2019年12月17日
memsetのベンチマーク(AArch64, Cortex-A72編)
目次: ベンチマーク
(参考)コード一式はGitHubに置きました(GitHubへのリンク)
先日Ryzen 7 2700なx86_64マシンでmemsetの性能を計測(2019年12月14日の日記参照)しました。同様の計測をAArch64でもやってみました。環境はRK3399 Cotex-A72 1.8GHzです。メモリはおそらくLPDDR3-1600のはず、OSはDebian GNU/Linux 10.2 busterです。
リファレンスとするのは前回同様、システムにインストールされているglibc-2.28のmemset関数(アセンブラ版)です。大抵の場合、この関数が最速ですね。
ざっとglibc-2.28の実装を見たところ、x86_64向けは各種SIMD向けに最適化されたアセンブラコード(glibc/sysdeps/x86_64/multiarch/memset-avx2-unaligned-erms.Sなど)が使われて、aarch64向けは汎用的なアセンブラコード(glibc/sysdeps/aarch64/memset.S)が使われるようです。
まずは最適化オプションO3とO2の差から見てみようと思います。
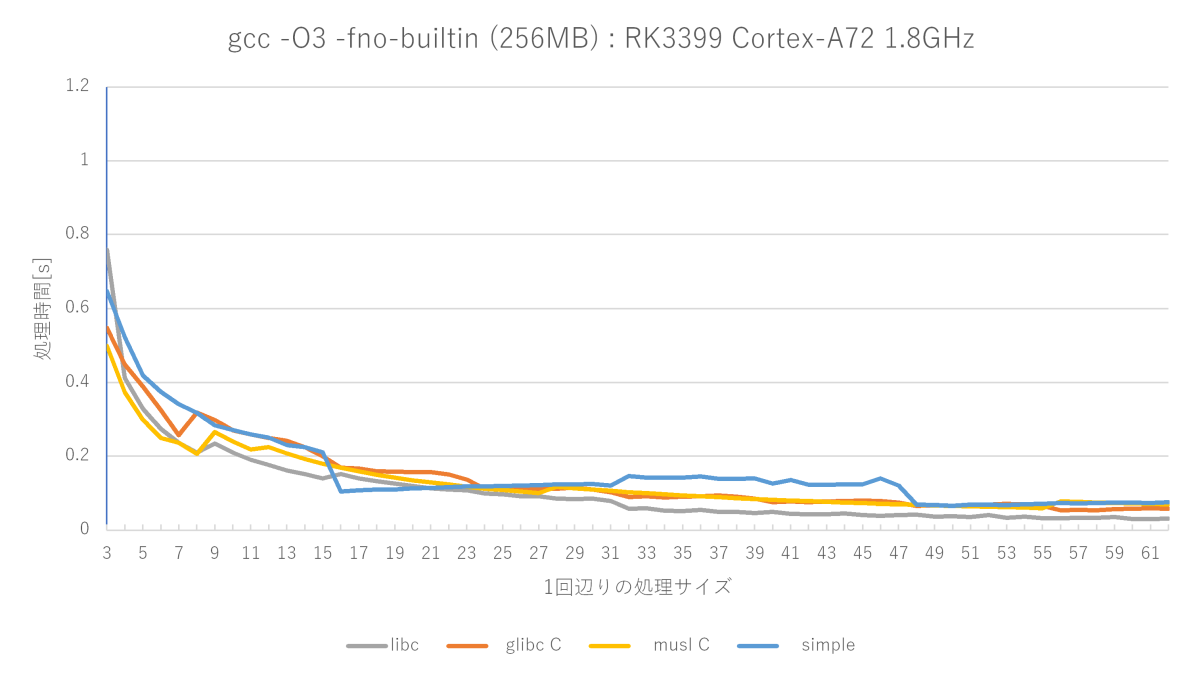
gcc -O3 -fno-builtinの測定結果(Cortex-A72編)
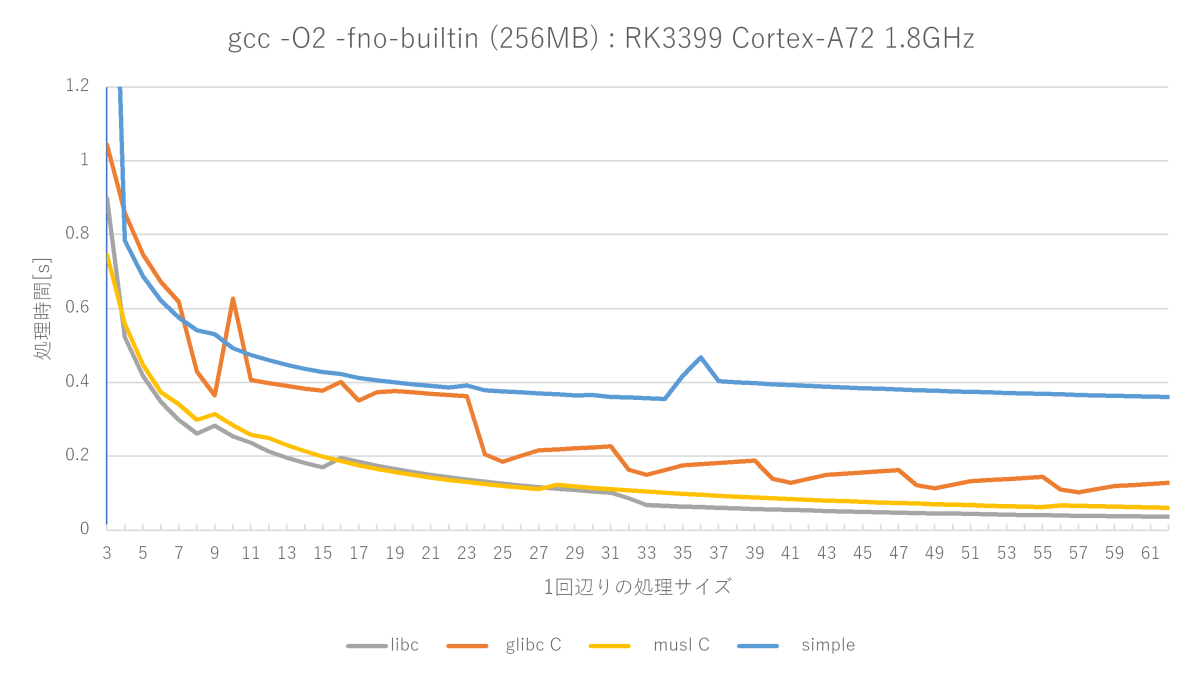
gcc -O2 -fno-builtinの測定結果(Cortex-A72編)
やはりO3の最適化による速度向上はさすがとしか言えません。x86_64ではあまり振るわなかったmusl memset関数が非常に優秀で、libcのmemsetに並ぶ勢いです。
AArch64のNEONを使ったベクトル最適化
前回はベクトル最適化 -ftree-vectorizeオプションを使うとほぼO3の性能に追い付きましたが、AArch64ではどうなるでしょう?
