2019年10月21日
線形探索と2分探索の話
Twitterで線形探索と2分探索の性能逆転ポイントはどこか?という話をしていて、気になったので測ってみました。
線形探索と2分探索は、要素数をNとしたとき、処理量オーダーでいうとO(N) とO(logN) となり、圧倒的に2分探索が速いです。ただし処理量オーダーによる比較は、Nが十分に大きい場合に成り立ちます。Nが極端に小さい場合は線形探索が2分探索と同等、もしくは、勝ってしまう領域があるのではないか?という話です。
結論だけ先に言えば2分探索の圧勝でした。かなりNを小さく(100程度)しないと、線形探索に勝ち目はなかったです。個人的にはN=1000〜2000程度ならば線形探索が勝つ予想をしていましたが、全くそんなことはなかったです。2分探索スゴい。
探索速度検証
検証方法ですが、線形探索(lsearch)を実装して、Cライブラリ(GNU libc 2.29)に実装されている2分探索(bsearch)と速度を比較しました。線形探索lsearchのAPIは2分探索と揃えています。
処理の概要は下記の通りです。探索の対象は同じものを使っています。
- 要素数Nの配列を作る
- 配列を乱数で埋める
- 配列をソートする(bsearchはソート済みの配列にしか使えない)
- 2分探索(bsearch)をM回実行する、時間を測る
- 線形探索(lsearch)をM回実行する、時間を測る
ソースコードは下記のとおりです。
線形探索と2分探索の速度比較プログラム
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <sys/time.h>
int comp(const void *key, const void *val)
{
int k = *(int *)key;
int v = *(int *)val;
return k - v;
}
void *lsearch(const void *key, const void *base,
size_t nmemb, size_t size,
int (*compar)(const void *, const void *))
{
void *v = (void *)base;
size_t i;
for (i = 0; i < nmemb; i++) {
if (compar(key, v) == 0)
return v;
v += size;
}
return NULL;
}
int main(int argc, char *argv[])
{
int *array, *keys;
int **fb, **fl;
size_t n, kn, i;
struct timeval start_b, end_b, ela_b;
struct timeval start_l, end_l, ela_l;
if (argc < 3) {
fprintf(stderr, "usage:\n\t%s n loop\n", argv[0]);
return -1;
}
n = atoi(argv[1]);
kn = atoi(argv[2]);
if (n == 0 || kn == 0) {
fprintf(stderr, "usage:\n\t%s n loop\n", argv[0]);
return -1;
}
srand(time(NULL));
array = (int *)malloc(n * sizeof(int));
keys = (int *)malloc(kn * sizeof(int));
fb = (int **)malloc(kn * sizeof(int *));
fl = (int **)malloc(kn * sizeof(int *));
for (i = 0; i < n; i++) {
array[i] = rand() % (int)n;
}
for (i = 0; i < kn; i++) {
keys[i] = rand() % (int)n;
}
qsort(array, n, sizeof(int), comp);
gettimeofday(&start_b, NULL);
for (i = 0; i < kn; i++) {
fb[i] = bsearch(&keys[i], array, n, sizeof(int), comp);
}
gettimeofday(&end_b, NULL);
timersub(&end_b, &start_b, &ela_b);
gettimeofday(&start_l, NULL);
for (i = 0; i < kn; i++) {
fl[i] = lsearch(&keys[i], array, n, sizeof(int), comp);
}
gettimeofday(&end_l, NULL);
timersub(&end_l, &start_l, &ela_l);
for (i = 0; i < kn; i++) {
if (fb[i] && fl[i] && *fb[i] == *fl[i])
continue;
if (fb[i] != fl[i])
printf("diff %d: key:%d, fb:%d, fl:%d\n",
(int)i, keys[i],
(fb[i]) ? *fb[i] : -1,
(fl[i]) ? *fl[i] : -1);
}
printf("n:%d, loop:%d, bin: %d.%06d[s], lin: %d.%06d[s]\n",
(int)n, (int)kn,
(int)ela_b.tv_sec, (int)ela_b.tv_usec,
(int)ela_l.tv_sec, (int)ela_l.tv_usec);
