2021年9月4日

Zephyr on HiFive Unmatched/HiFive Unleashed
目次: Zephyr
ZephyrのHiFive UnmatchedとHiFive Unleashedへのポーティングが本家のmainにマージ(※)されました。2.7.0のマージウインドウが終わるまで、メンテナーチームは忙しそうだったので、もうしばらく放置かな?と思っていましたが、昨日突然マージされました。
これは以前トライしていたZephyrのHiFive Unleashedへの移植(2021年6月6日の日記参照)に加え、HiFive Unmatchedへの移植(2021年8月20日の日記参照)も追加したものです。RISC-Vはメンテナーが少ないこともあって割と放置気味になりがちなんですよね……。
ポーティングといっても、最低限の設定+とりあえず起動するだけで、ほぼ何にも使えない(UARTとSPIくらいしか動きません)から、まだまだこれからだな。うん。
(※)最近はmasterという単語はダメだねってことで、既存のリポジトリもmaster → mainに置き換えられたプロジェクトが増えてます。
メモ: 技術系の話はFacebookから転記しておくことにした。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2021年9月5日
ゲーム用のPCを作りたいが、高い
目次: ゲーム
普段PCで何か作業する場合WindowsのノートPCを使っていて、マイコンボードでの実験や開発はLinuxのデスクトップPCにリモートアクセスして行っています。通常の作業には申し分ない性能と使い勝手が実現できています。
が、ゲームとなると話がやや違ってきます。ゲームは大抵Windowsを要求してくるので、我が家の唯一のWindows PCであるノートPCで遊ぶしかないんですけども、最近の3Dを多用したゲームは重すぎて、そのうちGPUが燃える(物理的に)んじゃないかと心配になってきます。
GPUが高すぎる
しばらく前に在宅勤務環境を整えた(2021年2月12日の日記参照)こともあり、机近辺に新たなPCを置けそうな場所ができました。Windowsをインストールしたゲーム用PCを新たに作りたいところですが、最近はあまりにもGPUが高すぎて購入に踏み切れません……。
いわゆるミドルエンドと呼ばれるTDP 200W以下(※)クラスは、今だとRadeon RX 6600 XTもしくはGeForce RTX 3060辺りだと思うんですが、Radeonはそもそも売り切れていて手に入りませんし、RTX 3060はお値段が6万円オーバーとあまりにも高すぎます。
GPUの値段はまだまだ下がらないようですし、諦めて買うしかないんですかねえ?
(※)補助電源8pin x 1くらいのカードをイメージしてます。GPUに供給可能な電力はPCIeカードエッジ(75W)+ 補助電源8pin x 1(150W)= Max 225Wです。
コメント一覧
- コメントはありません。
この記事にコメントする
2021年9月10日
C言語の標準的な標準ではない機能
目次: C言語とlibc
C言語のmath.hヘッダには、円周率πを表すマクロM_PIが定義されています。しかしこのマクロ、コンパイラに -std=c99やc11を指定すると使えなくなるんですね。C言語通には常識かもしれませんが、個人的にハマったのでメモしておきます。
M_PIを使ったプログラム
#include <math.h>
int main(void)
{
return M_PI;
}
C99としてコンパイルするとM_PIは宣言されていないと言われる
$ gcc -Wall -std=c99 a.c
a.c: In function ‘main’:
a.c:5:9: error: ‘M_PI’ undeclared (first use in this function)
5 | return M_PI;
| ^~~~
a.c:5:9: note: each undeclared identifier is reported only once for each function it appears in
もしc99やc11でもM_PIを使いたい場合は、math.hをインクルードする前に_DEFAULT_SOURCE(_GNU_SOURCEでも良いです)をdefineすると使えるようになります。
M_PIを使ったプログラム、C99でも動く版
#define _DEFAULT_SOURCE
#include <math.h>
int main(void)
{
return M_PI;
}
使えるようになりました。
コメント一覧
- コメントはありません。
この記事にコメントする
2021年9月13日
Zephyrのコンテキストスイッチ
目次: Zephyr
