
2020年1月6日
memsetのベンチマーク(AArch64, Cortex-A53編)
目次: ベンチマーク
(参考)コード一式はGitHubに置きました(GitHubへのリンク)
AArch64その2です。Cortex-A53でmemsetをやってみました。環境はRK3328 Cotex-A53 1.4GHzです。メモリはおそらくLPDDR3-1600です。
Cortex-A72と似ている点としては、
- musl memset関数が非常に優秀
- ベクトル化は性能向上に効くが、他も有効な要素がありそう
違う点としては、
- アセンブラ実装とmusl memset関数の差が開く
- O3の最適化がかなり効く(※)
- glibc memset関数の不安定さが減る
こんなところでしょうか。A72のglibc memset関数はグラフが上がったり下がったりグチャグチャしていましたが、A53だと割と素直になっています。
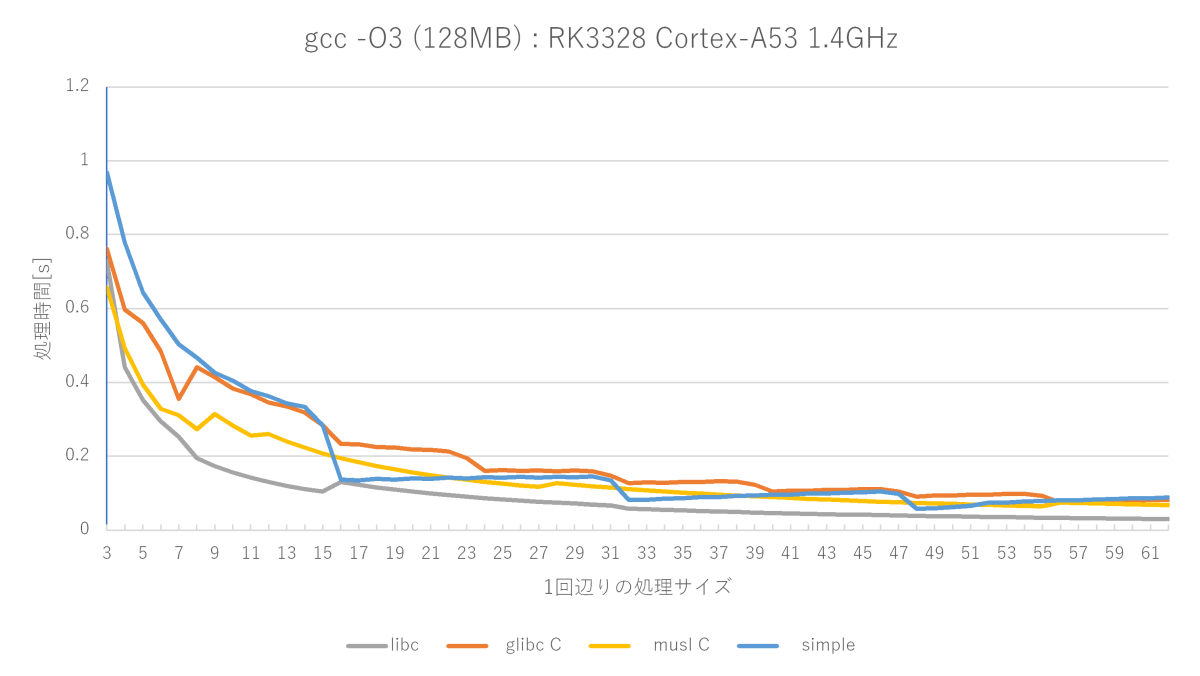
gcc -O3 -fno-builtinの測定結果(Cortex-A53編)
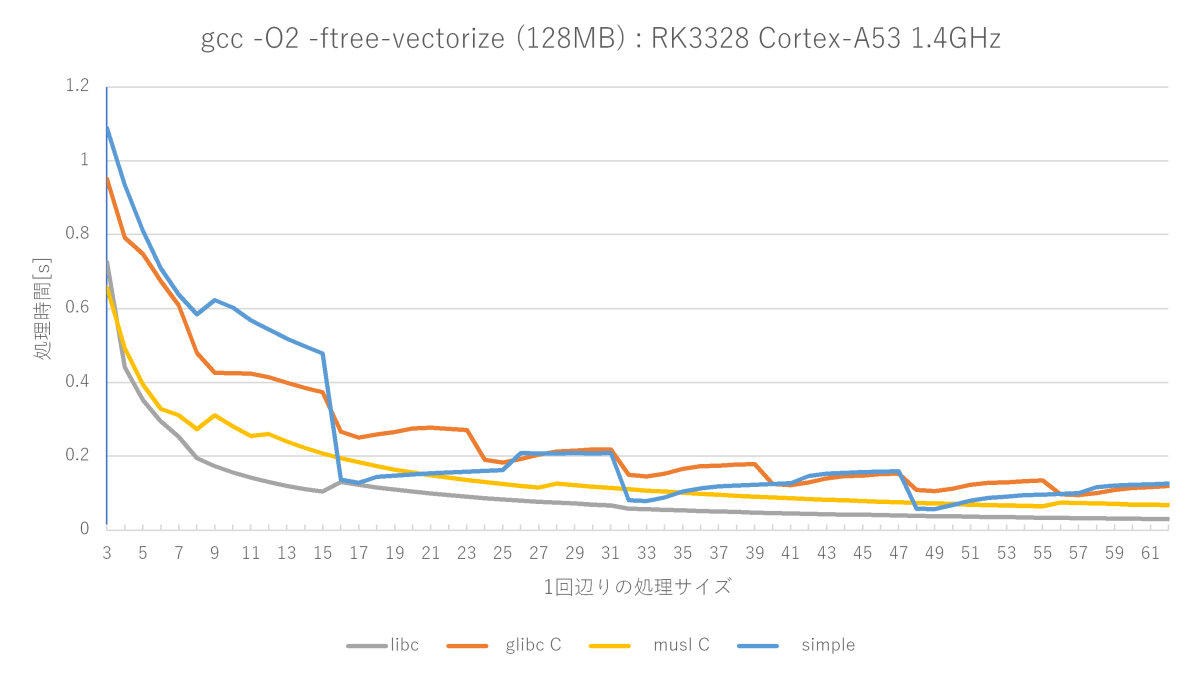
gcc -O2 -ftree-vectorize -fno-builtinの測定結果(Cortex-A53編)
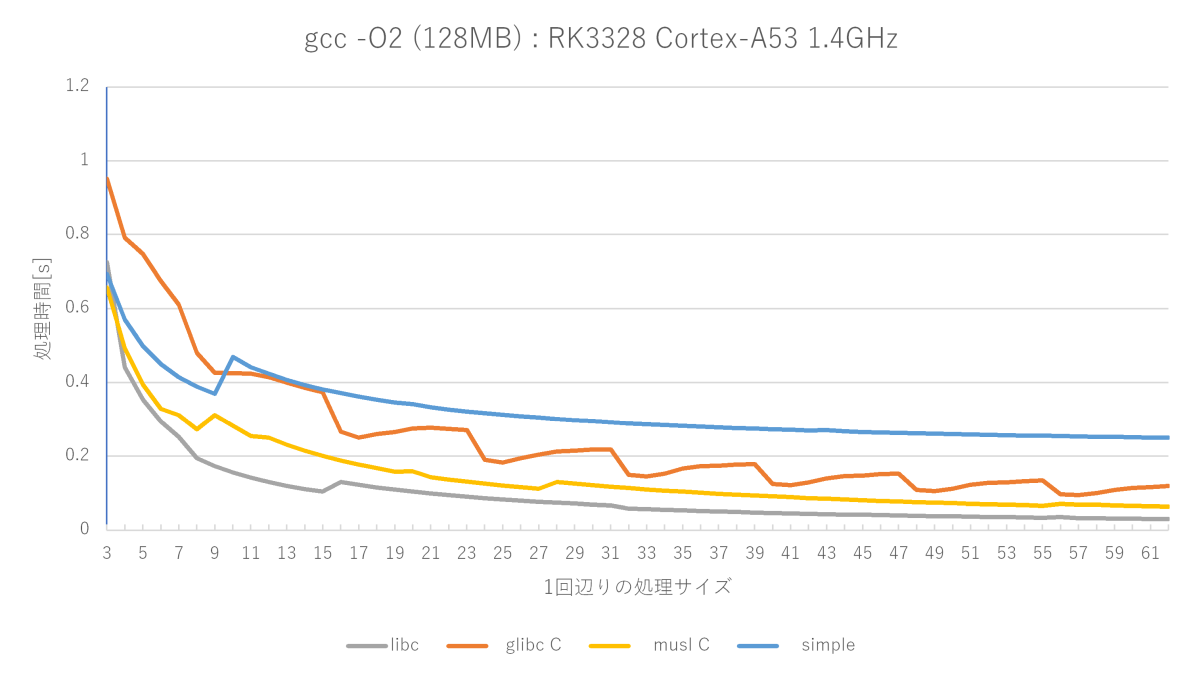
