2020年1月11日
memsetに一番効く最適化
目次: ベンチマーク
Cortex-A72でのmemsetはO2に-ftree-vectorizeと -fpeel-loopsを足すと、O3の性能とほぼイコールになることがわかりました。

gcc -O2 -ftree-vectorize -fpeel-loops -fno-builtinの測定結果(Cortex-A72)
元の処理が非常に単純なループ処理のためか、ループ系の最適化がメチャクチャ効くっぽいです。
何が効くのか?
GCCのGIMPLEを出力させ(-fdump-tree-all)眺めてみると、
- オリジナル
- 1バイトごとにデータ処理するループが生成される。
- ベクタライズ(161t.vect)
- 16バイトごとにデータ処理するループと、1バイトごとに残りデータを処理するループに分割される。
- アンローリング(164t.cunroll, 169t.loopdone)
- 残りデータを処理するループが展開される。
こんな感じに見えます。正直言って、ループアンローリングなんて大したことないと思っていましたが、これほど効くとは思いませんでした。
メモ: 技術系の話はFacebookから転記しておくことにした。大幅に追記。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2020年1月6日
memsetのベンチマーク(AArch64, Cortex-A53編)
目次: ベンチマーク
(参考)コード一式はGitHubに置きました(GitHubへのリンク)
AArch64その2です。Cortex-A53でmemsetをやってみました。環境はRK3328 Cotex-A53 1.4GHzです。メモリはおそらくLPDDR3-1600です。
Cortex-A72と似ている点としては、
- musl memset関数が非常に優秀
- ベクトル化は性能向上に効くが、他も有効な要素がありそう
違う点としては、
- アセンブラ実装とmusl memset関数の差が開く
- O3の最適化がかなり効く(※)
- glibc memset関数の不安定さが減る