RISC-V向けZephyrの新しいコンテキストスイッチ(CONFIG_USE_SWITCH=y)を実装しているのですが、浮動小数点演算つまりFPUを使うスレッドを生成するとハングします。調べてみると、私が実装している場所の外にある、新しいコンテキストスイッチ(zephyr/kernel/include/kswap.hのdo_swap() 関数)の実装が今まで(CONFIG_USE_SWITCH=n)と違うように見えます。まだ確証はないですけど。
従来の処理arch_swap() では、現在のスレッド(_kernel.current)がコンテキストスイッチ(arch_swap() 内のシステムコール)の内部で旧 → 新に置き換えます。つまりcurrentは切替「前」のスレッドを指している状態でコンテキストスイッチが始まります。
ところがdo_swap() の場合、現在のスレッド(_kernel.current)がコンテキストスイッチ(arch_switch() 関数)を呼ぶ「前」に旧 → 新スレッドに置き換えます。つまりcurrentは切替「後」のスレッドを指している状態でコンテキストスイッチが始まります。
ハングに至るメカニズム
RISC-V Zephyr(他のアーキテクチャも同じかな?)ではFPU使えるスレッドと使えないスレッドを使い分けることができます。コンテキストスイッチ処理では、currentスレッドがFPUを使うか使わないかにより処理を変えています。
- FPUを使う: currentの浮動小数点レジスタをスタックに退避する処理を実行
- FPUを使わない: 退避する処理はスキップされる
私が実装したコンテキストスイッチも当然同じように実装したのですが……。先ほど説明したようにdo_swap() はcurrentを切替「後」のスレッドに設定するため、こんな悲劇が起きます。
- 旧スレッド(FPU使用不可)→ 新スレッド(FPU使用可)の明示的コンテキストスイッチを行う
- do_swap() がcurrentを新スレッド(FPU使用可)に変える
- コンテキストスイッチ
- 旧スレッド(FPU使用不可)で実行しているのに、currentは新スレッド(FPU使用可)になっている
- 浮動小数点レジスタを退避しようとして「不正命令例外」で死ぬ
原因の一端は掴めたものの、どうして他のアーキテクチャは困っていないのか?do_swap() の実装は意図的なのか?良くわかりません……。
コメント一覧
- コメントはありません。
この記事にコメントする
2021年9月16日
ワクチン2回目
前回(2021年8月26日の日記参照)同様に自治体の接種会場に行きました。ワクチンは当然同じでファイザー製です。
医療従事者のみなさま
前回同様に看護師を始めとした医療従事者の皆様は非常に親切かつ効率的に働いていました。ありがてぇ。
問診の先生はやっぱりお疲れモードな雰囲気でした。無理はしないでください……。
肩が痛い
前回はワクチンを打ってしばらく経ってから肩が痛くなりましたが、今回は打った直後から肩が痛いです。明日はどうなるんだろうか、これ……。
コメント一覧
- コメントはありません。
この記事にコメントする
2021年9月20日
RISC-Vのcmodel
目次: RISC-V
RISC-Vにはcode modelという概念があり、ざっくり言うとメモリアクセスやジャンプの際に参照するアドレスの作り方を指定します。medlowとmedanyの2つがありmedlowがデフォルトです。
詳しくはGCCのマニュアル RISC-V Options (Using the GNU Compiler Collection (GCC)) やSiFiveのエンジニアによる解説 All Aboard, Part 4: The RISC-V Code Models - SiFive を読んでいただくのが良いかと思いますが、ここではどんなときにエラーになるかに重点を置いて、いくつか例を挙げたいと思います。
medlow
モデルmedlowは32bit絶対値でアドレスを指定します。具体的にはlui命令とロード命令などの12ビットオフセットを使います。lui命令とは20ビットのimmediateを12ビット左シフトして、符号拡張する命令のことです。
medlow指定時に生成されるコードの例
lui a1, 0x12345 # 12ビットシフトされた値0x12345000がa1に格納される ld a0, 0x678(a1) # アドレスa1 + 0x678 = 0x12345000 + 0x678からa0に値をロードする
このようなコードが生成されます。絶対値は -2GB〜 +2GBまでしか生成できませんので、全てのシンボルが範囲に収まっている必要があります。32bitアドレスを使っている場合は全てのアドレス範囲をカバーできますが、64bitアドレスを使っている場合は0x00000000_00000000〜0x00000000_7fffffffまたは0xffffffff_80000000〜0xffffffff_ffffffffのアドレス範囲にシンボルを配置しなければなりません。範囲外にシンボルを配置しようとすると、
medlowのアドレス生成範囲外となるケース
// a.c
extern volatile int *hoge;
void _start(void)
{
*hoge = 1;