return 0;
}
コピペしていたり、エラー処理が甘かったり、適当な書き方で申し訳ないですが、性能比較が目的なのでそこは見逃していただくとして。測ってみるとこんな結果になりました。
環境はRyzen 7 2700, Debian 10 (Linux 5.2.0-3-amd64) です。コンパイラはgcc 9.2.1で、最適化レベルは -O2 です。
線形探索と2分探索の速度比較(100万回)
$ for i in 1 `seq 25 25 500`; do ./a.out $i 1000000; done n:1, loop:1000000, bin: 0.001702[s], lin: 0.001710[s] n:25, loop:1000000, bin: 0.019114[s], lin: 0.011656[s] n:50, loop:1000000, bin: 0.022469[s], lin: 0.018549[s] n:75, loop:1000000, bin: 0.026413[s], lin: 0.023774[s] n:100, loop:1000000, bin: 0.028008[s], lin: 0.028900[s] n:125, loop:1000000, bin: 0.029601[s], lin: 0.034308[s] ★この辺りで逆転される★ n:150, loop:1000000, bin: 0.030671[s], lin: 0.040280[s] n:175, loop:1000000, bin: 0.031898[s], lin: 0.045664[s] n:200, loop:1000000, bin: 0.032771[s], lin: 0.048153[s] n:225, loop:1000000, bin: 0.033985[s], lin: 0.052148[s] n:250, loop:1000000, bin: 0.034322[s], lin: 0.055871[s] n:275, loop:1000000, bin: 0.034761[s], lin: 0.059935[s] n:300, loop:1000000, bin: 0.035766[s], lin: 0.065683[s] n:325, loop:1000000, bin: 0.036407[s], lin: 0.070435[s] n:350, loop:1000000, bin: 0.037010[s], lin: 0.072971[s] n:375, loop:1000000, bin: 0.036926[s], lin: 0.077805[s] n:400, loop:1000000, bin: 0.037422[s], lin: 0.082656[s] n:425, loop:1000000, bin: 0.037844[s], lin: 0.086240[s] n:450, loop:1000000, bin: 0.038894[s], lin: 0.089354[s] n:475, loop:1000000, bin: 0.038516[s], lin: 0.093286[s] n:500, loop:1000000, bin: 0.038590[s], lin: 0.100021[s]
結果の見方ですが、最初のn: は配列の要素数です。次のloop: は何回検索するかを表しています。bin: は2分探索bsearch、lin: は線形探索lsearchを表し、それぞれloop回実行し終わるまでの時間を出しています。
線形探索と2分探索の逆転ポイントは実行するたびに割とズレますが、N=500にもなれば、もはや線形探索に勝ち目はありません。2分探索強いです。
ループ回数を増やしても大勢に影響はありませんが、ループ回数を増やすほどlsearchがわずかに有利になるようです。N=1のときlsearchが勝つことが多いので、関数の呼び出しコストが低いのかも?
個人的に予想していたN=1000〜2000のレンジでは、線形探索は桁違いに遅かった(2分探索の10倍近く時間がかかる)です。私の予想は当てにならんなあ。
コメント一覧
- コメントはありません。
 この記事にコメントする
この記事にコメントする
2019年10月20日
イコライザー
普段ヘッドフォンを使っているのですが、若干、低音が足りないなと思うことがあります。
Windows標準のBass Boostは設定項目が2つと大変シンプルでわかりやすいですが、音の歪みを防止するためなのか、Boostを有効にすると音が全体的に小さくなってしまうのが辛いところです。

最大値は24dBですが、最大値に設定しようものなら非常に音が小さくなります。良いヘッドフォンアンプを持っていればアンプ側で音量を上げれば良いですが、PCのヘッドフォン端子に直接ヘッドフォンを接続している場合は、ボリュームを最大にしても聞こえなくなる可能性があります。

これはイマイチだなあってことで、代わりを探していましたら、VLC Playerのイコライザはシンプルデザインかつ設定の幅が広くて、とても良かったです。
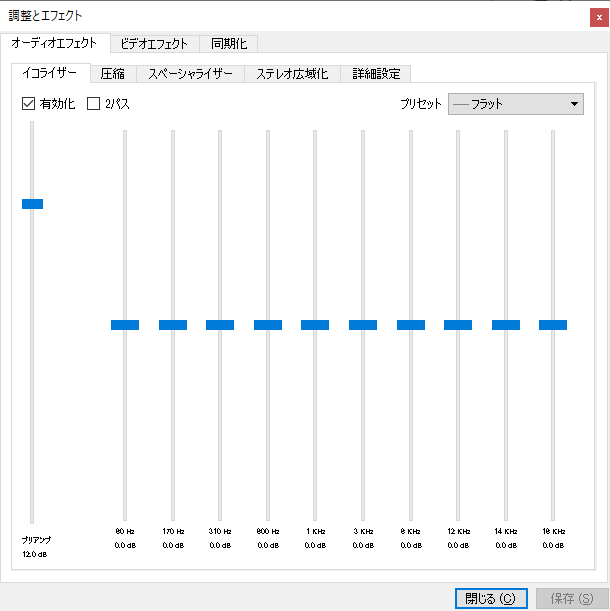
全体の音量(Preamp)と、各帯域ごとの音量を別々に調整できるので、WindowsのBass Boostに似た設定もできる(Preampを下げ、80Hz帯を上げる)し、音が歪むのもお構いなしの設定にもできます。あまりやりすぎるとバリバリ言い始めるのでほどほどに、ですけど。
コメント一覧
- コメントはありません。
この記事にコメントする
2019年10月14日