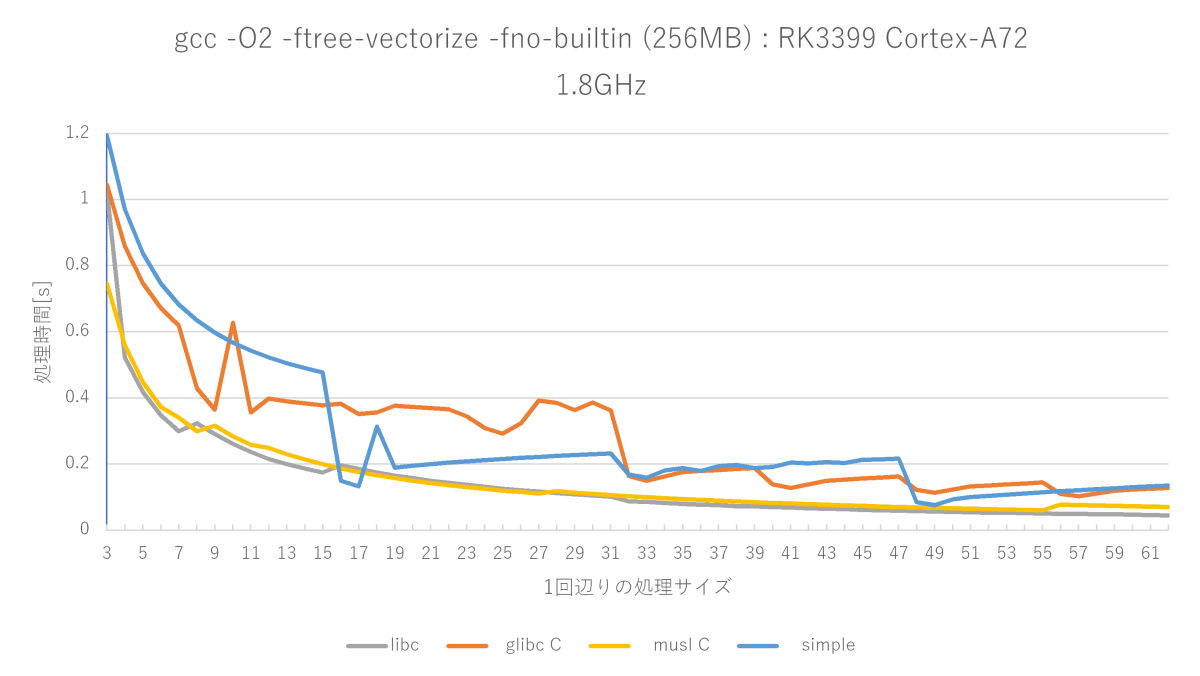
gcc -O2 -ftree-vectorize -fno-builtinの測定結果(Cortex-A72編)
ベクトル最適化を有効にするとNEONの128bitストア命令が使われるようになります。
O2と比較すると確かに性能向上していますが、x86_64ほどの威力は発揮しません。
メモ: 技術系の話はFacebookから転記しておくことにした。大幅に加筆。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2020年1月6日
memsetのベンチマーク(AArch64, Cortex-A53編)
目次: ベンチマーク
(参考)コード一式はGitHubに置きました(GitHubへのリンク)
AArch64その2です。Cortex-A53でmemsetをやってみました。環境はRK3328 Cotex-A53 1.4GHzです。メモリはおそらくLPDDR3-1600です。
Cortex-A72と似ている点としては、
- musl memset関数が非常に優秀
- ベクトル化は性能向上に効くが、他も有効な要素がありそう
違う点としては、
- アセンブラ実装とmusl memset関数の差が開く
- O3の最適化がかなり効く(※)