こんなところでしょうか。A72のglibc memset関数はグラフが上がったり下がったりグチャグチャしていましたが、A53だと割と素直になっています。
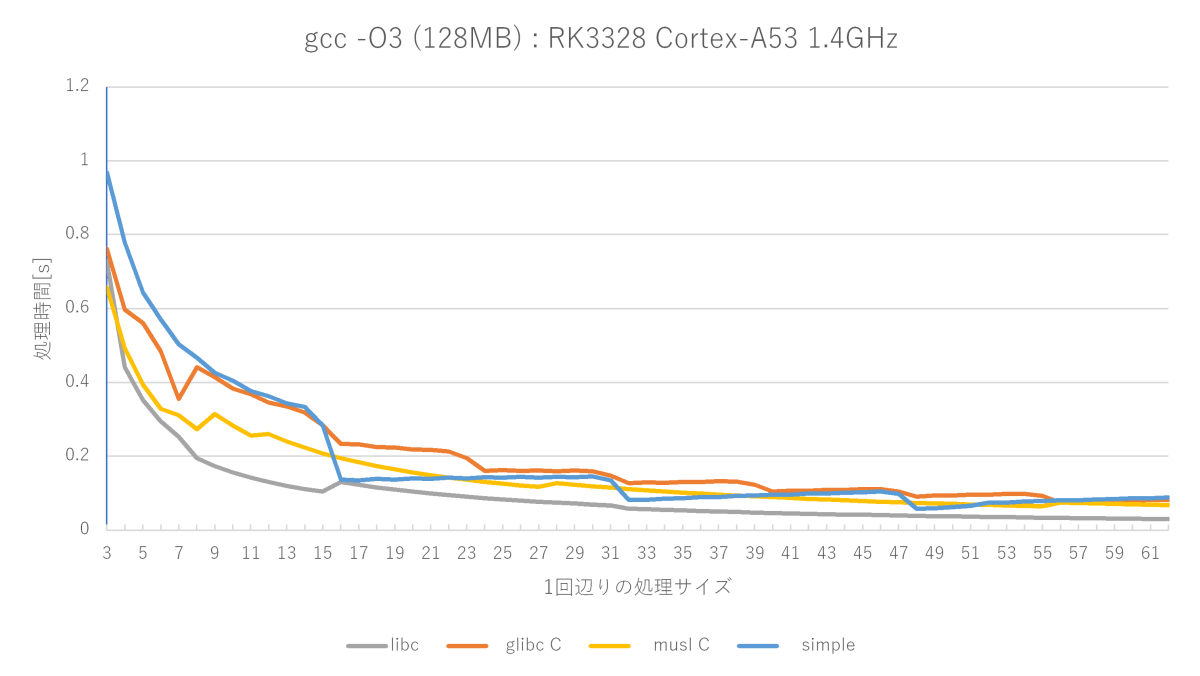
gcc -O3 -fno-builtinの測定結果(Cortex-A53編)
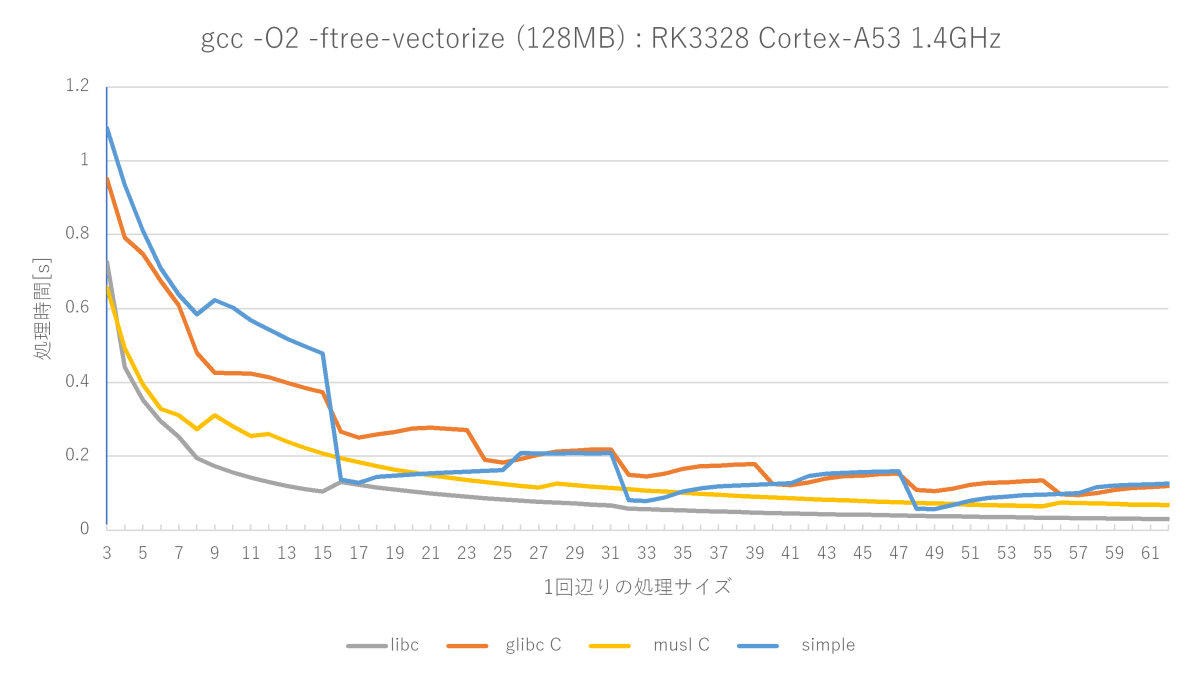
gcc -O2 -ftree-vectorize -fno-builtinの測定結果(Cortex-A53編)
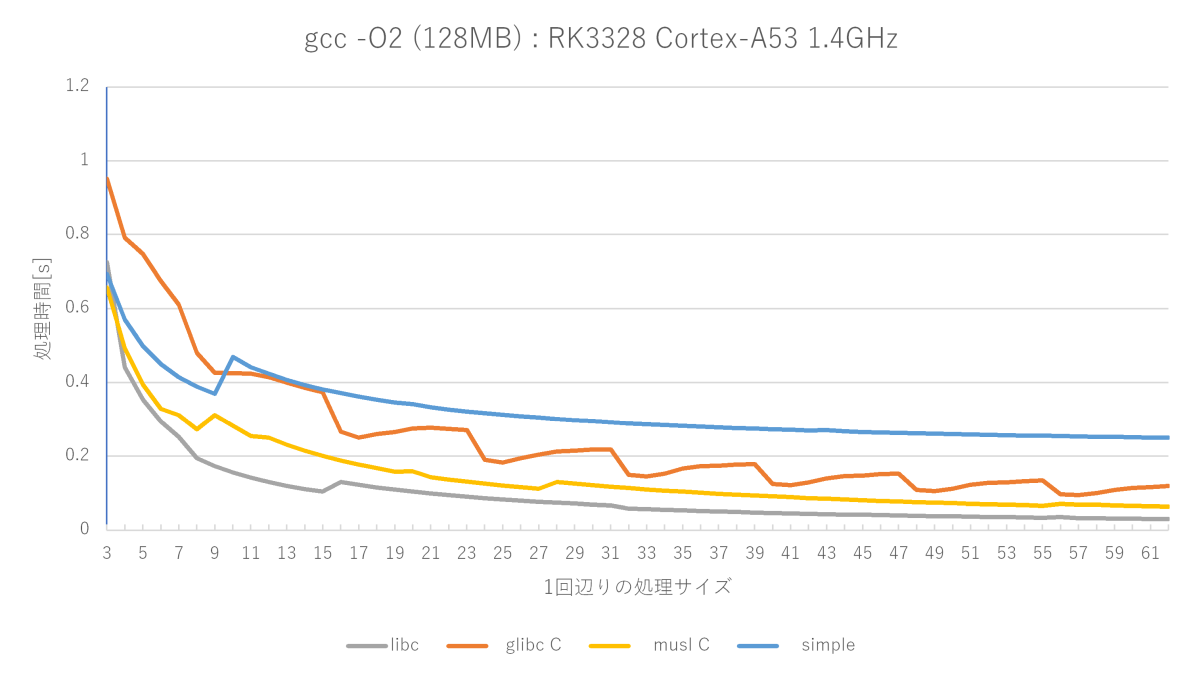
gcc -O2 -fno-builtinの測定結果(Cortex-A53編)
(※)A72では単純なmemset関数はmusl memset関数にほぼ勝てない(16〜22バイトのみ勝つ)が、A53では割と良い勝負(16〜22、32〜38、48〜52バイトで勝つ)をしている。
コメント一覧
- コメントはありません。
この記事にコメントする
| < | 2020 | > | ||||
| << | < | 01 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| - | - | - | 1 | 2 | 3 | 4 |
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 | - |
最近のコメント20件
-
 25年12月18日
25年12月18日
すずきさん (12/23 23:51)
「良く見たらksys_read()でfil...」 -
25年12月18日
すずきさん (12/23 23:15)
「ですね、まあpread+readだと話が...」 -
25年12月18日
hdkさん (12/21 08:34)
「昔試しにデバイスドライバーを作ったことが...」 -
25年11月28日
hdkさん (12/04 08:10)
「あれ、停止直前くらいの時のトルクコンバー...」 -
25年11月28日
すずきさん (12/03 11:24)
