます。
この記事にコメントする
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報