linux-nextの不思議なバージョン情報
Linuxというかlinux-nextですが、リポジトリ内のファイルをオリジナルから変更してビルドした場合、バージョン情報の最後に -dirtyが付きます。あれはどうやっているのだろう??と気になりました。
Makefileを眺めていると、scripts/setlocalversionというスクリプトでローカルバージョンを付与しているように見えます。
試しにcleanなリポジトリでscripts/setlocalversionを実行すると、-next-20191009のようなlocalversionのみ(※)が表示され、ファイルを適当に書き換えてから実行すると、-next-20191009-dirtyになりました。このスクリプトで当たりっぽいです。
もしLinux Upstreamカーネルで試す場合は、CONFIG_LOCALVERSION_AUTOをyにして、make prepareを実行する必要があります。そうしないとscripts/setlocalversionを実行しても "+" しか表示されません。
(※)この文字列はトップディレクトリのlocalversion-nextというファイルに書いてあります。
Gitの小技、リポジトリ変更を検知
スクリプトsetlocalversionを追いかけてみるとgit --no-optional-locks status -uno --porcelainで変更を検知して、-dirtyを出力するかどうか決めていました。オプション --porcelainのヘルプを見ると「スクリプトなどで処理しやすい形式でstatusを出力する」とのことです。へえー、こんなのあるんだ。初めて知りました。
オプション --no-optional-locksはロックを取らずに実行するという意味です。ヘルプ曰く、バックグラウンドでstatusを実行する際に、他のgit statusプロセスと衝突するので、指定した方が良いとのこと。手動で使うことはなさそうだし、気にしなくて良いでしょう。
オプション-unoは --untracked-files=noの省略形です。効果は実際に見た方が早いです。以下をご覧ください。
Gitリポジトリに変更を加える
#### scripts/setlocalversionを書き換え $ vim scripts/setlocalversion #### 未追跡ファイルaaaを作成 $ touch aaa
上記の変更を加えたうえで、オプション -unoなし、オプション -unoありで、それぞれ実行してみます。
Gitリポジトリに変更が生じているか取得する(-unoなし、あり)
$ git status --porcelain M scripts/setlocalversion ?? aaa $ git status -uno --porcelain 下記と同じ $ git status --untracked-files=no --porcelain M scripts/setlocalversion
見た目で明らかだとは思いますが、オプション -unoが指定されていない場合は、未追跡のファイルaaaも表示されますが、-unoを指定すると未追跡のファイルは無視します。
スクリプト内でGitリポジトリが変更されたか?されていないか?を判定する必要は、普通の人はほぼ無いと思うんですけど……、もし必要が生じたら、sedとかgrepとかでゴチャゴチャやらずに、オプション --porcelainを使いましょう。
コメント一覧
- コメントはありません。
この記事にコメントする
2019年10月13日
Gitの小技、コミットID取得
最近、会社でCI/CDで自動化のマネごとを始めました。といっても大したことはなくて、ビルドしてDebianやRPMパッケージを作って、Webサーバーにぶっこむだけです。
Nightlyビルドのパッケージを作成する際に、パッケージ名の最後にGitのコミットIDを付加しようと思ったのですが、方法が分かりません。調べてみるとrev-parseというコマンドを使うそうです。知らなかった。
GitのコミットID(全体、短縮)を取得する
$ git rev-parse HEAD 5ab7d0ae0c170fc0409d564fe945aac5ce54f86c $ git rev-parse --short HEAD 5ab7d0ae0c1
ID全部だと長すぎるため --shortオプションを使うとより良いです。
コメント一覧
- コメントはありません。
この記事にコメントする
2019年10月12日
台風19号
あの台風15号(Faxai)(2019年9月8日の日記参照)を超える、かつてない規模の台風19号(Hagibis)が来るということで、窓にガラス飛散防止でダンボールを貼ってみたり、食料、水を買い込んで備えていました。
都内だと多摩川沿いの一部堤防のない地域が水浸し、東日本だと長野、宮城が洪水で大変なことになっているそうで、東京の治水事業には感謝しかありません。

我が家からはやや遠いですが、最寄りの大きな川といえば多摩川です。水位が大変なことになっていて、思わずスクリーンショットを撮ってしまいました……。
家
我が家は北と東に窓がありまして、台風15号のときは北からガンガン風と雨が吹き付けていたため、あまりの風圧に、雨が窓サッシの隙間から侵入していました。壁に飛来物が当たり、ものすごい音もしていました(窓の真横に当たり、窓にはギリギリ当たらず本当に幸運だった)。今回はどうやら西、ないし、南から吹き付けていたようで、15号のときほど被害はありませんでした。
今回は全体的に幸運でしたが、災害への備えは日頃からやっておいて損はないですね。
家財