「トルクコンバーターがいてエンブレは掛かり...」 -
25年11月28日
hdkさん (12/02 08:02)
「"停止直前に急にエンブレがほぼゼロになる...」 -
25年10月6日
すずきさん (10/10 13:14)
「ですね。ccはもはやコンパイラというより...」 -
25年10月6日
hdkさん (10/10 08:27)
「ただのHello, worldでも試して...」 -
25年9月29日
すずきさん (10/03 00:29)
「なんと、メタパッケージ入れてなかったです...」 -
25年9月29日
hdkさん (10/02 06:51)
「あれ、dkmsは自動ビルドされるのが便利...」 -
20年8月24日
すずきさん (08/30 22:06)
「ですね、自分も今はPulseAudioを...」 -
20年8月24日
hdkさん (08/29 09:32)
「ALSA懐かしい... PulseAud...」 -
16年2月14日
すずきさん (08/04 01:31)
「お役に立ったようでしたら幸いです。」 -
16年2月14日
enc28j60さん (08/03 17:40)
「ちょうど詰まっていたところです。\n非常...」 -
25年7月20日
すずきさん (07/30 00:10)
「ギクシャクするのは減速時の2速シフトダウ...」 -
25年7月20日
hdkさん (07/29 07:38)
「2速発進でギクシャクするんですか? 面白...」 -
25年7月20日
すずきさん (07/28 23:16)
「なるほど。レガシィB4のATはDレンジで...」 -
25年7月20日
hdkさん (07/28 21:28)
「MT車でも1速はギクシャクするので完全に...」 -
25年7月20日
すずきさん (07/28 00:44)
「何日か乗ってみて気づいたんですが、Dレン...」 -
25年7月20日
hdkさん (07/22 22:59)
「2速発進って雪道モードっぽさがありますが...」
最近の記事3件
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