}
/* a.ld */
OUTPUT_ARCH("riscv")
ENTRY(_start)
SECTIONS
{
PROVIDE(hoge = 0x100000000); /* 0x1_00000000はmedlowの範囲外 */
}
medlowのアドレス生成範囲外となるケース(リンク結果)
$ riscv64-zephyr-elf-gcc -march=rv64gc -Wall -g -mabi=lp64d -mcmodel=medlow -nostdlib -T a.ld a.c --save-temp a.o: in function `_start': test-medany/a.c:5:(.text+0x6): relocation truncated to fit: R_RISCV_HI20 against symbol `hoge' defined in *ABS* section in a.out collect2: error: ld returned 1 exit status
リンカーがエラーを出します。hogeのアドレスを変更し -2GB〜 +2GBの範囲(0xffffffff_80000000や0x00000000_70000000など)にするとリンクが通ります。
medany
もう1つのmedanyは、PC相対でアドレス指定します。具体的にはアドレスの場合はauipc命令とaddi命令、ジャンプの場合はauipc命令とjalr命令の12ビットオフセットを使います。auipc命令とは、20ビットのimmediateを12ビット左シフトして、符号拡張したあとPCに加算する命令のことです。
PCが0x1_40000000付近でhogeが0x1_a89abcd0だとすると、
medany指定時に生成されるコードの例
アドレスの場合 140000006: auipc a5,0x689ac # 12ビットシフトされた値0x689ac000 + PC 0x1_40000006 = 0x1_a89ac006がa5に格納される 14000000a: addi a5,a5,-822 # 0x1_a89ac006 - 822 = 0x1_a89abcd0 = hogeのアドレスがa5に格納される ジャンプの場合 140000008: auipc ra,0x689ac # 12ビットシフトされた値0x689ac000 + PC 0x1_40000008 = 0x1_a89ac008がraに格納される 14000000c: jalr -824(ra) # ra 0x1_a89ac006 - 824 = 0x1_a89abcd0 = hogeのアドレスにジャンプする
このようなコードが生成されます。相対アドレスはPCの現在地 -2GB〜 +2GBまでしか生成できません。medlowモデルより対応できる範囲は広がったものの、いかなるアドレスでも対応できるわけではないです。例えばコード領域とデータ領域をあまりにも遠くすると、
medanyのアドレス生成範囲外となるケース
// a.c
extern volatile int *hoge;
void _start(void)
{
*hoge = 1;
}
/* a.ld */
OUTPUT_ARCH("riscv")
ENTRY(_start)
MEMORY
{
TEXT(rx) : ORIGIN = 0x0000000140000000, LENGTH = 0x10000
}
SECTIONS
{
/* hogeをコード領域から2GB以上離して配置する */
PROVIDE(hoge = 0x1c89abcd0);
/* コード領域を0x1_40000000にする */
.text : {
*(.text*);
} > TEXT
}
medanyのアドレス生成範囲外となるケース(リンクの結果)
$ riscv64-zephyr-elf-gcc -march=rv64gc -Wall -g -mabi=lp64d -mcmodel=medany -nostdlib -T a.ld a.c --save-temp a.o: in function `_start': test-medany/a.c:5:(.text+0x6): relocation truncated to fit: R_RISCV_PCREL_HI20 against symbol `hoge' defined in *ABS* section in a.out collect2: error: ld returned 1 exit status
シンボルhogeが位置するアドレスは絶対値 -2GB〜 +2GBの範囲外であり、コード領域からも離れているためPC相対 -2GB〜 +2GBの範囲外でもあります。よってmedlowモデルでもmedanyモデルでもリンクエラーとなります。
コメント一覧
- whtさん(2024/11/17 23:41)
This blog solves my problem. Thanks a lot! - すずきさん(2024/11/19 01:04)
It was my pleasure.
この記事にコメントする
2021年9月23日
耳年齢チェック
何kHzの音まで聞こえるかテストするサイト、聞こえチェック | Panasonic が、以前Twitterでちょっと話題になりました。
私の場合15kHzまでは聞こえますが、それ以上(17kHz, 19kHz)は全く聞こえません。鳴ってんのか?これ??
測ってみよう
まずブラウザの影響を排除するため、上記のサイトから音源をダウンロードします。WavではなくMP3ファイルでした。
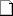 15kHz
15kHz直接オーディオプレイヤーで聞いても15kHz以外は聞こえません。ブラウザのせいじゃなかった。私の耳は全くあてにならないので、オシロスコープにご登場願います。
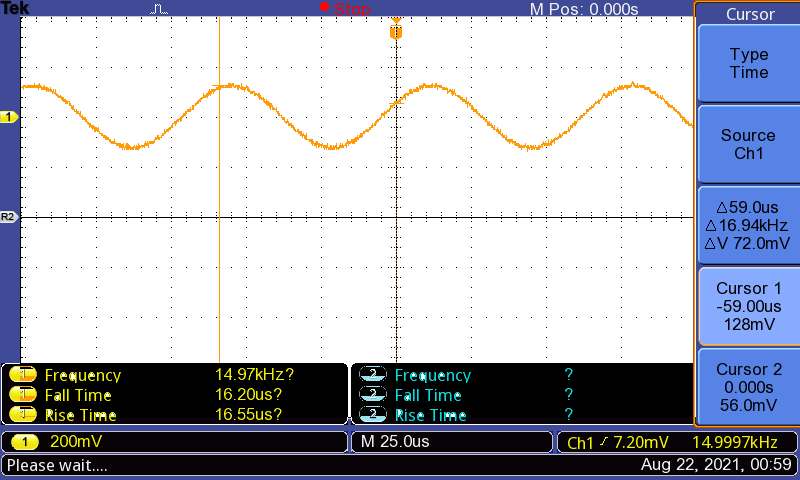

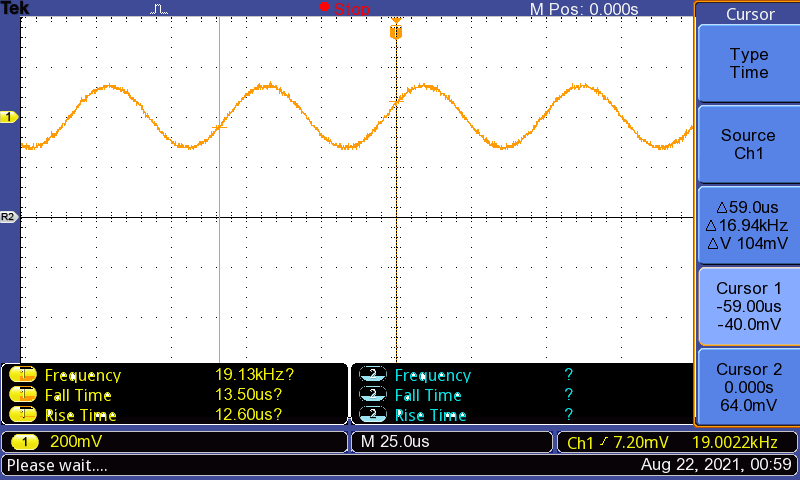
19kHz再生時の波形(グラフはキャプチャし忘れて17kHzのまま。右下の周波数表示が19kHzを示している)
いやあ、バッチリ綺麗にSin波が鳴ってます。私は全く聞こえませんね、これが老いかぁ……。
コメント一覧
- コメントはありません。
この記事にコメントする
2021年9月26日
xtermの256色端末
まれにxtermの256色指定エスケープシーケンスに対応していない端末があってvimの表示が変な色になってしまいます。チェック用のスクリプトを作っておきました。単純に背景色を変更するエスケープシーケンスと、空白文字、色を元に戻すエスケープシーケンスを連打するだけです。
xterm 256色指定エスケープシーケンステスト用スクリプト
#!/bin/sh
ESC_ORG="\e[0m"
print_colors()
{
for i in ${*};
do
printf " %3d\e[%dm " ${i} ${i};
echo -n ${ESC_ORG}
done
echo
}
print_xterm_colors()
{
for i in ${*};
do
printf " %3d\e[48;5;%dm " ${i} ${i};
echo -n ${ESC_ORG}
done
echo
}
echo "System colors (ESC[Nm):"
print_colors `seq 40 47`
echo
echo "xterm 256 colors (ESC[48;5;Nm):"
for i in `seq 0 8 248`;
do
j=`expr ${i} + 7`
print_xterm_colors `seq ${i} ${j}`
done
実行するとこんな感じになります。
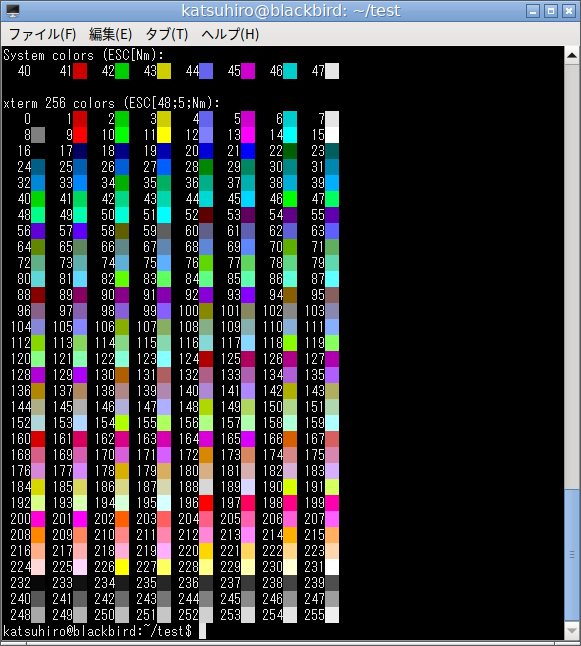
対応していない端末だとこうなりますと言いたいところでしたが、対応していない端末が見当たりませんでした。前はあった気がするんだけどなあ……?
コメント一覧
- コメントはありません。
この記事にコメントする
2021年9月28日
マルチコアのブート処理
目次: RISC-V
メインCPUからサブCPUを起こすとき基本的には、
- CPUのID(RISC-VであればCSRのmhartid)を見て、自身がメインかサブかを知る
- サブ側は共有RAMをポーリングなどで見張り、メインCPUからの起動司令を受け取るまで待つ
- メイン側は共有RAMに値を書いてサブCPUに起動司令を送る
RAMの初期値が不定であると仮定すると、サブCPUが下手にポーリングすると、不定値によって条件が成立してしまい、メインCPUからの起動司令がないのに勝手に起動してしまう事態に陥ります。