gcc -O2 -fno-builtinの測定結果(Cortex-A53編)
(※)A72では単純なmemset関数はmusl memset関数にほぼ勝てない(16〜22バイトのみ勝つ)が、A53では割と良い勝負(16〜22、32〜38、48〜52バイトで勝つ)をしている。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2020年1月11日
memsetに一番効く最適化
目次: ベンチマーク
Cortex-A72でのmemsetはO2に-ftree-vectorizeと -fpeel-loopsを足すと、O3の性能とほぼイコールになることがわかりました。

gcc -O2 -ftree-vectorize -fpeel-loops -fno-builtinの測定結果(Cortex-A72)
元の処理が非常に単純なループ処理のためか、ループ系の最適化がメチャクチャ効くっぽいです。
何が効くのか?
GCCのGIMPLEを出力させ(-fdump-tree-all)眺めてみると、
- オリジナル
- 1バイトごとにデータ処理するループが生成される。
- ベクタライズ(161t.vect)
- 16バイトごとにデータ処理するループと、1バイトごとに残りデータを処理するループに分割される。
- アンローリング(164t.cunroll, 169t.loopdone)
- 残りデータを処理するループが展開される。
こんな感じに見えます。正直言って、ループアンローリングなんて大したことないと思っていましたが、これほど効くとは思いませんでした。