- glibc memset関数の不安定さが減る
こんなところでしょうか。A72のglibc memset関数はグラフが上がったり下がったりグチャグチャしていましたが、A53だと割と素直になっています。
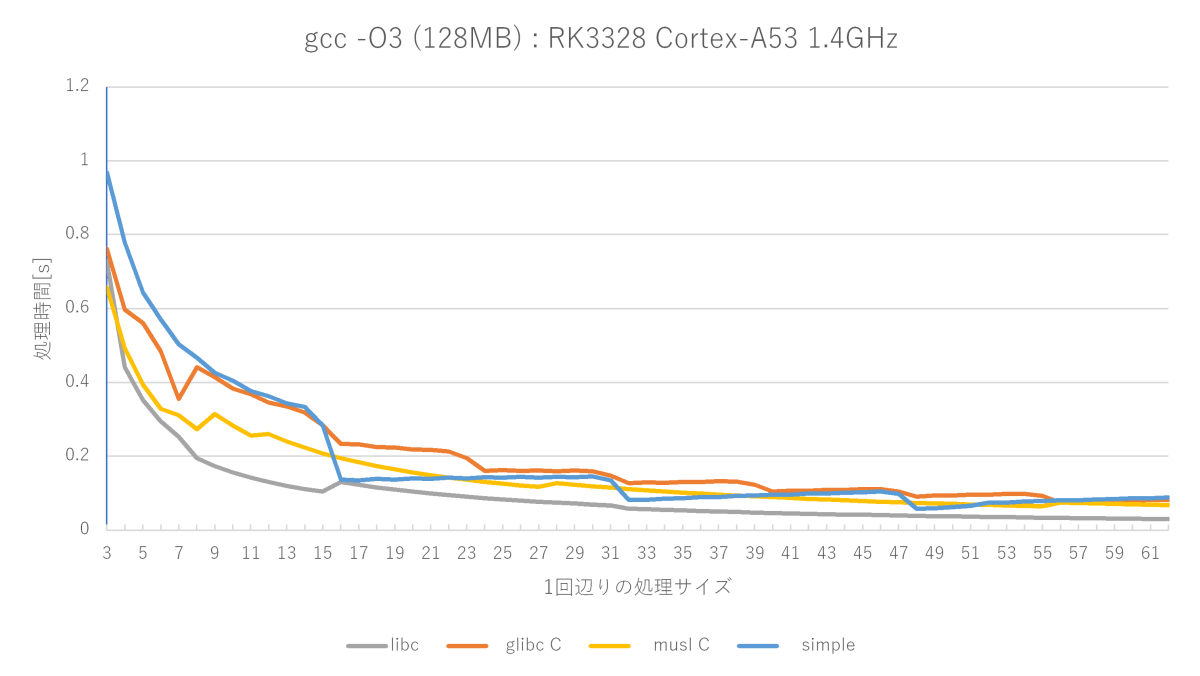
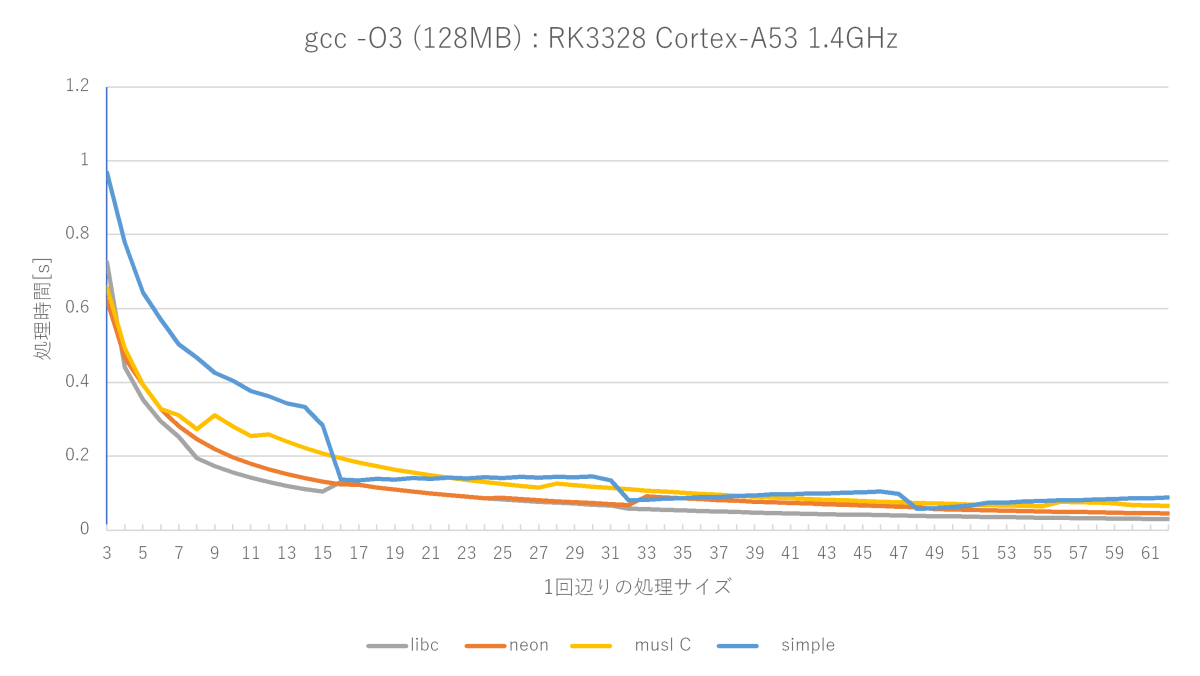
gcc -O3 -fno-builtinの測定結果(Cortex-A53編)
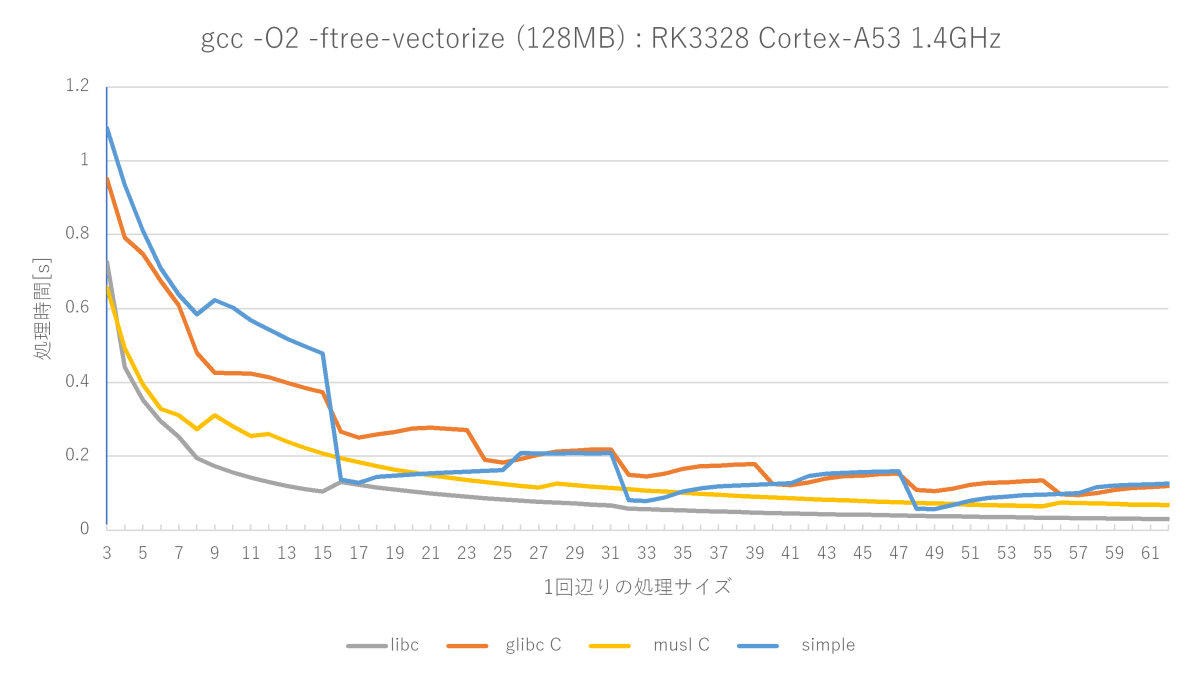
gcc -O2 -ftree-vectorize -fno-builtinの測定結果(Cortex-A53編)
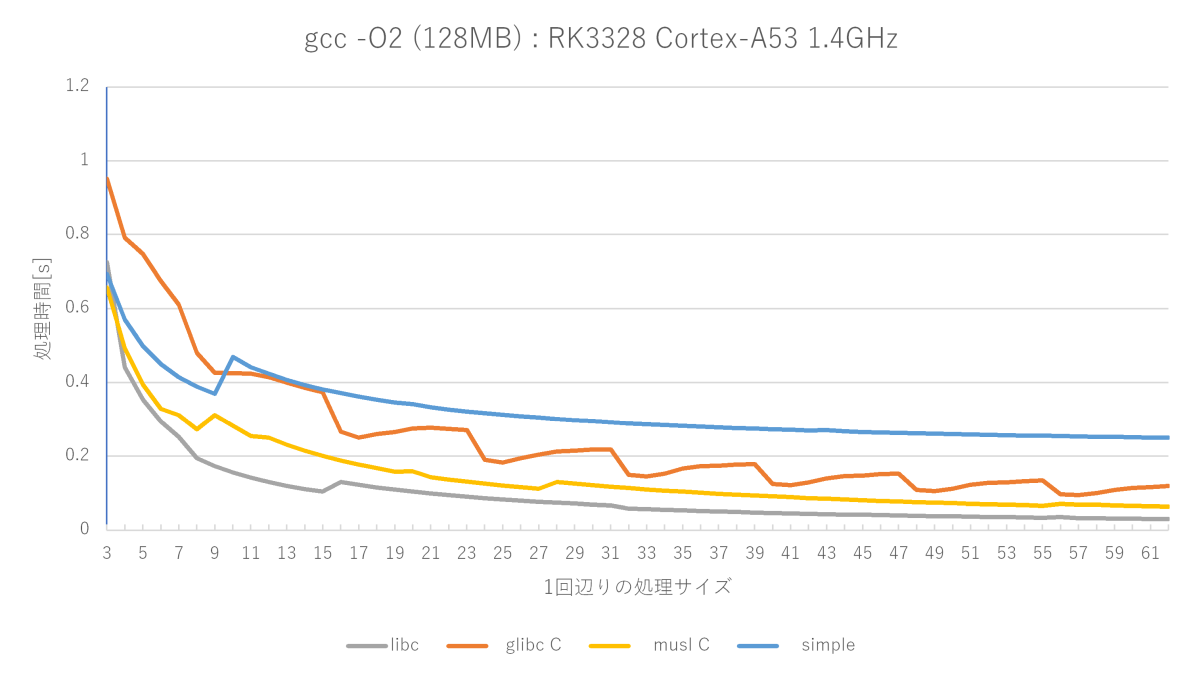
gcc -O2 -fno-builtinの測定結果(Cortex-A53編)
(※)A72では単純なmemset関数はmusl memset関数にほぼ勝てない(16〜22バイトのみ勝つ)が、A53では割と良い勝負(16〜22、32〜38、48〜52バイトで勝つ)をしている。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年1月11日
memsetに一番効く最適化
目次: ベンチマーク
Cortex-A72でのmemsetはO2に-ftree-vectorizeと -fpeel-loopsを足すと、O3の性能とほぼイコールになることがわかりました。

gcc -O2 -ftree-vectorize -fpeel-loops -fno-builtinの測定結果(Cortex-A72)
元の処理が非常に単純なループ処理のためか、ループ系の最適化がメチャクチャ効くっぽいです。
何が効くのか?
GCCのGIMPLEを出力させ(-fdump-tree-all)眺めてみると、
- オリジナル
- 1バイトごとにデータ処理するループが生成される。
- ベクタライズ(161t.vect)
- 16バイトごとにデータ処理するループと、1バイトごとに残りデータを処理するループに分割される。
- アンローリング(164t.cunroll, 169t.loopdone)
- 残りデータを処理するループが展開される。
こんな感じに見えます。正直言って、ループアンローリングなんて大したことないと思っていましたが、これほど効くとは思いませんでした。
メモ: 技術系の話はFacebookから転記しておくことにした。大幅に追記。
コメント一覧
- コメントはありません。
この記事にコメントする
2020年1月12日
ぼくの考えた最強のmemset
目次: ベンチマーク
NEON intrinsicを使って自分でmemsetを実装してみました。ざっくりした設計方針としては、
- NEON store (128bit) x 2で32バイトずつ書く
- 端数25〜バイトはNEON store x 2
- 端数16〜バイトはNEON store + uint64 store
相手は汎用実装ですし、Cortex-A72に特化した実装なら楽勝だろう、などと考えて始めましたが、甘かった。glibcのフルアセンブラ版はかなり手ごわいです。
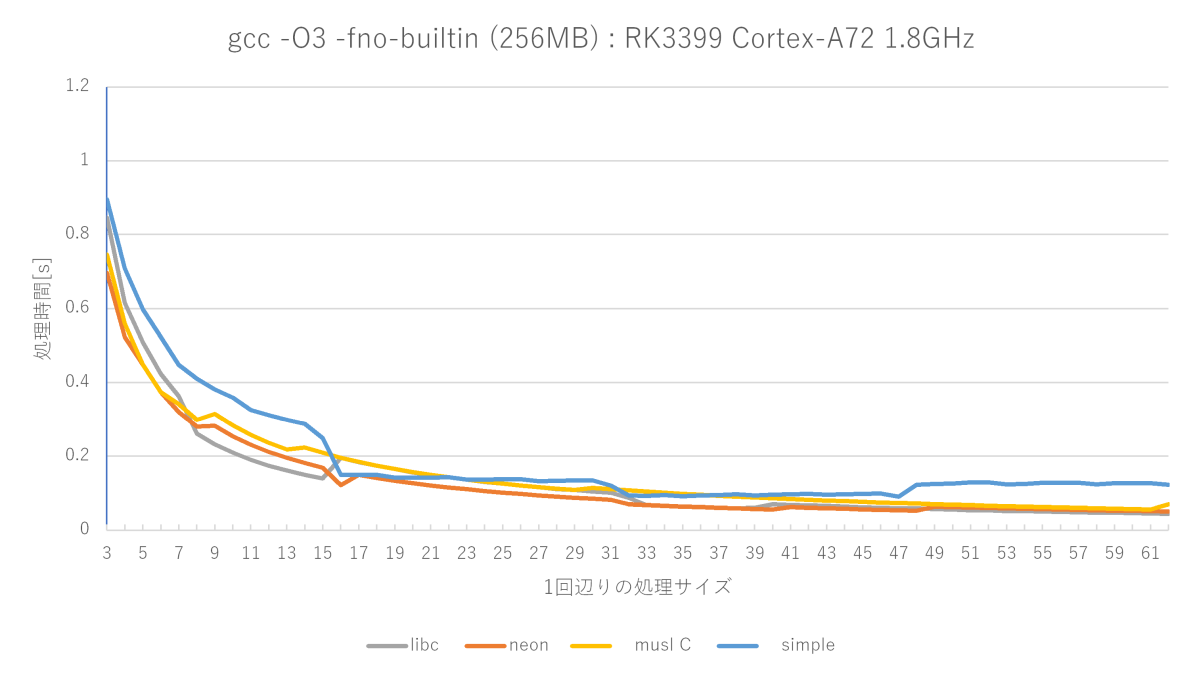
グラフの赤い線が、自作したmemsetの性能です。
最適化レベルO3のsimple memsetにはほぼ全域で勝てますが、サイズが小さいときのmuslは強い(サイズが小さい場合から判定しているから?)です。glibcのフルアセンブラもかなり強いです。測定によって勝ったり負けたりな程度です。
全然最強じゃなかった……
設計が甘すぎたことがわかったので、下記のように見直しました。
- 少ないバイト数の条件から判定
- NEON store (128bit) x 2で32バイトずつ書く
- 端数バイトはNEON store(分岐を減らした)
序盤でmusl memsetに負けていたのは、バイト数の条件判定の順序が良くなかった(大きいサイズから判定していた)ためなので、1番目で対策しています。2番目と3番目の方針は良いとも悪いとも一概に言えませんが、RK3399だとこれが一番性能が出ました。
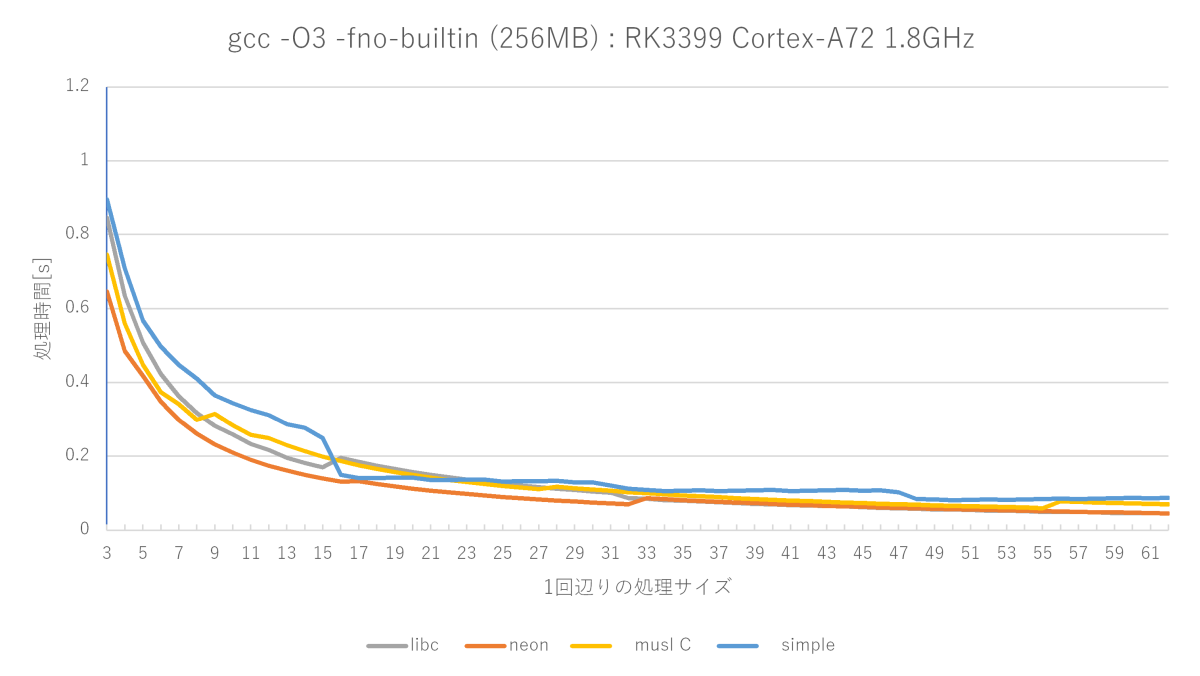
設計意図通りにmuslの序盤(特に高速な1〜8バイト付近)と、glibcフルアセンブラの序盤(1〜32バイト)には勝てたものの、glibcフルアセンブラ版は中盤以降が強く、33バイト以降は全く勝てません。
私の作ったmemsetは32バイトまでは専用処理で、33バイトからループで処理するようになるので、33バイトから性能がかなり落ちます。
おそらくglibcフルアセンブラ版も同様に16バイトから性能が落ちるので、ループ処理していると思うんですが、それ以降の巻き返しが凄くて、33バイト以降はまったく勝てないですね……。どうやってんだろうね、これ?
コンパイラが変なandとかsubを出力しているのを見つけたので、アセンブラでも実装してみましたが、性能はほぼ変わりませんでした。設計の根底が違うんでしょうね。
Cortex-A53だと全く勝ち目無し
RK3328(Cortex-A53)で測ってみると、muslには勝てますが、glibcフルアセンブラ版には勝ち目無しで、ほぼ全域に渡ってボコボコにされます。
基本設計が「余計なwriteをしてでも、とにかく速く終われ」なので、writeを正直に実行してしまうようなヘボいプロセッサになればなるほど勝ち目が薄いです。
コメント一覧
- コメントはありません。
この記事にコメントする
| < | 2019 | > | ||||
| << | < | 12 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 | - | - | - | - |
最近のコメント5件
-
 14年6月13日
14年6月13日
2048player...さん (09/26 01:04)
「最後に、この式を出すのに紙4枚(A4)も...」 -
14年6月13日
2048playerさん (09/26 01:00)
「今のところ最も簡略化した式です。\n--...」 -
14年6月13日
2048playerさん (09/16 01:00)
「返信ありがとうございます。\nコメントが...」 -
14年6月13日
すずきさん (09/12 21:19)
「コメントありがとうございます。同じ結果に...」 -
14年6月13日
2048playerさん (09/08 17:30)
「私も2048の最高スコアを求めたのですが...」
最近の記事3件
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