素朴な実装
先程書いた基本的な構造を素直に書くとこんなコードになるでしょう。
素朴なマルチコアのブート
/* メインCPUはHARTID=8, サブCPUはHARTID=0...3とする */
#define HARTID_MAIN 8
#define HARTID_SUB_START 0
#define HARTID_SUB_END 3
#define HARTID_MAX 9
struct {
int boot_wait;
int boot_done;
} init_core[HARTID_MAX] = {};
int get_hartid(void)
{
int i;
__asm__ volatile("csrr %0, mhartid" : "=r"(i));
return i;
}
/* メインCPUが実行する */
void boot_main(void)
{
for (int i = HARTID_SUB_START; i < HARTID_SUB_END; i++) {
init_core[i].boot_wait = 1;
}
}
/* サブCPUが実行する */
void boot_sub(void)
{
int hartid = get_hartid();
while (!init_core[hartid].boot_wait) {
/* busy loop */
}
}
残念ながらこのコードは正常に動作しません。共有RAMつまりinit_core[hartid].boot_waitの値が起動直後から != 0だったとき、boot_sub() はboot_main() からの起動司令を待つことなく起動してしまうからです。
不定値への対処
共有RAMの不定値に対処する方法を考えます。基本的にはサブCPUが変数を初期化(boot_wait = 0)してから待ちに入れば良いのですが、新たな問題が生じます。メインCPUとサブCPUの実行順序はどちらが先という保証はないため、
- メインCPUからの起動司令boot_wait = 1
- サブCPUで変数を初期化boot_wait = 0
以上の順で実行されるとメインCPU側の起動司令が消されてしまい、ハングアップする可能性があります。この問題の回避のため、変数を1つ追加し、サブCPUのブートが終わるまで、メインCPUは繰り返し起動司令を送るように変更します。
- 変数を2つ用意する(boot_wait, boot_done)
- メイン: boot_done = 0
- メイン: サブから応答(boot_done != 0)があるまで、boot_wait = 1を書き続ける
- サブ: boot_wait = 0
- サブ: boot_done = 0
- サブ: boot_wait == 0なら待つ
- サブ: boot_done = 1
先程書いた基本的な構造を素直に書くとこんなコードになるでしょう。
不定値への対処を入れたコード
/* メインCPUはHARTID=8, サブCPUはHARTID=0...3とする */
#define HARTID_MAIN 8
#define HARTID_SUB_START 0
#define HARTID_SUB_END 3
#define HARTID_MAX 9
struct {
int boot_wait;
int boot_done;
} init_core[HARTID_MAX] = {};
int get_hartid(void)
{
int i;
__asm__ volatile("csrr %0, mhartid" : "=r"(i));
return i;
}
/* メインCPUが実行する */
void boot_main(void)
{
for (int i = HARTID_SUB_START; i < HARTID_SUB_END; i++) {
init_core[i].boot_done = 0;
while (!init_core[i].boot_done) {
init_core[i].boot_wait = 1;
}
}
}
/* サブCPUが実行する */
void boot_sub(void)
{
int hartid = get_hartid();
init_core[hartid].boot_wait = 0;
init_core[hartid].boot_done = 0;
while (!init_core[hartid].boot_wait) {
/* busy loop */
}
init_core[hartid].boot_done = 1;
}
残念ながらこのコードも正常に動作しません。共有RAMへの値の反映が他のCPUに即座に見えること(アトミック性)を暗に期待しているからです。
アトミック性への対処
今日のマルチコアシステムでは、boot_wait = 0としたときに、他のCPUにも即座に同じ値が見えているとは限りません。主な要因としては、
- コンパイラによる並べ替え
- CPUのパイプライン
- CPUのデータキャッシュ、ライトバッファ
などがあります。通常の変数への代入、参照が他のCPUに即座に値が見えないことにより、おかしくなるパターンはいくつか考えられそうですが、ありがちなパターンとして、
- サブCPU 0が起動したboot_done = 1
- メインCPUにboot_done = 1が伝わらず、サブCPU 1の起動指令がいつまでも送られない
以上の順で実行されるとメインCPU側が起動司令を送らないまま、サブCPU側も何もできずハングアップする可能性があります。この問題の回避のため、通常の変数への代入、参照ではなく他のCPUにも値が見えるように初期化、代入(アトミックアクセスする)必要があります。
従来C言語でアトミックアクセスを行うためには、実装対象アーキテクチャの知識やアセンブラの記述を必要とするなど、やや困難が伴いました。ですがC11でアトミックアクセス用の定義stdatomic.hが追加されたことで、アトミックアクセスはかなり楽になりました。素敵ですね。
ひとまず速度を全く気にせず、全てのアクセスをアトミックアクセスに入れ替えると、こんなコードになるでしょう。
アトミック性への対処を入れたコード
/* メインCPUはHARTID=8, サブCPUはHARTID=0...3とする */
#define HARTID_MAIN 8
#define HARTID_SUB_START 0
#define HARTID_SUB_END 3
#define HARTID_MAX 9
struct {
atomic_int boot_wait;
atomic_int boot_done;
} init_core[HARTID_MAX] = {};
int get_hartid(void)
{
int i;
__asm__ volatile("csrr %0, mhartid" : "=r"(i));
return i;
}
/* メインCPUが実行する */
void boot_main(void)
{
for (int i = HARTID_SUB_START; i < HARTID_SUB_END; i++) {
atomic_store(&init_core[i].boot_done, 0);
while (!atomic_load(&init_core[i].boot_done)) {
atomic_store(&init_core[i].boot_wait, 1);
}
}
}
/* サブCPUが実行する */
void boot_sub(void)
{
int hartid = get_hartid();
atomic_store(&init_core[hartid].boot_wait, 0);
atomic_store(&init_core[hartid].boot_done, 0);
while (!atomic_load(&init_core[hartid].boot_wait)) {
/* busy loop */
}
atomic_store(&init_core[hartid].boot_done, 1);
}
C11のアトミックアクセスは何も指定しない場合、一番制限の強い(= 確実に他のCPUに見えるものの、アクセス速度は遅い)memory_order_seq_cstアクセスになります。マルチコアのブートを行うにあたって、常に制限が強いアクセスは必要ありませんが、とりあえずこれで動くはず。
コメント一覧
- コメントはありません。
この記事にコメントする
2021年9月30日
携帯の遍歴
日記を漁って携帯の遍歴を書き出してみました。日記を書く習慣がなかった頃の機種や時期は不明です。
- J-PHONE, Vodafone
- 不明(2000年くらい?): SHARP J-SH04辺り?
- 不明(2002年くらい?): TOSHIBA J-T06辺り?(ストレートだった気がする)
- NTTドコモ、ガラケー
- 2004年8月: Fujitsu F506i
- 2005年6月: Fujitsu F506iマイク故障で交換
- 2006年 ?月: NEC N902iS
- 2008年 ?月: NEC N902iSのバッテリー交換
- 2010年7月: Panasonic P-03B
- NTTドコモ、スマホ
- 2011年7月: Sony Ericsson Xperia acro SO-02C
- 2014年3月: SHARP AQUOS PHONE ZETA SH-01F
- SIMフリー、スマホ
- 2016年11月: ASUS Zenfone 3 Deluxe
- 2021年4月: Google Pixel 4a
(基本的には)長く使っていた機種は気に入っていた機種です。ガラケー時代はいずれも良い機種で、バッテリーが死ぬまで使ってました。最後のP-03Bだけ1年しか使っていませんが、不満があったわけではなく、知人に携帯を譲るため手放しました。たしか。
スマホ時代は国内メーカーの質は明らかに落ちました。SO-02Cはソツなく良かったんですけど、ストレージが少なすぎで買い替え直前は容量不足で挙動不審でした。SH-01Fは性能良いものの、電池がなくなるのが早く、本体が熱すぎでした。この機種で懲りてAndroidハイエンド機を買わなくなりました。
今になって調べてみたところ、この2機種はマシな部類だったようで、富士通ARROWSのように「カイロ機能搭載」「電話ができない」「メールがこない」など、怨嗟にまみれたレビューが未だに残っている機種もあります。悲惨です。
日本だけ異常にiPhone普及率が高い理由って、国内メーカーが2010年代初頭にやらかしたから……!?と思ってしまいました……。
メモ: 技術系の話はFacebookから転記しておくことにした。
コメント一覧
- コメントはありません。
この記事にコメントする
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 2026年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報