メモ: 技術系の話はFacebookから転記しておくことにした。大幅に追記。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年1月12日
ぼくの考えた最強のmemset
目次: ベンチマーク
NEON intrinsicを使って自分でmemsetを実装してみました。ざっくりした設計方針としては、
- NEON store (128bit) x 2で32バイトずつ書く
- 端数25〜バイトはNEON store x 2
- 端数16〜バイトはNEON store + uint64 store
相手は汎用実装ですし、Cortex-A72に特化した実装なら楽勝だろう、などと考えて始めましたが、甘かった。glibcのフルアセンブラ版はかなり手ごわいです。
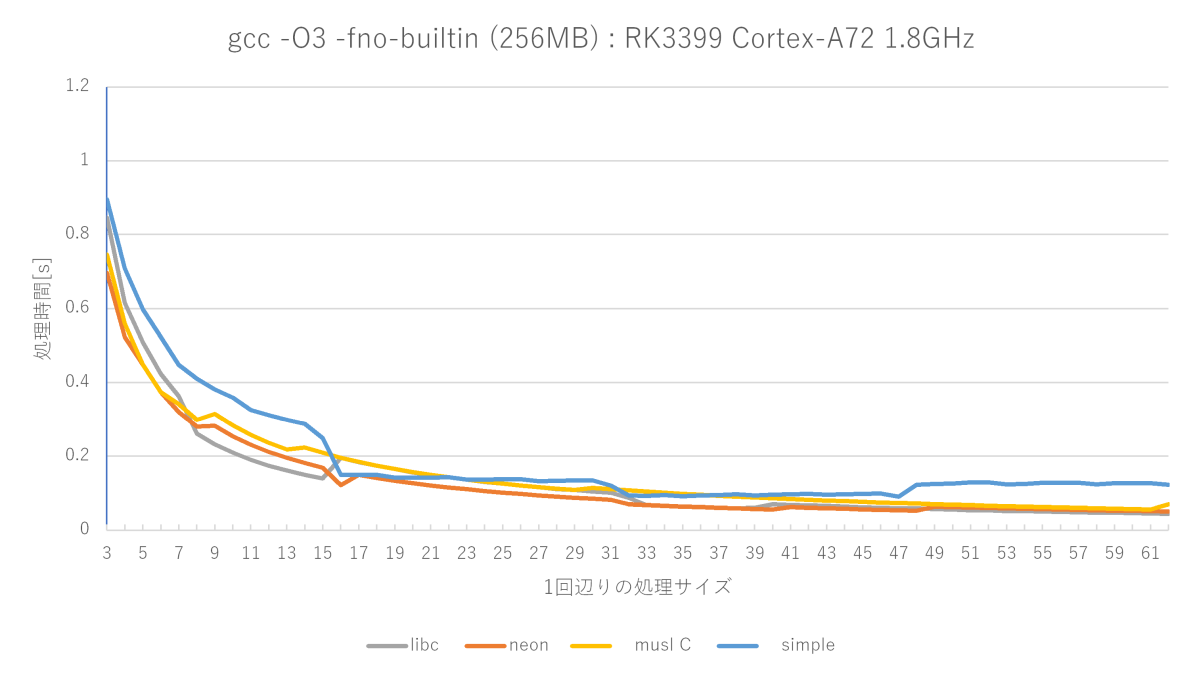
グラフの赤い線が、自作したmemsetの性能です。
最適化レベルO3のsimple memsetにはほぼ全域で勝てますが、サイズが小さいときのmuslは強い(サイズが小さい場合から判定しているから?)です。glibcのフルアセンブラもかなり強いです。測定によって勝ったり負けたりな程度です。
全然最強じゃなかった……
設計が甘すぎたことがわかったので、下記のように見直しました。
- 少ないバイト数の条件から判定
- NEON store (128bit) x 2で32バイトずつ書く
- 端数バイトはNEON store(分岐を減らした)
序盤でmusl memsetに負けていたのは、バイト数の条件判定の順序が良くなかった(大きいサイズから判定していた)ためなので、1番目で対策しています。2番目と3番目の方針は良いとも悪いとも一概に言えませんが、RK3399だとこれが一番性能が出ました。
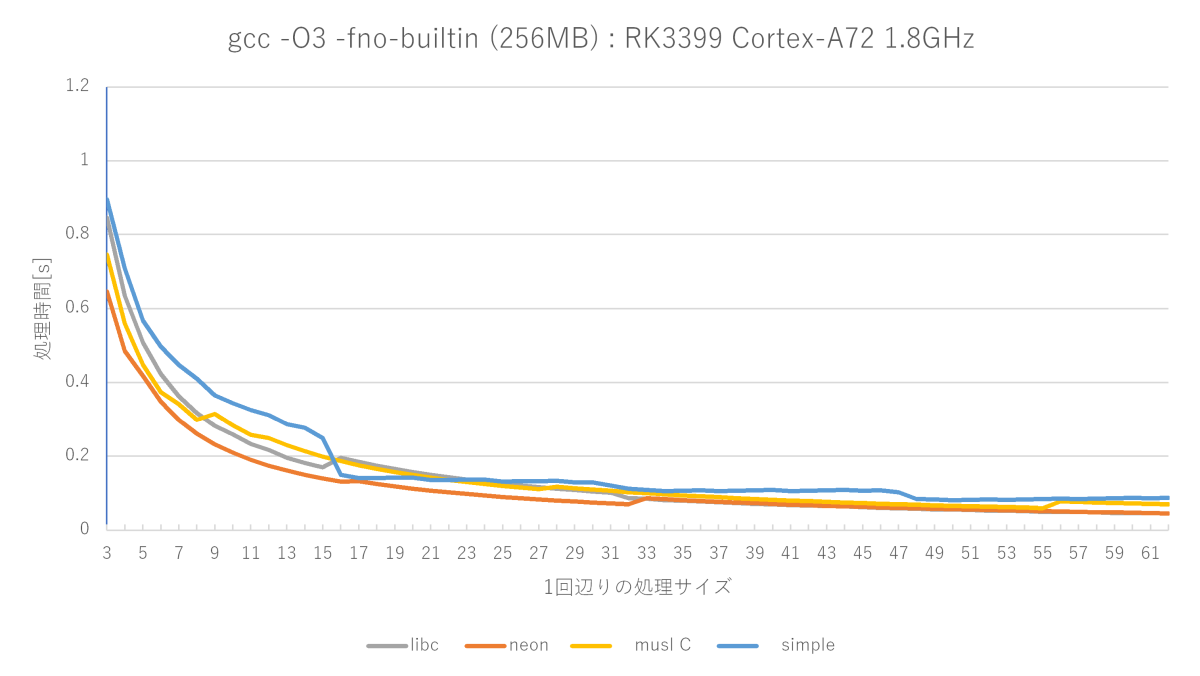
設計意図通りにmuslの序盤(特に高速な1〜8バイト付近)と、glibcフルアセンブラの序盤(1〜32バイト)には勝てたものの、glibcフルアセンブラ版は中盤以降が強く、33バイト以降は全く勝てません。
私の作ったmemsetは32バイトまでは専用処理で、33バイトからループで処理するようになるので、33バイトから性能がかなり落ちます。
おそらくglibcフルアセンブラ版も同様に16バイトから性能が落ちるので、ループ処理していると思うんですが、それ以降の巻き返しが凄くて、33バイト以降はまったく勝てないですね……。どうやってんだろうね、これ?
コンパイラが変なandとかsubを出力しているのを見つけたので、アセンブラでも実装してみましたが、性能はほぼ変わりませんでした。設計の根底が違うんでしょうね。
Cortex-A53だと全く勝ち目無し
RK3328(Cortex-A53)で測ってみると、muslには勝てますが、glibcフルアセンブラ版には勝ち目無しで、ほぼ全域に渡ってボコボコにされます。
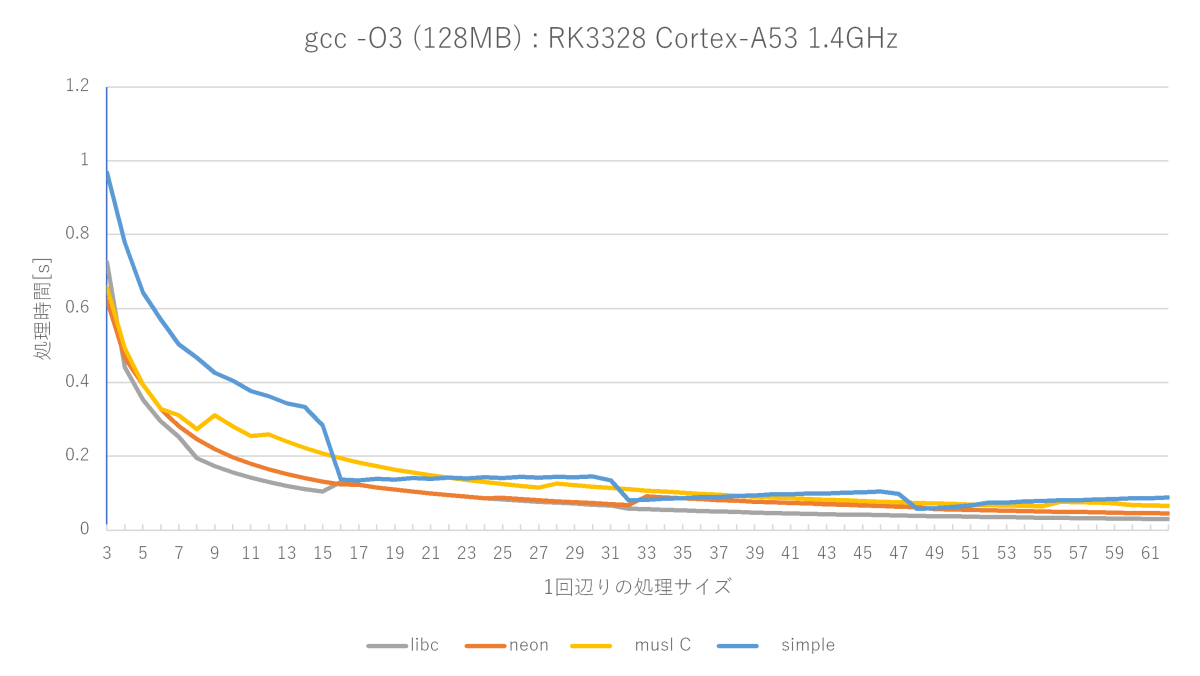
基本設計が「余計なwriteをしてでも、とにかく速く終われ」なので、writeを正直に実行してしまうようなヘボいプロセッサになればなるほど勝ち目が薄いです。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年1月19日
バイトをコピーするSIMD命令
目次: ベンチマーク
最近、見かけるSIMD命令セット(AVXもNEONも)には、レジスタ下位 [7:0] の1バイトを、レジスタ上位 ... [31:24] [23:16] [15:8] の各バイトに配る命令が用意されています。
- AVX: vpbroadcastb
- NEON: dup
この命令はどういう需要があるんだろうか……?memsetの実装では超役に立ちましたが、他の使い道が良くわかりません。
Facebookで上記の話をしていたところ、
- 8bit行列演算: 8bit行列演算ってそんな頻出かな、って思ったら、画像使えば8bitなので十分有り得そう。
- バイト暗号: ブロック毎に空間変換する時とか雑に言えばスカラとベクトルの演算。
と教えてもらいました。なるほど、スカラベクトル積のスカラ側を配るときに便利ですね。
SIMD命令のない世界
ちなみにSIMDのない処理系はどうしているのか見てみると、
int a = (何かの数字);
としたときに、
a &= 0xff;
a *= 0x01010101;
のようにand, mov, mulを使っていました。もちろん、
a &= 0xff;
a |= a << 8;
a |= a << 16;
のようにand, shift, or, shift, orでもできますが、今日日のプロセッサだと整数乗算の方が速そうですね。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年1月20日
glibcのmemsetのクセ
目次: ベンチマーク
先日memsetを書いていたとき(2020年1月12日の日記参照)に気づいたのですが、glibcのフルアセンブラ版memsetの性能が2通り(遅い、速い)あることに気づきました。だいたい1割くらい性能が変わります。
遅いときと比較すると、自作のmemsetの方が速いですが、速いときと比較するとボロ負けします。割と性能が迫っているためか、影響が大きいです。
何が違うんでしょうね?コードは当然同じですから、違いはmemset関数のロードされるアドレスくらいです。まさかなと思って、スタティックリンクしたら安定して速くなりました。
ダイナミックリンクだと、アプリ側は0xaaaac4fba560で、glibcだけ0xffffbf2dce00のような遠いアドレスに飛ばされます。ベンチマーク中は、アプリのコード ←→ glibcのコードを頻繁に行き来することになるので、TLBミスヒットの影響が出ているんですかね……??
真因はわかりませんが、アドレスが関係している可能性は高いです。今後、似たようなことをやるときは、スタティックリンクで測った方が良さそうです。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年1月21日
glibcのmemsetは強かった
目次: ベンチマーク
先日(2020年1月12日の日記参照)の続きです。
あまりにもglibcフルアセンブラ版memsetの実装が速くて勝てないので、観念して実装を見たのですが、序盤(1バイト〜32バイト)が弱い理由と、以降(33バイト〜)で勝てない理由がわかりました。
他の実装と違ってglibcはサイズの大きい方から条件を見ています。どうしても条件分岐命令を通る回数が増えるため、序盤に弱いです。
中盤は96バイトまではNEON store x 4と分岐で捌いていて、ループを使いません。分岐もcmpしてbranchではなく、ビットセットされていたら分岐する命令(tbz, tbnz)を使っています(※)。
つまり私が書いたmemsetはループで処理している時点で、ほぼ勝ち目がなかったということです。
グラフでは63バイトまでしか測っていなかったから気づかなかったのですが、ループの2週目に入る65バイトから、さらにボロ負けです。いやはや、これは勝てないですね……。
(※)cmp, branchの2命令をtbz 1命令にする辺り、AArch64アセンブラならではの実装に見えますが、実はCでもif (a & 0x10) とか書くとコンパイラがtbz命令を使います。コンパイラ侮りがたし。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年1月26日
C言語の未定義動作と最適化
目次: C言語とlibc
くそ長いですが、C言語の未定義動作怖いね、printfでタイミング以外も動き変えられるよ、という話です。
環境ですがx86_64向けDebian GNU/Linux 9.2で実行しています。またGCCのバージョンはgcc (Debian 9.2.1-22) 9.2.1 20200104です。
未定義動作のため、コンパイラの種類や、GCCのバージョンにより結果が変わると思われます。お家のマシンで試すならご留意ください。
1番目の実験
この日記の最後に貼ったプログラム(このプログラムをコンパイルすると、激しい警告が出ます)をgcc -Wall -O2 a.c && ./a.outのように実行すると、
1番目の実験: あれ?バッファオーバーランは…?
0: 0 0 0 1: 0 1 0 2: 0 2 0 3: 0 3 0 4: 0 4 0 ... 47: 0 47 0 48: 0 48 0 49: 0 49 0 1770: 1770
こうなります。0〜59の和は1770です。あってます。良かったですね。
なに?そういう問題じゃない?「なぜarray終端を超えてguard2にバッファオーバーランしない?」と考えた方、するどいです。しかし世の中そう単純ではありません。
2番目の実験
10行目のprintfのコメントを外してローカル変数のアドレスを表示させると、
2番目の実験: 10行目のprintfを有効、突然のバッファオーバーラン
0x7ffd9b348a10 0x7ffd9b348ae0 0x7ffd9b348bb0 0: 0 0 52 1: 0 1 53 2: 0 2 54 3: 0 3 55 4: 0 4 56 ... 45: 0 45 0 46: 0 46 0 47: 0 47 0 48: 0 48 0 49: 0 49 0 1770: 1770
こうなります。突然オーバーランするようになりました。printfが何かしたんでしょうか、不思議ですね?
3番目の実験
どうしてforループを無意味に2分割したのか?くっつけてみたらわかります。Segmentation Fault します。
3番目の実験: ループを1つにするとクラッシュ
0: 0 0 0 1: 0 1 0 2: 0 2 0 3: 0 3 0 4: 0 4 0 ... 45: 0 45 0 46: 0 46 0 47: 0 47 0 48: 0 48 0 49: 0 49 0 Segmentation fault
もう意味不明ですよね。何が起こっているんでしょう?
タネ明かし
この60回のforループは「配列の終端を超えたアクセス」がC言語仕様上の未定義動作なので、何が起きても正しい、つまりどの結果も正しいです。
これだけだと、何言ってんのか意味不明だと思うので「printf有効/無効」「forループ1つ/2つ」に着目して説明します。
- 1番目の実験(printf無効、forループ2つ)
-
プログラムを見るとguard1, guard2に対してmemset 0した後、参照のみで代入しません。コンパイラはguard1, guard2をスタックに配置せず、配列への参照(guard1[i], guard2[i])は全て「定数の0」に置換します。
(GIMPLEを見たら033t.fre1で0に置換されるようです)
このときarrayのバッファオーバーランはスタックに退避されているレジスタ値などを書きつぶしますが、ギリギリ続行できています。 - 2番目の実験(printf有効、forループ2つ)
-
1番目と変わりないと思いきや、printfがguard1, guard2のアドレス参照をするため、定数の0に置換すると返せるアドレスがなくなり結果が変わってしまいます。このため、guard1, guard2はスタックに配置されます。
このときarrayのバッファーオーバーランは隣に配置されたguard2を書きつぶします。 - 3番目の実験(printf無効、forループ1つ)
- いわゆる偶然の結果です。1番目と同様にguard1, guard2はスタックに配置されず、arrayのバッファオーバーランによりスタックに退避したレジスタ値などが壊れます。forループが1つ減ったことでスタックに退避されるレジスタが1つ減って(8バイト分余裕がなくなる)、1番目の実験でギリギリリターンアドレスを壊されずに耐えていたものが、耐えられなくなります。
3番目の実験の裏打ちとして、試しにループ回数を80回くらいにするとforループが1つだろうが2つだろうが、リターンアドレスがぶっ壊れてSegmentation Fault します。10行目のprintfを有効にするとguard1, guard2がスタックに配置されて、受け止めてくれるので、80回でも耐えます。
難解なC言語仕様、曖昧な利用者の理解、過激なコンパイラの最適化、が招く結末
バッファオーバーランを期待していた向きには残念(?)かもしれませんが、guard1, guard2はメモリ上に置いても置かなくても、C言語仕様に矛盾しないなら、どっちでも良いです。もっというとC言語仕様に矛盾しないなら、コンパイラの最適化は何をやってもOK です。
この「C言語仕様に矛盾しないなら」はおそらくコンパイラ開発者には常識なのでしょうけども、C言語の仕様は人間に優しくないのと、大多数のC言語プログラマは言語仕様(特に未定義動作)を理解しておらず、何となく使っています。
難解な仕様、曖昧な理解、過激な最適化の相乗効果により、今日も世界のどこかで
「最適化で動きが変になっちゃったよ……。どうして…どうして……?」
とコンパイラとすれ違ったプログラマが泣いているでしょう。。。
参考
大したものではありませんが、ソースコードを載せておきます。
実験用ソースコード
#include <stdio.h>
#include <string.h>
int undefined()
{
int guard1[50];
int array[50];
int guard2[50];
int sum = 0, i;
memset(guard1, 0, sizeof(guard1));
memset(guard2, 0, sizeof(guard2));
//printf("%p %p %p\n", &guard1[0], &array[0], &guard2[0]);
for (i = 0; i < 60; i++) {
array[i] = i;
}
for (i = 0; i < 60; i++) {
sum += array[i];
}
for (i = 0; i < 50; i++) {
printf("%2d: %d %d %d\n", i, guard1[i], array[i], guard2[i]);
}
return sum;
}
int main(int argc, char *argv[])
{
int sum1 = 0, sum2 = 0, i;
sum1 = undefined();
for (i = 0; i < 60; i++) {
sum2 += i;
}
printf("%d: %d\n", sum1, sum2);
return 0;
}
コメント一覧
- コメントはありません。
この記事にコメントする
| < | 2019 | > | ||||
| << | < | 12 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | - | - | - | - |
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:

管理者: Katsuhiro Suzuki(katsuhiro( a t )katsuster.net)
This is Simple Diary 1.0
Copyright(C) Katsuhiro Suzuki 2006-2023.
Powered by PHP 8.2.20.
using GD bundled (2.1.0 compatible)(png support.)