家の外にある家財は車くらいしかないので、台風が過ぎた後に見に行ってみましたが、特に飛来物が当たった形跡もなく、何ともなかったです。良かった良かった。
コメント一覧
- コメントはありません。
この記事にコメントする
| < | 2019 | > | ||||
| << | < | 10 | > | >> | ||
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
| - | - | 1 | 2 | 3 | 4 | 5 |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 | - | - |
最近のコメント5件
最近の記事20件
-
 23年4月10日
23年4月10日
すずき (03/15 18:17)
「[Linux - まとめリンク] 目次: Linux関係の深いまとめリンク。目次: RISC-V目次: ROCK64/ROCK...」 -
25年3月7日
すずき (03/15 18:16)
「[wchanとptrace_may_access()] 目次: Linux以前、LinuxのI/O統計情報が読めないプロセス(...」 -
25年3月3日
すずき (03/15 00:32)
「[健康保険料率] 給与明細を見ていて、なんか健康保険料がやたら高くないか……?と気になりました。要...」 -
22年11月14日
すずき (03/14 23:35)
「[電池 - まとめリンク] 目次: 電池ニッケル水素電池(Ni-MH)やリチウムイオン電池などの二次電池。ニッケル水素電池の使...」 -
25年3月14日
すずき (03/14 23:34)
「[ナトリウムイオン電池] 目次: 電池エレコムからナトリウムイオン電池を使用したモバイルバッテリーが発売されていたので予約しま...」 -
25年3月11日
すずき (03/12 21:15)
「[首都高バトルSteam版、大体クリア] 目次: ゲームやっと首都高バトル(Steam版)のWondererを全員倒し、ミスタ...」 -
21年12月28日
すずき (03/12 21:14)
「[ゲーム - まとめリンク] 目次: ゲーム一覧が欲しくなったので作りました。Wizardry(囚われし亡霊の街)敵が強すぎる...」 -
25年3月1日
すずき (03/12 00:21)
「[レガシィの半年点検(2025)] 目次: 車先週、ディーラーに半年点検に持っていったら毎度おなじみのバッテリーがイカレていて...」 -
23年5月15日
すずき (03/12 00:18)
「[車 - まとめリンク] 目次: 車三菱FTOの話。群馬県へのドライブ1群馬県へのドライブ2将来車を買い替えるとしたら?FTO...」 -
25年3月10日
すずき (03/12 00:06)
「[誕生日] 42歳になりました。昨年の日記(2024年3月10日の日記参照)を見ると、リモートワークの話をしていました。最近は...」 -
25年2月19日
すずき (03/01 15:49)
「[LinuxのI/O統計情報が読めないプロセスの謎を追う] 目次: Linux前回はsystemd --userの/proc/...」 -
25年2月18日
すずき (02/25 01:12)
「[LinuxのI/O統計情報が読めないプロセスが居る] 目次: LinuxLinuxのI/O統計情報(/proc/[pid]/...」 -
23年4月28日
すずき (02/23 00:31)
「[Linuxの/dev/zeroの実装] 目次: LinuxTwitterで/dev/zeroの話をしている人が居て、そういえ...」 -
25年2月17日
すずき (02/23 00:29)
「[LinuxのI/O統計情報] 目次: LinuxLinuxは各プロセスがどれくらいI/Oを行ったか記録していて、procファ...」 -
25年1月23日
すずき (02/20 00:27)
「[首都高バトルSteam版] 目次: ゲーム首都高バトルSteam版を買いました。首都高バトルシリーズは2006年の「首都高バ...」 -
25年2月4日
すずき (02/16 23:34)
「[次のWindows 11でE480が見捨てられそう] 今使っているノートPC(Lenovo ThinkPad E480)のC...」 -
25年1月30日
すずき (02/16 22:10)
「[Thunderbirdの消せないツールバー] Thunderbird 115.0(Supernova, 2023/07/11...」 -
25年2月3日
すずき (02/16 18:37)
「[不思議なChromeの広告] Google ChromeでYahoo!を見ているとたまにChromeの広告が表示されます。C...」 -
25年1月27日
すずき (02/16 16:37)
「[Ansibleのencrypted variablesをdecryptする] Ansibleのencrypt_stringで...」 -
21年5月22日
すずき (02/12 00:33)
「[ベンチマーク - まとめリンク] 目次: ベンチマーク一覧が欲しくなったので作りました。最速のyes不安定なyesyesの高...」
こんてんつ
wiki Linux JM Java API過去の日記
2002年 2003年 2004年 2005年 2006年 2007年 2008年 2009年 2010年 2011年 2012年 2013年 2014年 2015年 2016年 2017年 2018年 2019年 2020年 2021年 2022年 2023年 2024年 2025年 過去日記についてその他の情報
アクセス統計 サーバ一覧 サイトの情報
合計:
本日:
